 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking
Paper and Code
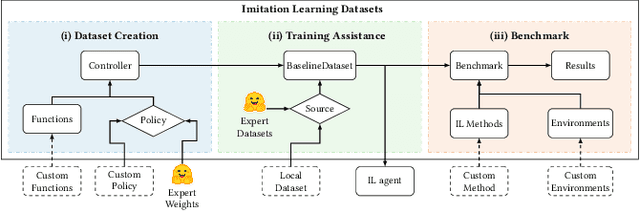
Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video