 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Accuracy and Bias in Face Recognition Trained with Synthetic Data
Jul 28, 2025Synthetic data has emerged as a promising alternative for training face recognition (FR) models, offering advantages in scalability, privacy compliance, and potential for bias mitigation. However, critical questions remain on whether both high accuracy and fairness can be achieved with synthetic data. In this work, we evaluate the impact of synthetic data on bias and performance of FR systems. We generate balanced face dataset, FairFaceGen, using two state of the art text-to-image generators, Flux.1-dev and Stable Diffusion v3.5 (SD35), and combine them with several identity augmentation methods, including Arc2Face and four IP-Adapters. By maintaining equal identity count across synthetic and real datasets, we ensure fair comparisons when evaluating FR performance on standard (LFW, AgeDB-30, etc.) and challenging IJB-B/C benchmarks and FR bias on Racial Faces in-the-Wild (RFW) dataset. Our results demonstrate that although synthetic data still lags behind the real datasets in the generalization on IJB-B/C, demographically balanced synthetic datasets, especially those generated with SD35, show potential for bias mitigation. We also observe that the number and quality of intra-class augmentations significantly affect FR accuracy and fairness. These findings provide practical guidelines for constructing fairer FR systems using synthetic data.
FantasyID: A dataset for detecting digital manipulations of ID-documents
Jul 28, 2025Advancements in image generation led to the availability of easy-to-use tools for malicious actors to create forged images. These tools pose a serious threat to the widespread Know Your Customer (KYC) applications, requiring robust systems for detection of the forged Identity Documents (IDs). To facilitate the development of the detection algorithms, in this paper, we propose a novel publicly available (including commercial use) dataset, FantasyID, which mimics real-world IDs but without tampering with legal documents and, compared to previous public datasets, it does not contain generated faces or specimen watermarks. FantasyID contains ID cards with diverse design styles, languages, and faces of real people. To simulate a realistic KYC scenario, the cards from FantasyID were printed and captured with three different devices, constituting the bonafide class. We have emulated digital forgery/injection attacks that could be performed by a malicious actor to tamper the IDs using the existing generative tools. The current state-of-the-art forgery detection algorithms, such as TruFor, MMFusion, UniFD, and FatFormer, are challenged by FantasyID dataset. It especially evident, in the evaluation conditions close to practical, with the operational threshold set on validation set so that false positive rate is at 10%, leading to false negative rates close to 50% across the board on the test set. The evaluation experiments demonstrate that FantasyID dataset is complex enough to be used as an evaluation benchmark for detection algorithms.
Score Normalization for Demographic Fairness in Face Recognition
Jul 19, 2024



Fair biometric algorithms have similar verification performance across different demographic groups given a single decision threshold. Unfortunately, for state-of-the-art face recognition networks, score distributions differ between demographics. Contrary to work that tries to align those distributions by extra training or fine-tuning, we solely focus on score post-processing methods. As proved, well-known sample-centered score normalization techniques, Z-norm and T-norm, do not improve fairness for high-security operating points. Thus, we extend the standard Z/T-norm to integrate demographic information in normalization. Additionally, we investigate several possibilities to incorporate cohort similarities for both genuine and impostor pairs per demographic to improve fairness across different operating points. We run experiments on two datasets with different demographics (gender and ethnicity) and show that our techniques generally improve the overall fairness of five state-of-the-art pre-trained face recognition networks, without downgrading verification performance. We also indicate that an equal contribution of False Match Rate (FMR) and False Non-Match Rate (FNMR) in fairness evaluation is required for the highest gains. Code and protocols are available.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Toward responsible face datasets: modeling the distribution of a disentangled latent space for sampling face images from demographic groups
Sep 15, 2023



Recently, it has been exposed that some modern facial recognition systems could discriminate specific demographic groups and may lead to unfair attention with respect to various facial attributes such as gender and origin. The main reason are the biases inside datasets, unbalanced demographics, used to train theses models. Unfortunately, collecting a large-scale balanced dataset with respect to various demographics is impracticable. In this paper, we investigate as an alternative the generation of a balanced and possibly bias-free synthetic dataset that could be used to train, to regularize or to evaluate deep learning-based facial recognition models. We propose to use a simple method for modeling and sampling a disentangled projection of a StyleGAN latent space to generate any combination of demographic groups (e.g. $hispanic-female$). Our experiments show that we can synthesis any combination of demographic groups effectively and the identities are different from the original training dataset. We also released the source code.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
EdgeFace: Efficient Face Recognition Model for Edge Devices
Jul 04, 2023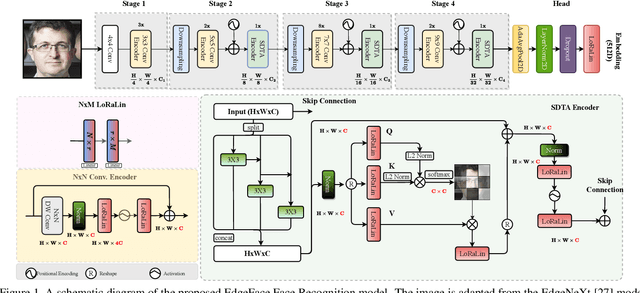



In this paper, we present EdgeFace, a lightweight and efficient face recognition network inspired by the hybrid architecture of EdgeNeXt. By effectively combining the strengths of both CNN and Transformer models, and a low rank linear layer, EdgeFace achieves excellent face recognition performance optimized for edge devices. The proposed EdgeFace network not only maintains low computational costs and compact storage, but also achieves high face recognition accuracy, making it suitable for deployment on edge devices. Extensive experiments on challenging benchmark face datasets demonstrate the effectiveness and efficiency of EdgeFace in comparison to state-of-the-art lightweight models and deep face recognition models. Our EdgeFace model with 1.77M parameters achieves state of the art results on LFW (99.73%), IJB-B (92.67%), and IJB-C (94.85%), outperforming other efficient models with larger computational complexities. The code to replicate the experiments will be made available publicly.