 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemographic Fairness in Multimodal LLMs: A Benchmark of Gender and Ethnicity Bias in Face Verification
Mar 26, 2026Multimodal Large Language Models (MLLMs) have recently been explored as face verification systems that determine whether two face images are of the same person. Unlike dedicated face recognition systems, MLLMs approach this task through visual prompting and rely on general visual and reasoning abilities. However, the demographic fairness of these models remains largely unexplored. In this paper, we present a benchmarking study that evaluates nine open-source MLLMs from six model families, ranging from 2B to 8B parameters, on the IJB-C and RFW face verification protocols across four ethnicity groups and two gender groups. We measure verification accuracy with the Equal Error Rate and True Match Rate at multiple operating points per demographic group, and we quantify demographic disparity with four FMR-based fairness metrics. Our results show that FaceLLM-8B, the only face-specialised model in our study, substantially outperforms general-purpose MLLMs on both benchmarks. The bias patterns we observe differ from those commonly reported for traditional face recognition, with different groups being most affected depending on the benchmark and the model. We also note that the most accurate models are not necessarily the fairest and that models with poor overall accuracy can appear fair simply because they produce uniformly high error rates across all demographic groups.
Exploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Jan 15, 2025
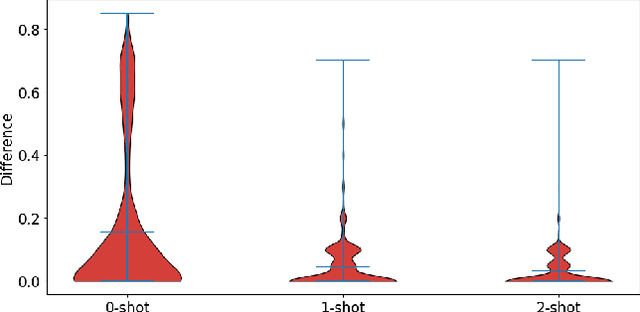

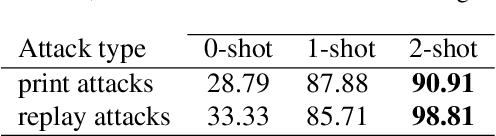
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model's performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o's promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
HyperFace: Generating Synthetic Face Recognition Datasets by Exploring Face Embedding Hypersphere
Nov 13, 2024Face recognition datasets are often collected by crawling Internet and without individuals' consents, raising ethical and privacy concerns. Generating synthetic datasets for training face recognition models has emerged as a promising alternative. However, the generation of synthetic datasets remains challenging as it entails adequate inter-class and intra-class variations. While advances in generative models have made it easier to increase intra-class variations in face datasets (such as pose, illumination, etc.), generating sufficient inter-class variation is still a difficult task. In this paper, we formulate the dataset generation as a packing problem on the embedding space (represented on a hypersphere) of a face recognition model and propose a new synthetic dataset generation approach, called HyperFace. We formalize our packing problem as an optimization problem and solve it with a gradient descent-based approach. Then, we use a conditional face generator model to synthesize face images from the optimized embeddings. We use our generated datasets to train face recognition models and evaluate the trained models on several benchmarking real datasets. Our experimental results show that models trained with HyperFace achieve state-of-the-art performance in training face recognition using synthetic datasets.
Face Reconstruction from Face Embeddings using Adapter to a Face Foundation Model
Nov 06, 2024



Face recognition systems extract embedding vectors from face images and use these embeddings to verify or identify individuals. Face reconstruction attack (also known as template inversion) refers to reconstructing face images from face embeddings and using the reconstructed face image to enter a face recognition system. In this paper, we propose to use a face foundation model to reconstruct face images from the embeddings of a blackbox face recognition model. The foundation model is trained with 42M images to generate face images from the facial embeddings of a fixed face recognition model. We propose to use an adapter to translate target embeddings into the embedding space of the foundation model. The generated images are evaluated on different face recognition models and different datasets, demonstrating the effectiveness of our method to translate embeddings of different face recognition models. We also evaluate the transferability of reconstructed face images when attacking different face recognition models. Our experimental results show that our reconstructed face images outperform previous reconstruction attacks against face recognition models.
Unveiling Synthetic Faces: How Synthetic Datasets Can Expose Real Identities
Oct 31, 2024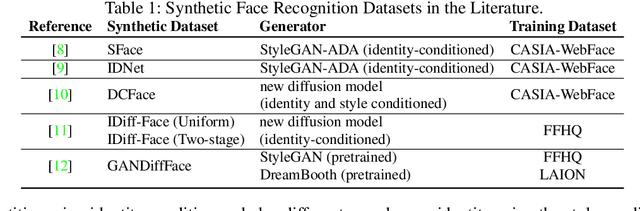



Synthetic data generation is gaining increasing popularity in different computer vision applications. Existing state-of-the-art face recognition models are trained using large-scale face datasets, which are crawled from the Internet and raise privacy and ethical concerns. To address such concerns, several works have proposed generating synthetic face datasets to train face recognition models. However, these methods depend on generative models, which are trained on real face images. In this work, we design a simple yet effective membership inference attack to systematically study if any of the existing synthetic face recognition datasets leak any information from the real data used to train the generator model. We provide an extensive study on 6 state-of-the-art synthetic face recognition datasets, and show that in all these synthetic datasets, several samples from the original real dataset are leaked. To our knowledge, this paper is the first work which shows the leakage from training data of generator models into the generated synthetic face recognition datasets. Our study demonstrates privacy pitfalls in synthetic face recognition datasets and paves the way for future studies on generating responsible synthetic face datasets.
Synthetic Face Datasets Generation via Latent Space Exploration from Brownian Identity Diffusion
Apr 30, 2024
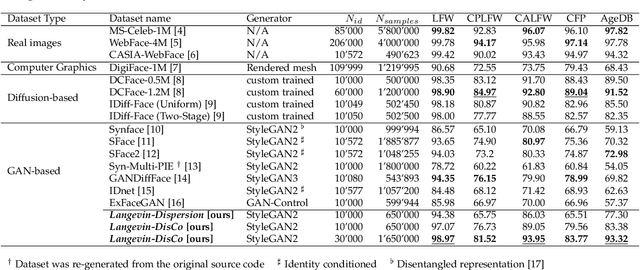
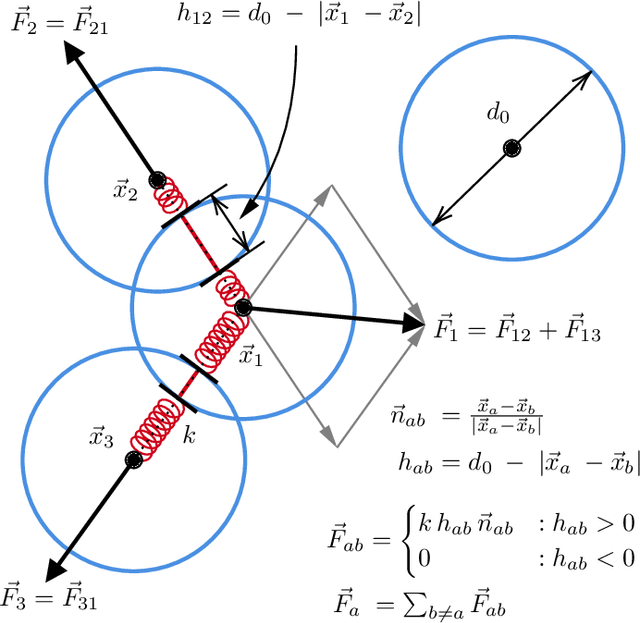

Face Recognition (FR) models are trained on large-scale datasets, which have privacy and ethical concerns. Lately, the use of synthetic data to complement or replace genuine data for the training of FR models has been proposed. While promising results have been obtained, it still remains unclear if generative models can yield diverse enough data for such tasks. In this work, we introduce a new method, inspired by the physical motion of soft particles subjected to stochastic Brownian forces, allowing us to sample identities distributions in a latent space under various constraints. With this in hands, we generate several face datasets and benchmark them by training FR models, showing that data generated with our method exceeds the performance of previously GAN-based datasets and achieves competitive performance with state-of-the-art diffusion-based synthetic datasets. We also show that this method can be used to mitigate leakage from the generator's training set and explore the ability of generative models to generate data beyond it.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities
Mar 05, 2024

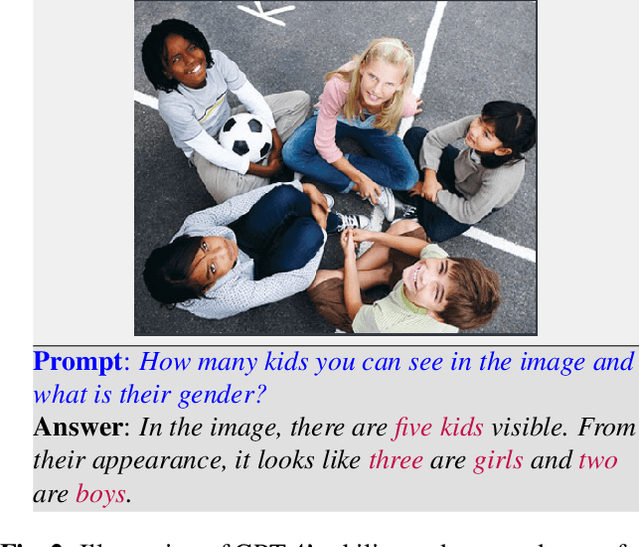

This paper explores the application of large language models (LLMs), like ChatGPT, for biometric tasks. We specifically examine the capabilities of ChatGPT in performing biometric-related tasks, with an emphasis on face recognition, gender detection, and age estimation. Since biometrics are considered as sensitive information, ChatGPT avoids answering direct prompts, and thus we crafted a prompting strategy to bypass its safeguard and evaluate the capabilities for biometrics tasks. Our study reveals that ChatGPT recognizes facial identities and differentiates between two facial images with considerable accuracy. Additionally, experimental results demonstrate remarkable performance in gender detection and reasonable accuracy for the age estimation tasks. Our findings shed light on the promising potentials in the application of LLMs and foundation models for biometrics.