 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities
Mar 05, 2024

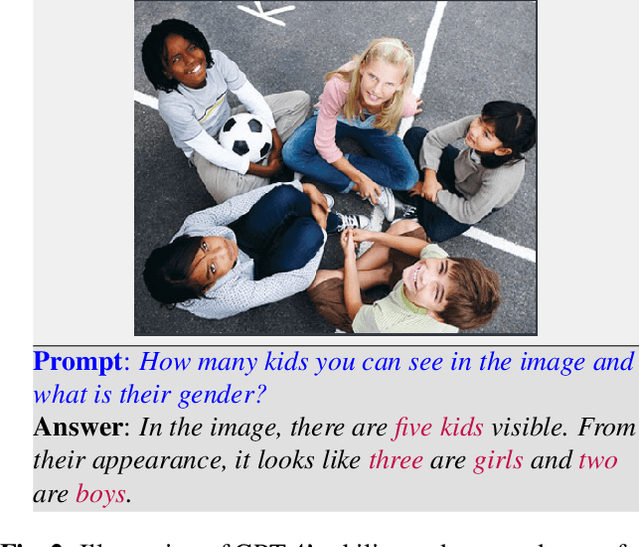

This paper explores the application of large language models (LLMs), like ChatGPT, for biometric tasks. We specifically examine the capabilities of ChatGPT in performing biometric-related tasks, with an emphasis on face recognition, gender detection, and age estimation. Since biometrics are considered as sensitive information, ChatGPT avoids answering direct prompts, and thus we crafted a prompting strategy to bypass its safeguard and evaluate the capabilities for biometrics tasks. Our study reveals that ChatGPT recognizes facial identities and differentiates between two facial images with considerable accuracy. Additionally, experimental results demonstrate remarkable performance in gender detection and reasonable accuracy for the age estimation tasks. Our findings shed light on the promising potentials in the application of LLMs and foundation models for biometrics.
Lightweight Face Recognition: An Improved MobileFaceNet Model
Nov 26, 2023



This paper presents an extensive exploration and comparative analysis of lightweight face recognition (FR) models, specifically focusing on MobileFaceNet and its modified variant, MMobileFaceNet. The need for efficient FR models on devices with limited computational resources has led to the development of models with reduced memory footprints and computational demands without sacrificing accuracy. Our research delves into the impact of dataset selection, model architecture, and optimization algorithms on the performance of FR models. We highlight our participation in the EFaR-2023 competition, where our models showcased exceptional performance, particularly in categories restricted by the number of parameters. By employing a subset of the Webface42M dataset and integrating sharpness-aware minimization (SAM) optimization, we achieved significant improvements in accuracy across various benchmarks, including those that test for cross-pose, cross-age, and cross-ethnicity performance. The results underscore the efficacy of our approach in crafting models that are not only computationally efficient but also maintain high accuracy in diverse conditions.
Gene selection from microarray expression data: A Multi-objective PSO with adaptive K-nearest neighborhood
May 27, 2022

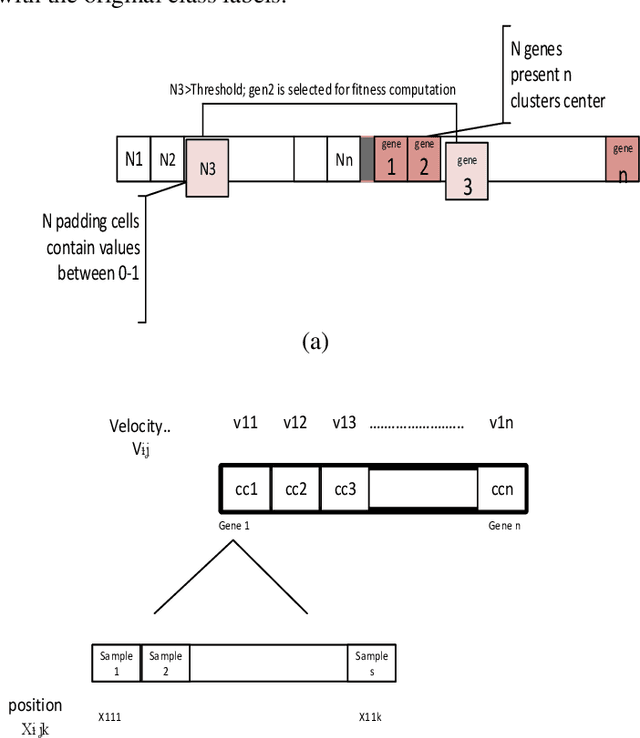
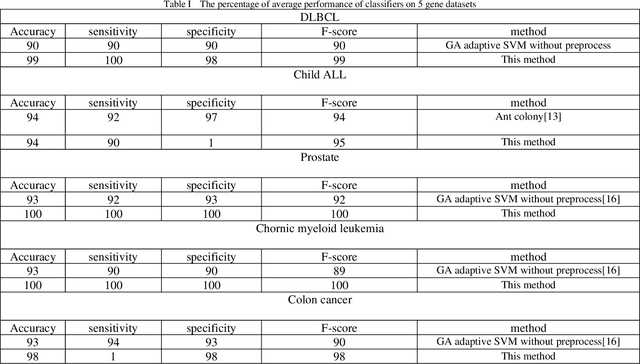
Cancer detection is one of the key research topics in the medical field. Accurate detection of different cancer types is valuable in providing better treatment facilities and risk minimization for patients. This paper deals with the classification problem of human cancer diseases by using gene expression data. It is presented a new methodology to analyze microarray datasets and efficiently classify cancer diseases. The new method first employs Signal to Noise Ratio (SNR) to find a list of a small subset of non-redundant genes. Then, after normalization, it is used Multi-Objective Particle Swarm Optimization (MOPSO) for feature selection and employed Adaptive K-Nearest Neighborhood (KNN) for cancer disease classification. This method improves the classification accuracy of cancer classification by reducing the number of features. The proposed methodology is evaluated by classifying cancer diseases in five cancer datasets. The results are compared with the most recent approaches, which increases the classification accuracy in each dataset.