 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification
Paper and Code
Sep 03, 2019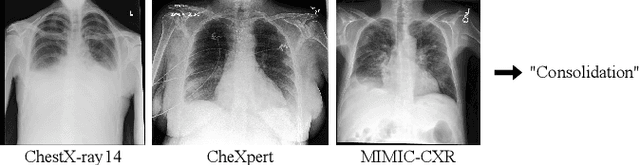

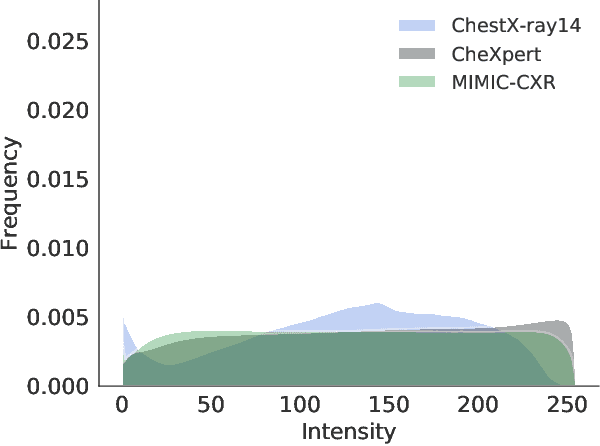
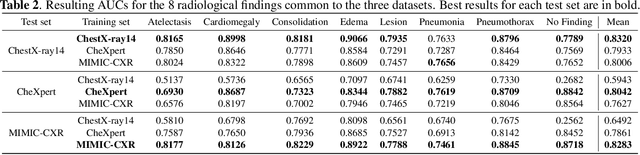
While deep learning models become more widespread, their ability to handle unseen data and generalize for any scenario is yet to be challenged. In medical imaging, there is a high heterogeneity of distributions among images based on the equipment that generate them and their parametrization. This heterogeneity triggers a common issue in machine learning called domain shift, which represents the difference between the training data distribution and the distribution of where a model is employed. A high domain shift tends to implicate in a poor performance from models. In this work, we evaluate the extent of domain shift on three of the largest datasets of chest radiographs. We show how training and testing with different datasets (e.g. training in ChestX-ray14 and testing in CheXpert) drastically affects model performance, posing a big question over the reliability of deep learning models.