 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024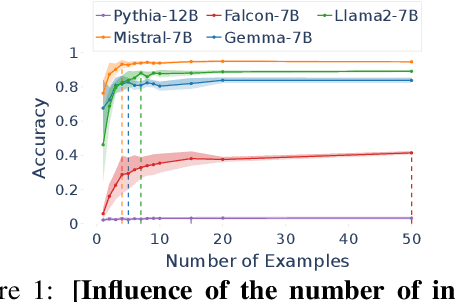
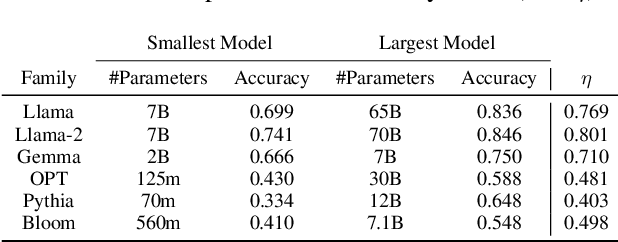
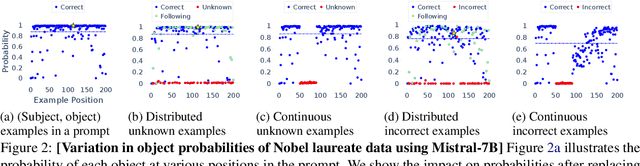
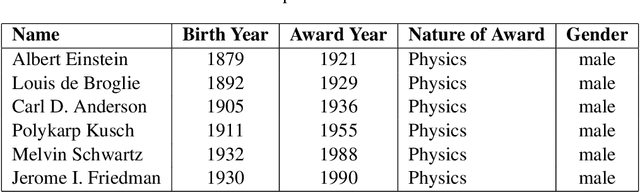
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
Pointwise Representational Similarity
May 30, 2023With the increasing reliance on deep neural networks, it is important to develop ways to better understand their learned representations. Representation similarity measures have emerged as a popular tool for examining learned representations However, existing measures only provide aggregate estimates of similarity at a global level, i.e. over a set of representations for N input examples. As such, these measures are not well-suited for investigating representations at a local level, i.e. representations of a single input example. Local similarity measures are needed, for instance, to understand which individual input representations are affected by training interventions to models (e.g. to be more fair and unbiased) or are at greater risk of being misclassified. In this work, we fill in this gap and propose Pointwise Normalized Kernel Alignment (PNKA), a measure that quantifies how similarly an individual input is represented in two representation spaces. Intuitively, PNKA compares the similarity of an input's neighborhoods across both spaces. Using our measure, we are able to analyze properties of learned representations at a finer granularity than what was previously possible. Concretely, we show how PNKA can be leveraged to develop a deeper understanding of (a) the input examples that are likely to be misclassified, (b) the concepts encoded by (individual) neurons in a layer, and (c) the effects of fairness interventions on learned representations.
Measuring Representational Robustness of Neural Networks Through Shared Invariances
Jun 23, 2022
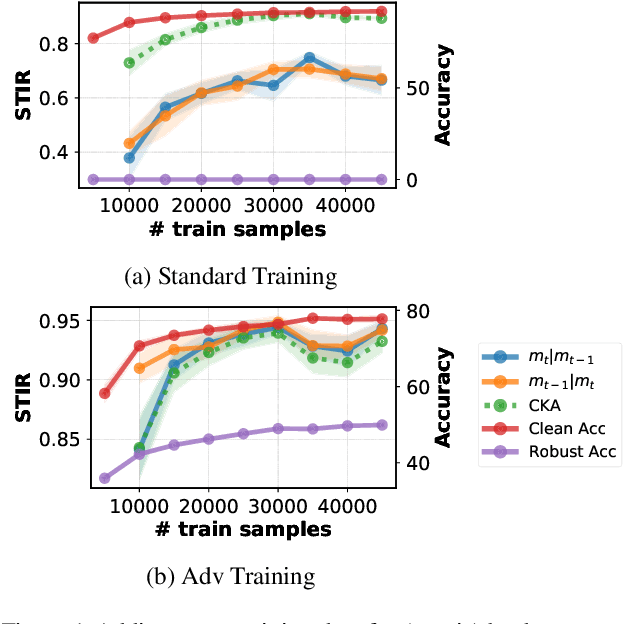

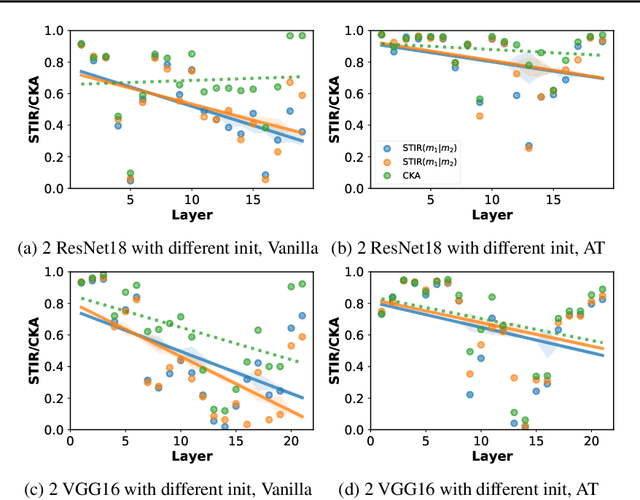
A major challenge in studying robustness in deep learning is defining the set of ``meaningless'' perturbations to which a given Neural Network (NN) should be invariant. Most work on robustness implicitly uses a human as the reference model to define such perturbations. Our work offers a new view on robustness by using another reference NN to define the set of perturbations a given NN should be invariant to, thus generalizing the reliance on a reference ``human NN'' to any NN. This makes measuring robustness equivalent to measuring the extent to which two NNs share invariances, for which we propose a measure called STIR. STIR re-purposes existing representation similarity measures to make them suitable for measuring shared invariances. Using our measure, we are able to gain insights into how shared invariances vary with changes in weight initialization, architecture, loss functions, and training dataset. Our implementation is available at: \url{https://github.com/nvedant07/STIR}.
Mitigating Bias in Facial Analysis Systems by Incorporating Label Diversity
Apr 13, 2022
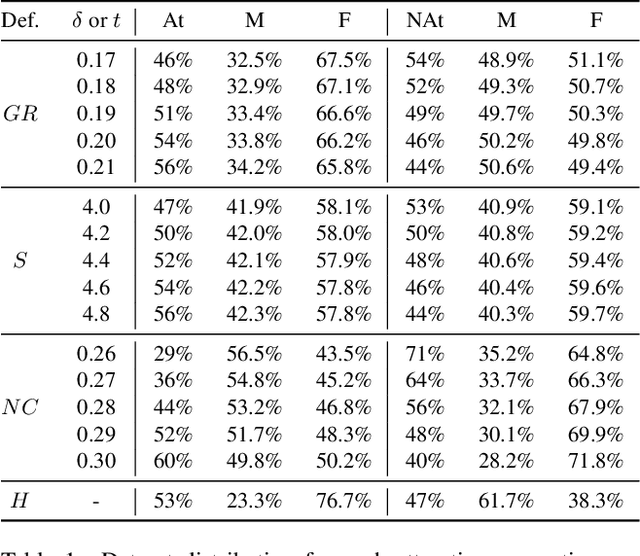
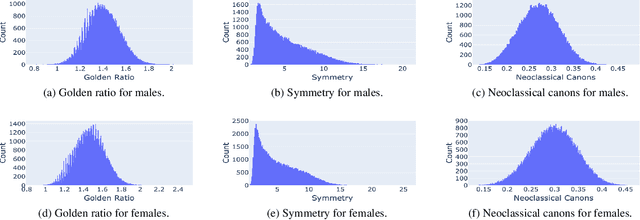
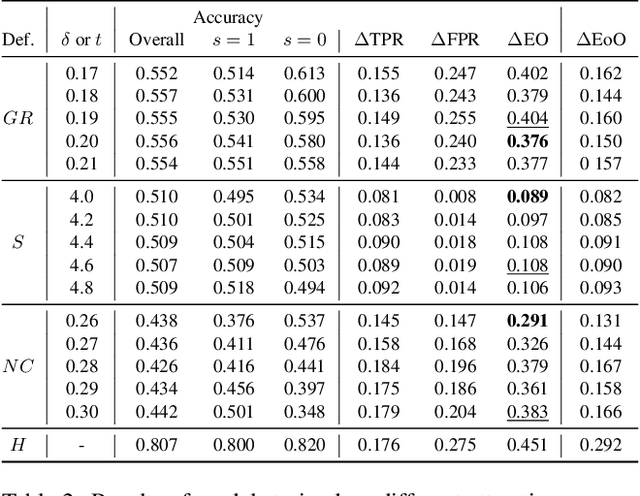
Facial analysis models are increasingly applied in real-world applications that have significant impact on peoples' lives. However, as previously shown, models that automatically classify facial attributes might exhibit algorithmic discrimination behavior with respect to protected groups, potentially posing negative impacts on individuals and society. It is therefore critical to develop techniques that can mitigate unintended biases in facial classifiers. Hence, in this work, we introduce a novel learning method that combines both subjective human-based labels and objective annotations based on mathematical definitions of facial traits. Specifically, we generate new objective annotations from a large-scale human-annotated dataset, each capturing a different perspective of the analyzed facial trait. We then propose an ensemble learning method, which combines individual models trained on different types of annotations. We provide an in-depth analysis of the annotation procedure as well as the dataset distribution. Moreover, we empirically demonstrate that, by incorporating label diversity, and without additional synthetic images, our method successfully mitigates unintended biases, while maintaining significant accuracy on the downstream task.
Exploring Alignment of Representations with Human Perception
Nov 29, 2021
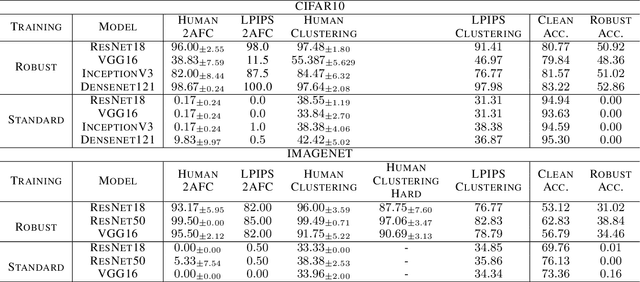


We argue that a valuable perspective on when a model learns \textit{good} representations is that inputs that are mapped to similar representations by the model should be perceived similarly by humans. We use \textit{representation inversion} to generate multiple inputs that map to the same model representation, then quantify the perceptual similarity of these inputs via human surveys. Our approach yields a measure of the extent to which a model is aligned with human perception. Using this measure of alignment, we evaluate models trained with various learning paradigms (\eg~supervised and self-supervised learning) and different training losses (standard and robust training). Our results suggest that the alignment of representations with human perception provides useful additional insights into the qualities of a model. For example, we find that alignment with human perception can be used as a measure of trust in a model's prediction on inputs where different models have conflicting outputs. We also find that various properties of a model like its architecture, training paradigm, training loss, and data augmentation play a significant role in learning representations that are aligned with human perception.
Component Analysis for Visual Question Answering Architectures
Feb 12, 2020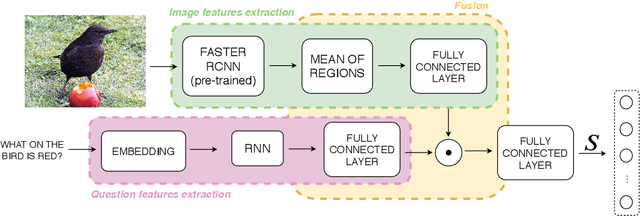
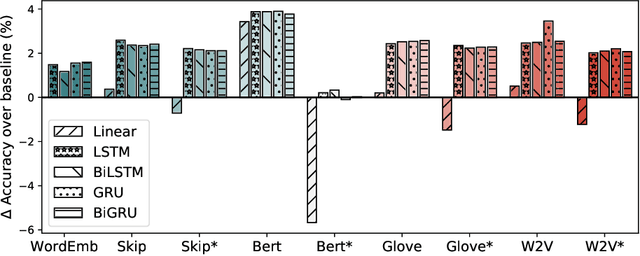
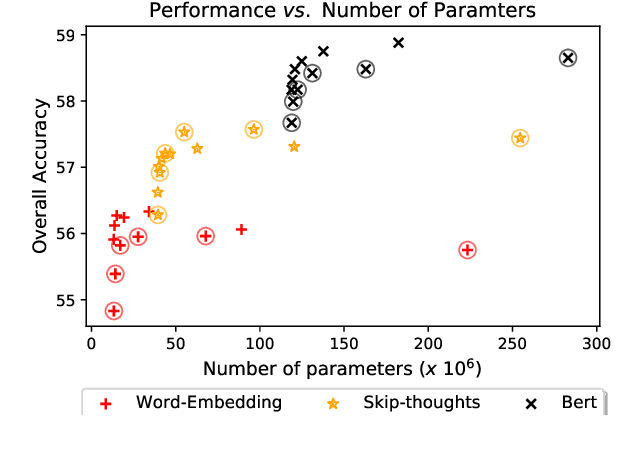
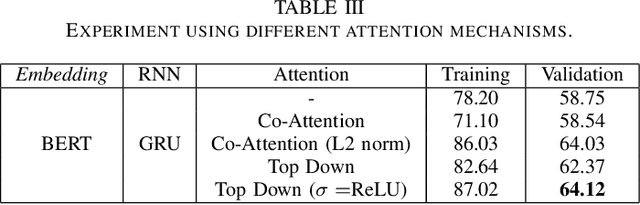
Recent research advances in Computer Vision and Natural Language Processing have introduced novel tasks that are paving the way for solving AI-complete problems. One of those tasks is called Visual Question Answering (VQA). A VQA system must take an image and a free-form, open-ended natural language question about the image, and produce a natural language answer as the output. Such a task has drawn great attention from the scientific community, which generated a plethora of approaches that aim to improve the VQA predictive accuracy. Most of them comprise three major components: (i) independent representation learning of images and questions; (ii) feature fusion so the model can use information from both sources to answer visual questions; and (iii) the generation of the correct answer in natural language. With so many approaches being recently introduced, it became unclear the real contribution of each component for the ultimate performance of the model. The main goal of this paper is to provide a comprehensive analysis regarding the impact of each component in VQA models. Our extensive set of experiments cover both visual and textual elements, as well as the combination of these representations in form of fusion and attention mechanisms. Our major contribution is to identify core components for training VQA models so as to maximize their predictive performance.