 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Listening to Me? Fine-Tuning Chatbots for Empathetic Dialogue
Jul 03, 2025Conversational agents have made significant progress since ELIZA, expanding their role across various domains, including healthcare, education, and customer service. As these agents become increasingly integrated into daily human interactions, the need for emotional intelligence, particularly empathetic listening, becomes increasingly essential. In this study, we explore how Large Language Models (LLMs) respond when tasked with generating emotionally rich interactions. Starting from a small dataset manually crafted by an expert to reflect empathic behavior, we extended the conversations using two LLMs: ChatGPT and Gemini. We analyzed the emotional progression of the dialogues using both sentiment analysis (via VADER) and expert assessments. While the generated conversations often mirrored the intended emotional structure, human evaluation revealed important differences in the perceived empathy and coherence of the responses. These findings suggest that emotion modeling in dialogues requires not only structural alignment in the expressed emotions but also qualitative depth, highlighting the importance of combining automated and humancentered methods in the development of emotionally competent agents.
Exploring Foundation Models for Synthetic Medical Imaging: A Study on Chest X-Rays and Fine-Tuning Techniques
Sep 06, 2024



Machine learning has significantly advanced healthcare by aiding in disease prevention and treatment identification. However, accessing patient data can be challenging due to privacy concerns and strict regulations. Generating synthetic, realistic data offers a potential solution for overcoming these limitations, and recent studies suggest that fine-tuning foundation models can produce such data effectively. In this study, we explore the potential of foundation models for generating realistic medical images, particularly chest x-rays, and assess how their performance improves with fine-tuning. We propose using a Latent Diffusion Model, starting with a pre-trained foundation model and refining it through various configurations. Additionally, we performed experiments with input from a medical professional to assess the realism of the images produced by each trained model.
Detecting Events in Crowds Through Changes in Geometrical Dimensions of Pedestrians
Dec 11, 2023


Security is an important topic in our contemporary world, and the ability to automate the detection of any events of interest that can take place in a crowd is of great interest to a population. We hypothesize that the detection of events in videos is correlated with significant changes in pedestrian behaviors. In this paper, we examine three different scenarios of crowd behavior, containing both the cases where an event triggers a change in the behavior of the crowd and two video sequences where the crowd and its motion remain mostly unchanged. With both the videos and the tracking of the individual pedestrians (performed in a pre-processed phase), we use Geomind, a software we developed to extract significant data about the scene, in particular, the geometrical features, personalities, and emotions of each person. We then examine the output, seeking a significant change in the way each person acts as a function of the time, that could be used as a basis to identify events or to model realistic crowd actions. When applied to the games area, our method can use the detected events to find some sort of pattern to be then used in agent simulation. Results indicate that our hypothesis seems valid in the sense that the visually observed events could be automatically detected using GeoMind.
Can we truly transfer an actor's genuine happiness to avatars? An investigation into virtual, real, posed and spontaneous faces
Dec 04, 2023A look is worth a thousand words is a popular phrase. And why is a simple look enough to portray our feelings about something or someone? Behind this question are the theoretical foundations of the field of psychology regarding social cognition and the studies of psychologist Paul Ekman. Facial expressions, as a form of non-verbal communication, are the primary way to transmit emotions between human beings. The set of movements and expressions of facial muscles that convey some emotional state of the individual to their observers are targets of studies in many areas. Our research aims to evaluate Ekman's action units in datasets of real human faces, posed and spontaneous, and virtual human faces resulting from transferring real faces into Computer Graphics faces. In addition, we also conducted a case study with specific movie characters, such as SheHulk and Genius. We intend to find differences and similarities in facial expressions between real and CG datasets, posed and spontaneous faces, and also to consider the actors' genders in the videos. This investigation can help several areas of knowledge, whether using real or virtual human beings, in education, health, entertainment, games, security, and even legal matters. Our results indicate that AU intensities are greater for posed than spontaneous datasets, regardless of gender. Furthermore, there is a smoothing of intensity up to 80 percent for AU6 and 45 percent for AU12 when a real face is transformed into CG.
Mitigating Bias in Facial Analysis Systems by Incorporating Label Diversity
Apr 13, 2022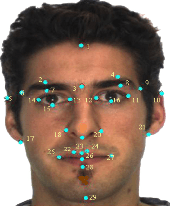
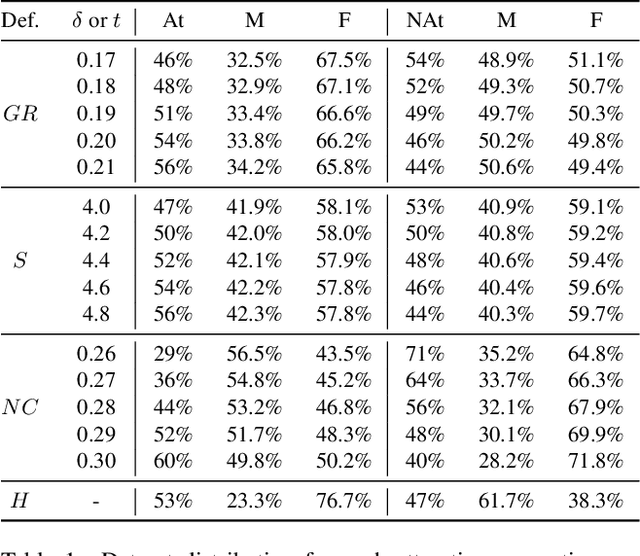
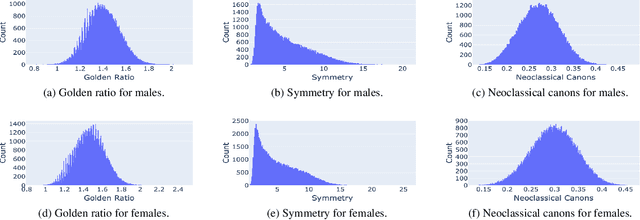
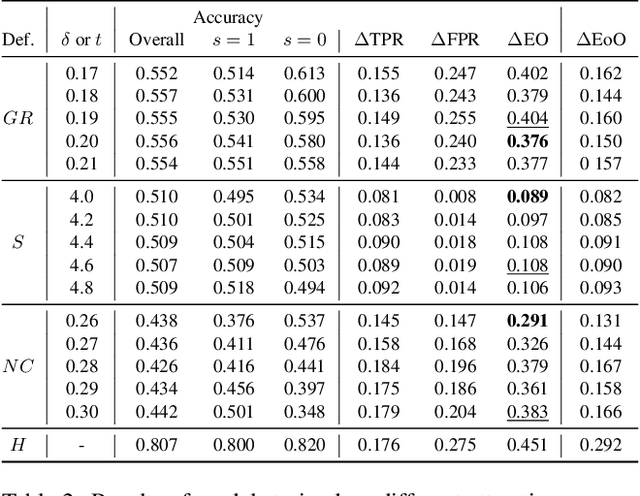
Facial analysis models are increasingly applied in real-world applications that have significant impact on peoples' lives. However, as previously shown, models that automatically classify facial attributes might exhibit algorithmic discrimination behavior with respect to protected groups, potentially posing negative impacts on individuals and society. It is therefore critical to develop techniques that can mitigate unintended biases in facial classifiers. Hence, in this work, we introduce a novel learning method that combines both subjective human-based labels and objective annotations based on mathematical definitions of facial traits. Specifically, we generate new objective annotations from a large-scale human-annotated dataset, each capturing a different perspective of the analyzed facial trait. We then propose an ensemble learning method, which combines individual models trained on different types of annotations. We provide an in-depth analysis of the annotation procedure as well as the dataset distribution. Moreover, we empirically demonstrate that, by incorporating label diversity, and without additional synthetic images, our method successfully mitigates unintended biases, while maintaining significant accuracy on the downstream task.
Detecting Personality and Emotion Traits in Crowds from Video Sequences
Apr 27, 2021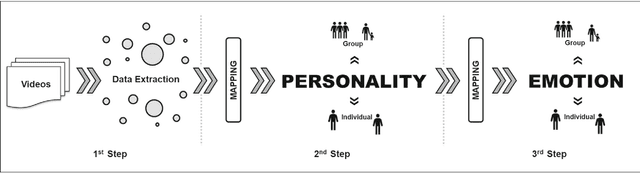
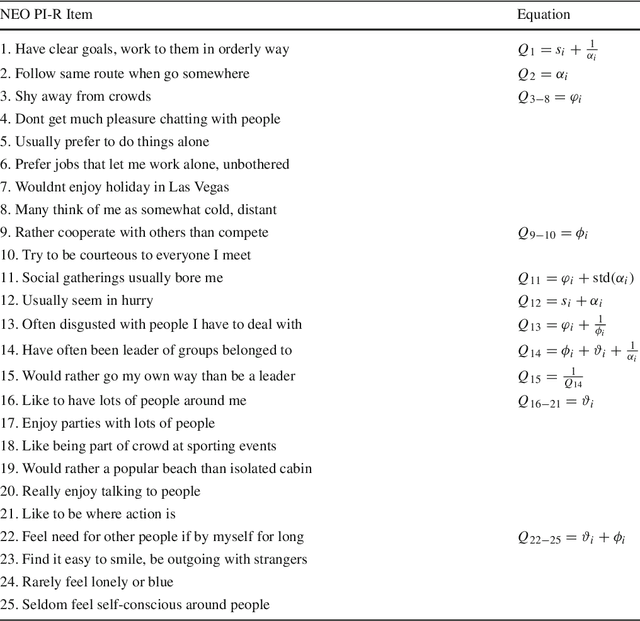
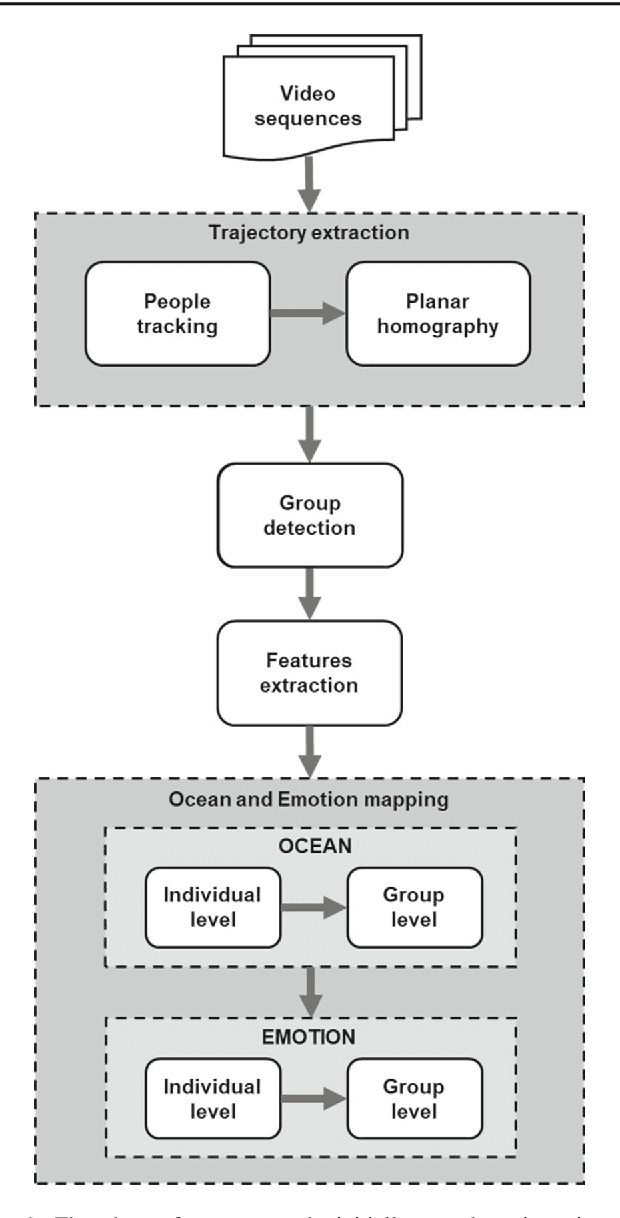

This paper presents a methodology to detect personality and basic emotion characteristics of crowds in video sequences. Firstly, individuals are detected and tracked, then groups are recognized and characterized. Such information is then mapped to OCEAN dimensions, used to find out personality and emotion in videos, based on OCC emotion models. Although it is a clear challenge to validate our results with real life experiments, we evaluate our method with the available literature information regarding OCEAN values of different Countries and also emergent Personal distance among people. Hence, such analysis refer to cultural differences of each country too. Our results indicate that this model generates coherent information when compared to data provided in available literature, as shown in qualitative and quantitative results.
A Software to Detect OCC Emotion, Big-Five Personality and Hofstede Cultural Dimensions of Pedestrians from Video Sequences
Aug 18, 2019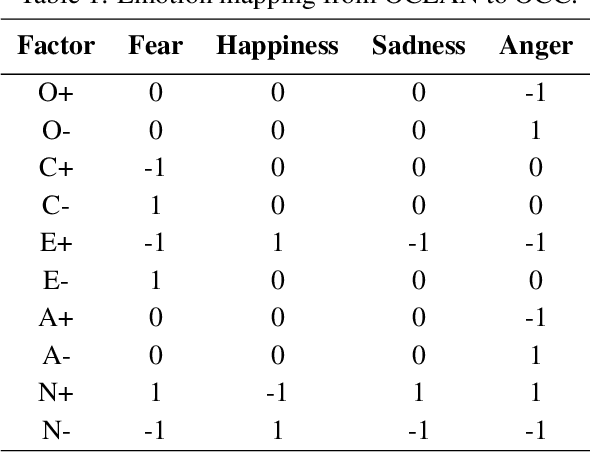


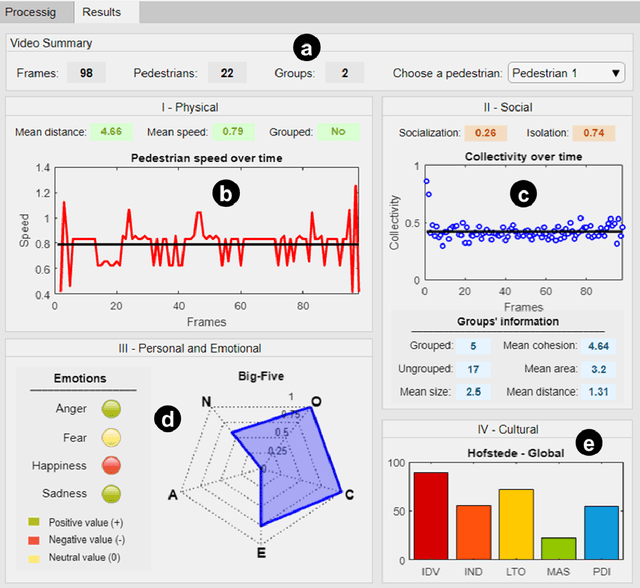
This paper presents a video analysis application to detect personality, emotion and cultural aspects from pedestrians in video sequences, along with a visualizer of features. The proposed model considers a series of characteristics of the pedestrians and the crowd, such as number and size of groups, distances, speeds, among others, and performs the mapping of these characteristics in personalities, emotions and cultural aspects, considering the Cultural Dimensions of Hofstede (HCD), the Big-Five Personality Model (OCEAN) and the OCC Emotional Model. The main hypothesis is that there is a relationship between so-called intrinsic human variables (such as emotion) and the way people behave in space and time. The software was tested in a set of videos from different countries and results seem promising in order to identify these three different levels of psychological traits in the filmed sequences. In addition, the data of the people present in the videos can be seen in a crowd viewer.
How much do you perceive this? An analysis on perceptions of geometric features, personalities and emotions in virtual humans
Apr 24, 2019
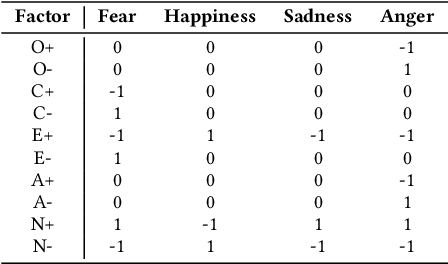


This work aims to evaluate people's perception regarding geometric features, personalities and emotions characteristics in virtual humans. For this, we use as a basis, a dataset containing the tracking files of pedestrians captured from spontaneous videos and visualized them as identical virtual humans. The goal is to focus on their behavior and not being distracted by other features. In addition to tracking files containing their positions, the dataset also contains pedestrian emotions and personalities detected using Computer Vision and Pattern Recognition techniques. We proceed with our analysis in order to answer the question if subjects can perceive geometric features as distances/speeds as well as emotions and personalities in video sequences when pedestrians are represented by virtual humans. Regarding the participants, an amount of 73 people volunteered for the experiment. The analysis was divided in two parts: i) evaluation on perception of geometric characteristics, such as density, angular variation, distances and speeds, and ii) evaluation on personality and emotion perceptions. Results indicate that, even without explaining to the participants the concepts of each personality or emotion and how they were calculated (considering geometric characteristics), in most of the cases, participants perceived the personality and emotion expressed by the virtual agents, in accordance with the available ground truth.
Predicting Future Pedestrian Motion in Video Sequences using Crowd Simulation
Apr 10, 2019



While human and group analysis have become an important area in last decades, some current and relevant applications involve to estimate future motion of pedestrians in real video sequences. This paper presents a method to provide motion estimation of real pedestrians in next seconds, using crowd simulation. Our method is based on Physics and heuristics and use BioCrowds as crowd simulation methodology to estimate future positions of people in video sequences. Results show that our method for estimation works well even for complex videos where events can happen. The maximum achieved average error is $2.72$cm when estimating the future motion of 32 pedestrians with more than 2 seconds in advance. This paper discusses this and other results.
Using Big Five Personality Model to Detect Cultural Aspects in Crowds
Mar 05, 2019

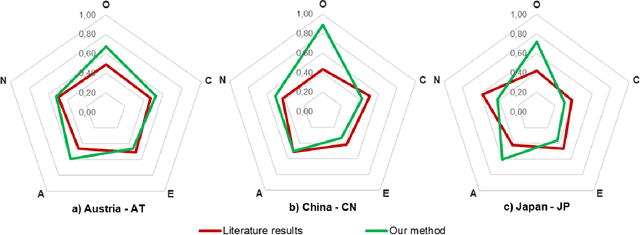
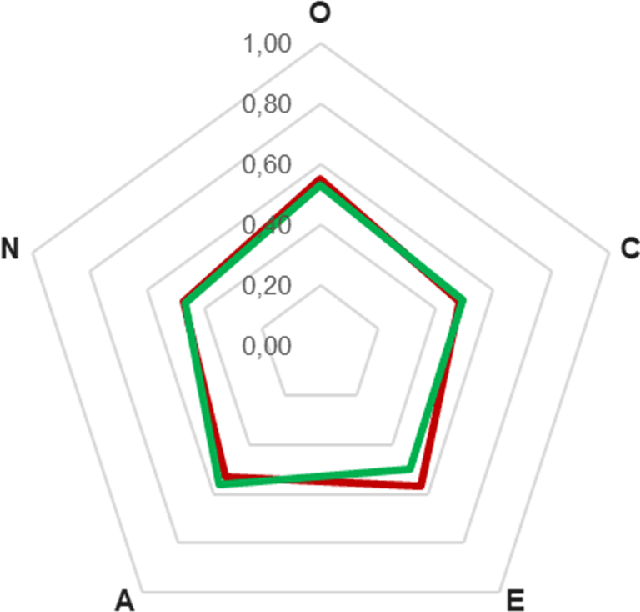
The use of information technology in the study of human behavior is a subject of great scientific interest. Cultural and personality aspects are factors that influence how people interact with one another in a crowd. This paper presents a methodology to detect cultural characteristics of crowds in video sequences. Based on filmed sequences, pedestrians are detected, tracked and characterized. Such information is then used to find out cultural differences in those videos, based on the Big-five personality model. Regarding cultural differences of each country, results indicate that this model generates coherent information when compared to data provided in literature.