 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"A 6 or a 9?": Ensemble Learning Through the Multiplicity of Performant Models and Explanations
Sep 11, 2025Creating models from past observations and ensuring their effectiveness on new data is the essence of machine learning. However, selecting models that generalize well remains a challenging task. Related to this topic, the Rashomon Effect refers to cases where multiple models perform similarly well for a given learning problem. This often occurs in real-world scenarios, like the manufacturing process or medical diagnosis, where diverse patterns in data lead to multiple high-performing solutions. We propose the Rashomon Ensemble, a method that strategically selects models from these diverse high-performing solutions to improve generalization. By grouping models based on both their performance and explanations, we construct ensembles that maximize diversity while maintaining predictive accuracy. This selection ensures that each model covers a distinct region of the solution space, making the ensemble more robust to distribution shifts and variations in unseen data. We validate our approach on both open and proprietary collaborative real-world datasets, demonstrating up to 0.20+ AUROC improvements in scenarios where the Rashomon ratio is large. Additionally, we demonstrate tangible benefits for businesses in various real-world applications, highlighting the robustness, practicality, and effectiveness of our approach.
Mitigating Bias in Facial Analysis Systems by Incorporating Label Diversity
Apr 13, 2022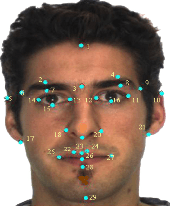
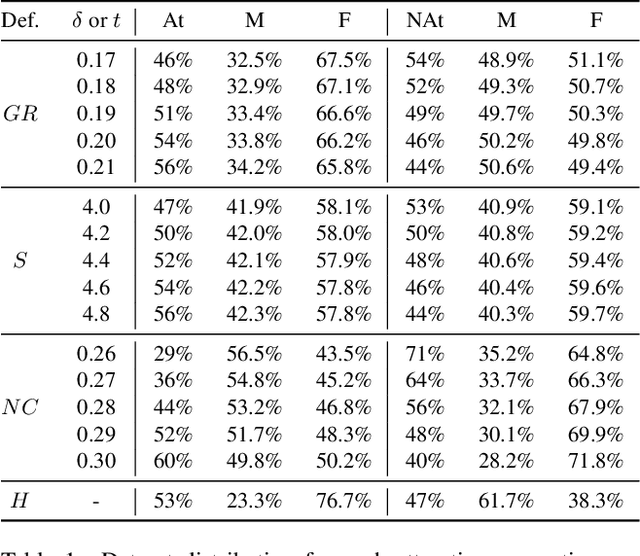
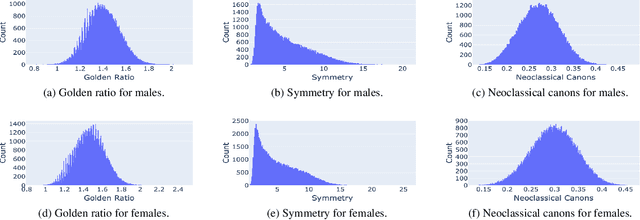
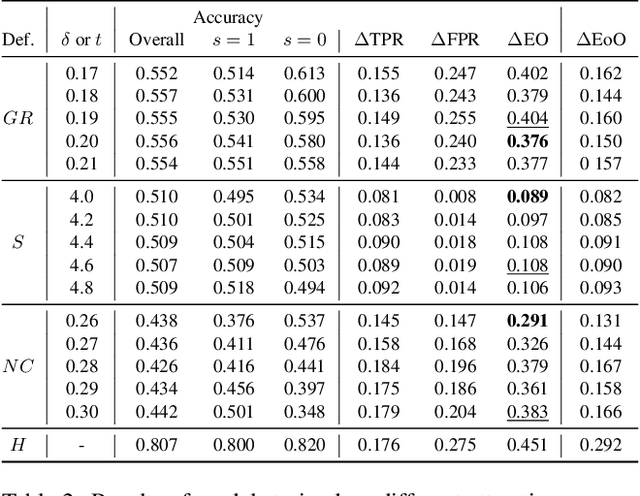
Facial analysis models are increasingly applied in real-world applications that have significant impact on peoples' lives. However, as previously shown, models that automatically classify facial attributes might exhibit algorithmic discrimination behavior with respect to protected groups, potentially posing negative impacts on individuals and society. It is therefore critical to develop techniques that can mitigate unintended biases in facial classifiers. Hence, in this work, we introduce a novel learning method that combines both subjective human-based labels and objective annotations based on mathematical definitions of facial traits. Specifically, we generate new objective annotations from a large-scale human-annotated dataset, each capturing a different perspective of the analyzed facial trait. We then propose an ensemble learning method, which combines individual models trained on different types of annotations. We provide an in-depth analysis of the annotation procedure as well as the dataset distribution. Moreover, we empirically demonstrate that, by incorporating label diversity, and without additional synthetic images, our method successfully mitigates unintended biases, while maintaining significant accuracy on the downstream task.
Modeling Pharmacological Effects with Multi-Relation Unsupervised Graph Embedding
May 15, 2020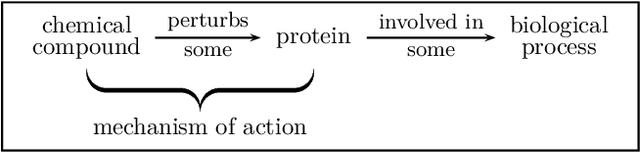
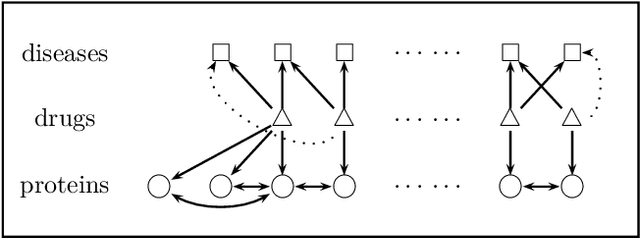
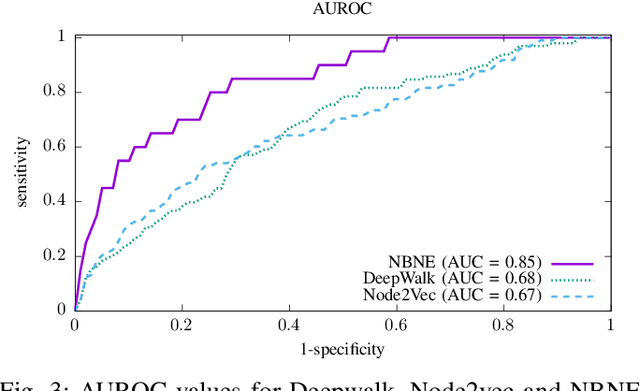
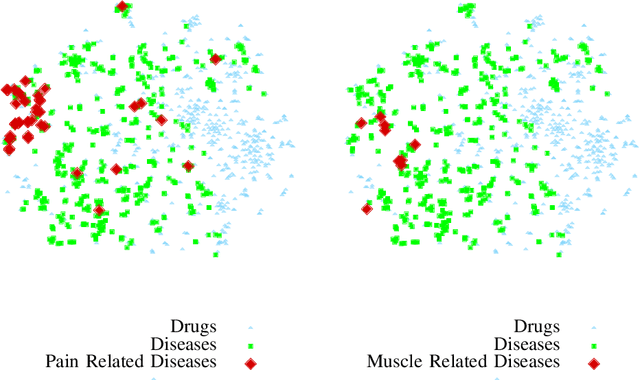
A pharmacological effect of a drug on cells, organs and systems refers to the specific biochemical interaction produced by a drug substance, which is called its mechanism of action. Drug repositioning (or drug repurposing) is a fundamental problem for the identification of new opportunities for the use of already approved or failed drugs. In this paper, we present a method based on a multi-relation unsupervised graph embedding model that learns latent representations for drugs and diseases so that the distance between these representations reveals repositioning opportunities. Once representations for drugs and diseases are obtained we learn the likelihood of new links (that is, new indications) between drugs and diseases. Known drug indications are used for learning a model that predicts potential indications. Compared with existing unsupervised graph embedding methods our method shows superior prediction performance in terms of area under the ROC curve, and we present examples of repositioning opportunities found on recent biomedical literature that were also predicted by our method.
Explainable Deep CNNs for MRI-Based Diagnosis of Alzheimer's Disease
Apr 25, 2020
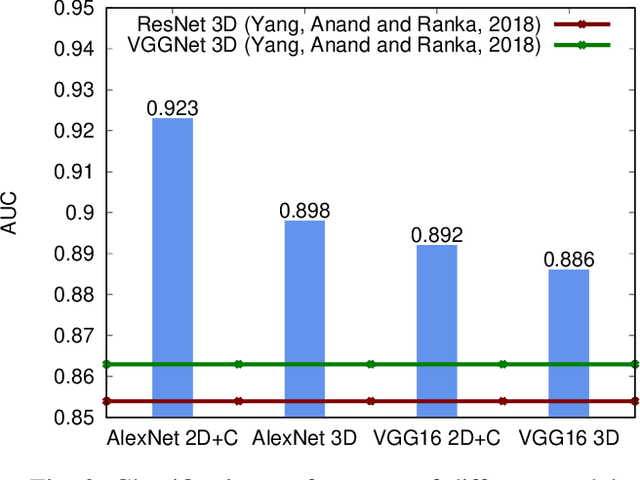
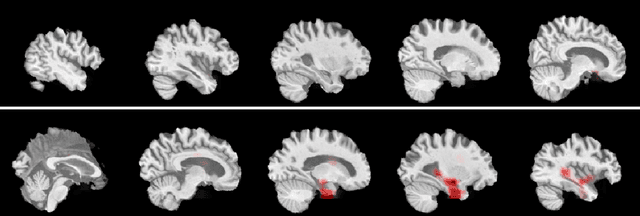
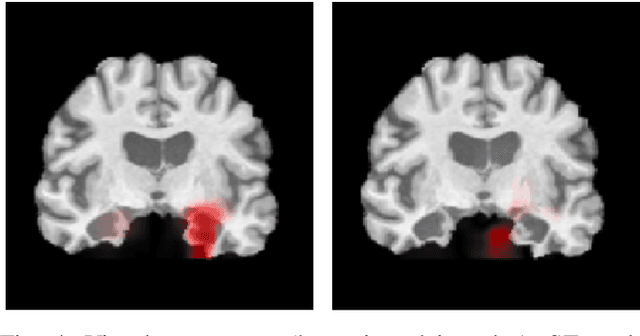
Deep Convolutional Neural Networks (CNNs) are becoming prominent models for semi-automated diagnosis of Alzheimer's Disease (AD) using brain Magnetic Resonance Imaging (MRI). Although being highly accurate, deep CNN models lack transparency and interpretability, precluding adequate clinical reasoning and not complying with most current regulatory demands. One popular choice for explaining deep image models is occluding regions of the image to isolate their influence on the prediction. However, existing methods for occluding patches of brain scans generate images outside the distribution to which the model was trained for, thus leading to unreliable explanations. In this paper, we propose an alternative explanation method that is specifically designed for the brain scan task. Our method, which we refer to as Swap Test, produces heatmaps that depict the areas of the brain that are most indicative of AD, providing interpretability for the model's decisions in a format understandable to clinicians. Experimental results using an axiomatic evaluation show that the proposed method is more suitable for explaining the diagnosis of AD using MRI while the opposite trend was observed when using a typical occlusion test. Therefore, we believe our method may address the inherent black-box nature of deep neural networks that are capable of diagnosing AD.
Assessing the Reliability of Visual Explanations of Deep Models with Adversarial Perturbations
Apr 22, 2020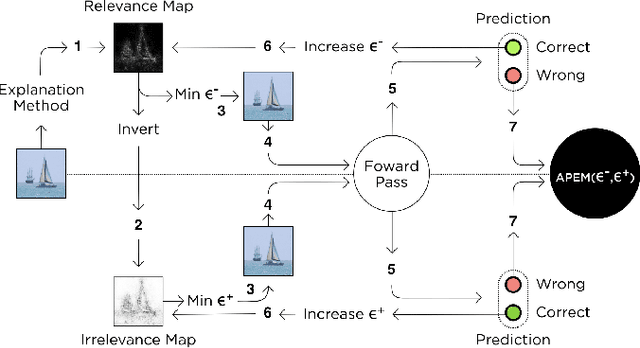
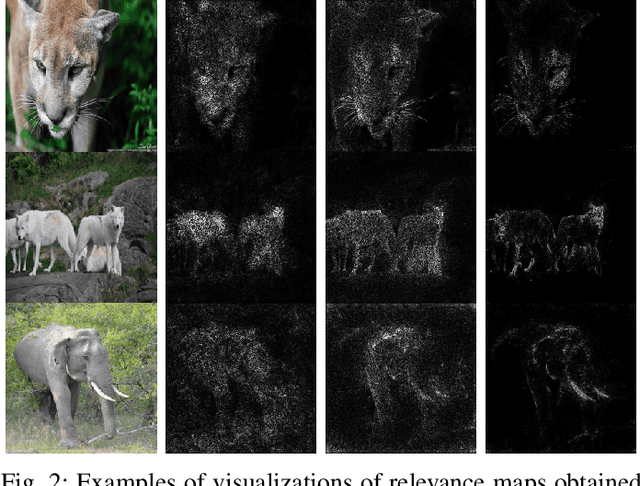


The interest in complex deep neural networks for computer vision applications is increasing. This leads to the need for improving the interpretable capabilities of these models. Recent explanation methods present visualizations of the relevance of pixels from input images, thus enabling the direct interpretation of properties of the input that lead to a specific output. These methods produce maps of pixel importance, which are commonly evaluated by visual inspection. This means that the effectiveness of an explanation method is assessed based on human expectation instead of actual feature importance. Thus, in this work we propose an objective measure to evaluate the reliability of explanations of deep models. Specifically, our approach is based on changes in the network's outcome resulting from the perturbation of input images in an adversarial way. We present a comparison between widely-known explanation methods using our proposed approach. Finally, we also propose a straightforward application of our approach to clean relevance maps, creating more interpretable maps without any loss in essential explanation (as per our proposed measure).
Automatic Tag Recommendation for Painting Artworks Using Diachronic Descriptions
Apr 21, 2020
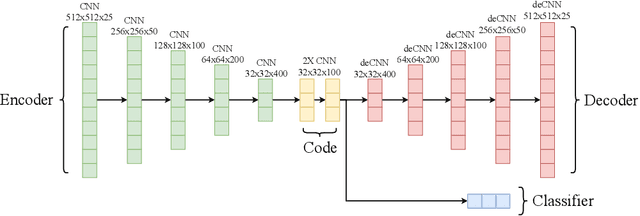

In this paper, we deal with the problem of automatic tag recommendation for painting artworks. Diachronic descriptions containing deviations on the vocabulary used to describe each painting usually occur when the work is done by many experts over time. The objective of this work is to provide a framework that produces a more accurate and homogeneous set of tags for each painting in a large collection. To validate our method we build a model based on a weakly-supervised neural network for over $5{,}300$ paintings with hand-labeled descriptions made by experts for the paintings of the Brazilian painter Candido Portinari. This work takes place with the Portinari Project which started in 1979 intending to recover and catalog the paintings of the Brazilian painter. The Portinari paintings at that time were in private collections and museums spread around the world and thus inaccessible to the public. The descriptions of each painting were made by a large number of collaborators over 40 years as the paintings were recovered and these diachronic descriptions caused deviations on the vocabulary used to describe each painting. Our proposed framework consists of (i) a neural network that receives as input the image of each painting and uses frequent itemsets as possible tags, and (ii) a clustering step in which we group related tags based on the output of the pre-trained classifiers.
Learning Transferable Features for Speech Emotion Recognition
Dec 23, 2019

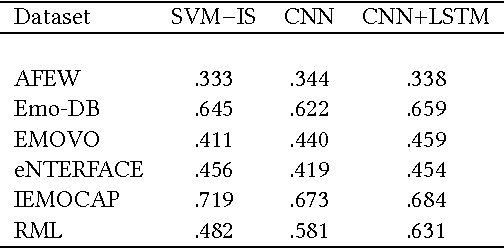

Emotion recognition from speech is one of the key steps towards emotional intelligence in advanced human-machine interaction. Identifying emotions in human speech requires learning features that are robust and discriminative across diverse domains that differ in terms of language, spontaneity of speech, recording conditions, and types of emotions. This corresponds to a learning scenario in which the joint distributions of features and labels may change substantially across domains. In this paper, we propose a deep architecture that jointly exploits a convolutional network for extracting domain-shared features and a long short-term memory network for classifying emotions using domain-specific features. We use transferable features to enable model adaptation from multiple source domains, given the sparseness of speech emotion data and the fact that target domains are short of labeled data. A comprehensive cross-corpora experiment with diverse speech emotion domains reveals that transferable features provide gains ranging from 4.3% to 18.4% in speech emotion recognition. We evaluate several domain adaptation approaches, and we perform an ablation study to understand which source domains add the most to the overall recognition effectiveness for a given target domain.
* ACM-MM'17, October 23-27, 2017
Dynamic Prediction of ICU Mortality Risk Using Domain Adaptation
Dec 20, 2019



Early recognition of risky trajectories during an Intensive Care Unit (ICU) stay is one of the key steps towards improving patient survival. Learning trajectories from physiological signals continuously measured during an ICU stay requires learning time-series features that are robust and discriminative across diverse patient populations. Patients within different ICU populations (referred here as domains) vary by age, conditions and interventions. Thus, mortality prediction models using patient data from a particular ICU population may perform suboptimally in other populations because the features used to train such models have different distributions across the groups. In this paper, we explore domain adaptation strategies in order to learn mortality prediction models that extract and transfer complex temporal features from multivariate time-series ICU data. Features are extracted in a way that the state of the patient in a certain time depends on the previous state. This enables dynamic predictions and creates a mortality risk space that describes the risk of a patient at a particular time. Experiments based on cross-ICU populations reveals that our model outperforms all considered baselines. Gains in terms of AUC range from 4% to 8% for early predictions when compared with a recent state-of-the-art representative for ICU mortality prediction. In particular, models for the Cardiac ICU population achieve AUC numbers as high as 0.88, showing excellent clinical utility for early mortality prediction. Finally, we present an explanation of factors contributing to the possible ICU outcomes, so that our models can be used to complement clinical reasoning.
A Generalized Active Learning Approach for Unsupervised Anomaly Detection
May 23, 2018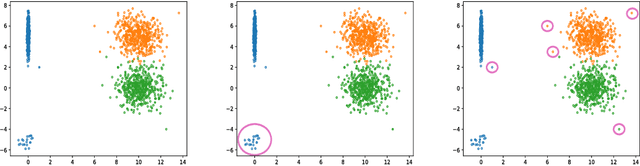
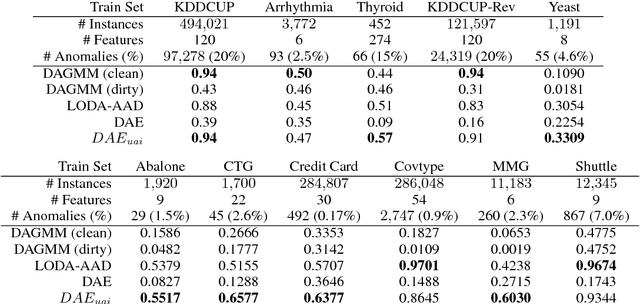
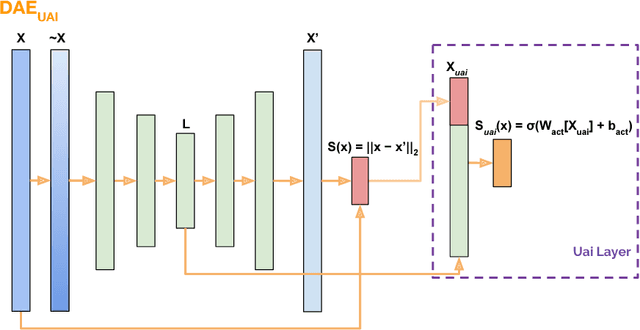

This work formalizes the new framework for anomaly detection, called active anomaly detection. This framework has, in practice, the same cost of unsupervised anomaly detection but with the possibility of much better results. We show that unsupervised anomaly detection is an undecidable problem and that a prior needs to be assumed for the anomalies probability distribution in order to have performance guarantees. Finally, we also present a new layer that can be attached to any deep learning model designed for unsupervised anomaly detection to transform it into an active anomaly detection method, presenting results on both synthetic and real anomaly detection datasets.