 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Universal to Individualized Actionability: Revisiting Personalization in Algorithmic Recourse
Apr 09, 2026Algorithmic recourse aims to provide actionable recommendations that enable individuals to change unfavorable model outcomes, and prior work has extensively studied properties such as efficiency, robustness, and fairness. However, the role of personalization in recourse remains largely implicit and underexplored. While existing approaches incorporate elements of personalization through user interactions, they typically lack an explicit definition of personalization and do not systematically analyze its downstream effects on other recourse desiderata. In this paper, we formalize personalization as individual actionability, characterized along two dimensions: hard constraints that specify which features are individually actionable, and soft, individualized constraints that capture preferences over action values and costs. We operationalize these dimensions within the causal algorithmic recourse framework, adopting a pre-hoc user-prompting approach in which individuals express preferences via rankings or scores prior to the generation of any recourse recommendation. Through extensive empirical evaluation, we investigate how personalization interacts with key recourse desiderata, including validity, cost, and plausibility. Our results highlight important trade-offs: individual actionability constraints, particularly hard ones, can substantially degrade the plausibility and validity of recourse recommendations across amortized and non-amortized approaches. Notably, we also find that incorporating individual actionability can reveal disparities in the cost and plausibility of recourse actions across socio-demographic groups. These findings underscore the need for principled definitions, careful operationalization, and rigorous evaluation of personalization in algorithmic recourse.
Evaluating LLMs for Demographic-Targeted Social Bias Detection: A Comprehensive Benchmark Study
Oct 06, 2025Large-scale web-scraped text corpora used to train general-purpose AI models often contain harmful demographic-targeted social biases, creating a regulatory need for data auditing and developing scalable bias-detection methods. Although prior work has investigated biases in text datasets and related detection methods, these studies remain narrow in scope. They typically focus on a single content type (e.g., hate speech), cover limited demographic axes, overlook biases affecting multiple demographics simultaneously, and analyze limited techniques. Consequently, practitioners lack a holistic understanding of the strengths and limitations of recent large language models (LLMs) for automated bias detection. In this study, we present a comprehensive evaluation framework aimed at English texts to assess the ability of LLMs in detecting demographic-targeted social biases. To align with regulatory requirements, we frame bias detection as a multi-label task using a demographic-focused taxonomy. We then conduct a systematic evaluation with models across scales and techniques, including prompting, in-context learning, and fine-tuning. Using twelve datasets spanning diverse content types and demographics, our study demonstrates the promise of fine-tuned smaller models for scalable detection. However, our analyses also expose persistent gaps across demographic axes and multi-demographic targeted biases, underscoring the need for more effective and scalable auditing frameworks.
A Causal Framework to Measure and Mitigate Non-binary Treatment Discrimination
Mar 28, 2025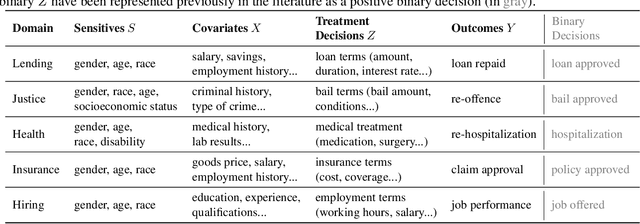
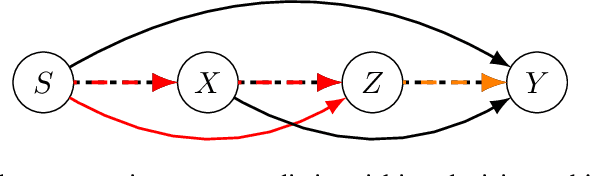

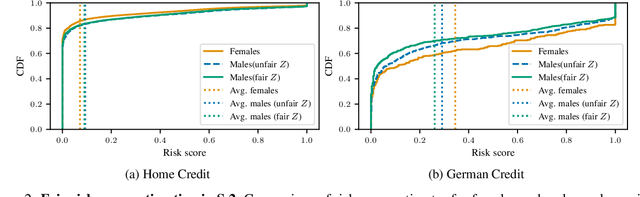
Fairness studies of algorithmic decision-making systems often simplify complex decision processes, such as bail or loan approvals, into binary classification tasks. However, these approaches overlook that such decisions are not inherently binary (e.g., approve or not approve bail or loan); they also involve non-binary treatment decisions (e.g., bail conditions or loan terms) that can influence the downstream outcomes (e.g., loan repayment or reoffending). In this paper, we argue that non-binary treatment decisions are integral to the decision process and controlled by decision-makers and, therefore, should be central to fairness analyses in algorithmic decision-making. We propose a causal framework that extends fairness analyses and explicitly distinguishes between decision-subjects' covariates and the treatment decisions. This specification allows decision-makers to use our framework to (i) measure treatment disparity and its downstream effects in historical data and, using counterfactual reasoning, (ii) mitigate the impact of past unfair treatment decisions when automating decision-making. We use our framework to empirically analyze four widely used loan approval datasets to reveal potential disparity in non-binary treatment decisions and their discriminatory impact on outcomes, highlighting the need to incorporate treatment decisions in fairness assessments. Moreover, by intervening in treatment decisions, we show that our framework effectively mitigates treatment discrimination from historical data to ensure fair risk score estimation and (non-binary) decision-making processes that benefit all stakeholders.
Don't Throw it Away! The Utility of Unlabeled Data in Fair Decision Making
May 11, 2022
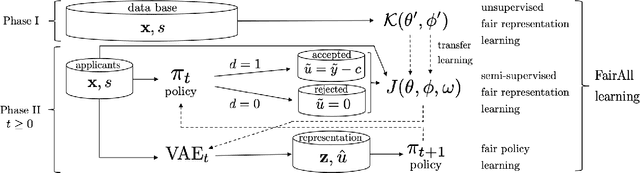

Decision making algorithms, in practice, are often trained on data that exhibits a variety of biases. Decision-makers often aim to take decisions based on some ground-truth target that is assumed or expected to be unbiased, i.e., equally distributed across socially salient groups. In many practical settings, the ground-truth cannot be directly observed, and instead, we have to rely on a biased proxy measure of the ground-truth, i.e., biased labels, in the data. In addition, data is often selectively labeled, i.e., even the biased labels are only observed for a small fraction of the data that received a positive decision. To overcome label and selection biases, recent work proposes to learn stochastic, exploring decision policies via i) online training of new policies at each time-step and ii) enforcing fairness as a constraint on performance. However, the existing approach uses only labeled data, disregarding a large amount of unlabeled data, and thereby suffers from high instability and variance in the learned decision policies at different times. In this paper, we propose a novel method based on a variational autoencoder for practical fair decision-making. Our method learns an unbiased data representation leveraging both labeled and unlabeled data and uses the representations to learn a policy in an online process. Using synthetic data, we empirically validate that our method converges to the optimal (fair) policy according to the ground-truth with low variance. In real-world experiments, we further show that our training approach not only offers a more stable learning process but also yields policies with higher fairness as well as utility than previous approaches.
Exploring Alignment of Representations with Human Perception
Nov 29, 2021
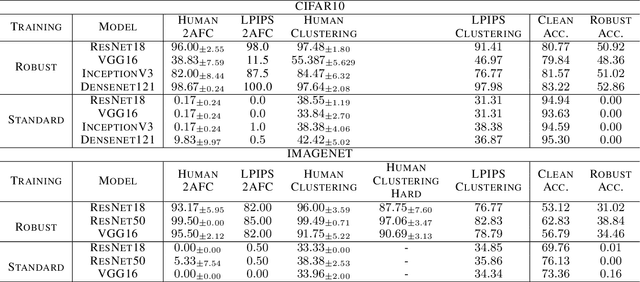


We argue that a valuable perspective on when a model learns \textit{good} representations is that inputs that are mapped to similar representations by the model should be perceived similarly by humans. We use \textit{representation inversion} to generate multiple inputs that map to the same model representation, then quantify the perceptual similarity of these inputs via human surveys. Our approach yields a measure of the extent to which a model is aligned with human perception. Using this measure of alignment, we evaluate models trained with various learning paradigms (\eg~supervised and self-supervised learning) and different training losses (standard and robust training). Our results suggest that the alignment of representations with human perception provides useful additional insights into the qualities of a model. For example, we find that alignment with human perception can be used as a measure of trust in a model's prediction on inputs where different models have conflicting outputs. We also find that various properties of a model like its architecture, training paradigm, training loss, and data augmentation play a significant role in learning representations that are aligned with human perception.