 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Alignment of Representations with Human Perception
Paper and Code

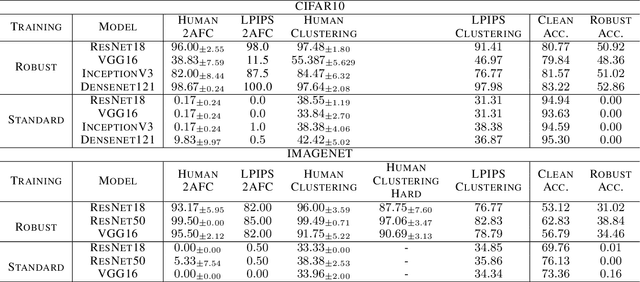


We argue that a valuable perspective on when a model learns \textit{good} representations is that inputs that are mapped to similar representations by the model should be perceived similarly by humans. We use \textit{representation inversion} to generate multiple inputs that map to the same model representation, then quantify the perceptual similarity of these inputs via human surveys. Our approach yields a measure of the extent to which a model is aligned with human perception. Using this measure of alignment, we evaluate models trained with various learning paradigms (\eg~supervised and self-supervised learning) and different training losses (standard and robust training). Our results suggest that the alignment of representations with human perception provides useful additional insights into the qualities of a model. For example, we find that alignment with human perception can be used as a measure of trust in a model's prediction on inputs where different models have conflicting outputs. We also find that various properties of a model like its architecture, training paradigm, training loss, and data augmentation play a significant role in learning representations that are aligned with human perception.