 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooks Like Magic: Transfer Learning in GANs to Generate New Card Illustrations
May 28, 2022



In this paper, we propose MAGICSTYLEGAN and MAGICSTYLEGAN-ADA - both incarnations of the state-of-the-art models StyleGan2 and StyleGan2 ADA - to experiment with their capacity of transfer learning into a rather different domain: creating new illustrations for the vast universe of the game "Magic: The Gathering" cards. This is a challenging task especially due to the variety of elements present in these illustrations, such as humans, creatures, artifacts, and landscapes - not to mention the plethora of art styles of the images made by various artists throughout the years. To solve the task at hand, we introduced a novel dataset, named MTG, with thousands of illustration from diverse card types and rich in metadata. The resulting set is a dataset composed by a myriad of both realistic and fantasy-like illustrations. Although, to investigate effects of diversity we also introduced subsets that contain specific types of concepts, such as forests, islands, faces, and humans. We show that simpler models, such as DCGANs, are not able to learn to generate proper illustrations in any setting. On the other side, we train instances of MAGICSTYLEGAN using all proposed subsets, being able to generate high quality illustrations. We perform experiments to understand how well pre-trained features from StyleGan2 can be transferred towards the target domain. We show that in well trained models we can find particular instances of noise vector that realistically represent real images from the dataset. Moreover, we provide both quantitative and qualitative studies to support our claims, and that demonstrate that MAGICSTYLEGAN is the state-of-the-art approach for generating Magic illustrations. Finally, this paper highlights some emerging properties regarding transfer learning in GANs, which is still a somehow under-explored field in generative learning research.
Efficient Neural Architecture for Text-to-Image Synthesis
Apr 23, 2020

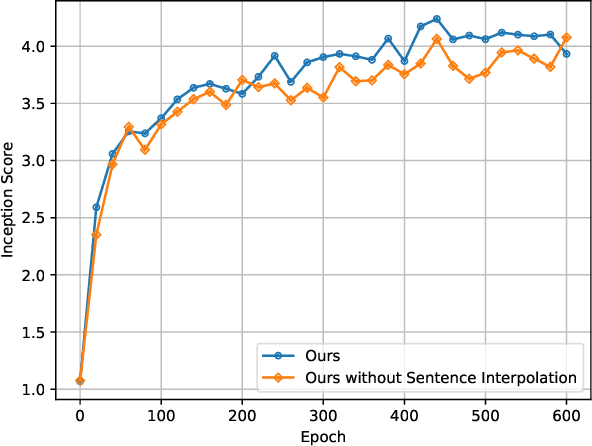

Text-to-image synthesis is the task of generating images from text descriptions. Image generation, by itself, is a challenging task. When we combine image generation and text, we bring complexity to a new level: we need to combine data from two different modalities. Most of recent works in text-to-image synthesis follow a similar approach when it comes to neural architectures. Due to aforementioned difficulties, plus the inherent difficulty of training GANs at high resolutions, most methods have adopted a multi-stage training strategy. In this paper we shift the architectural paradigm currently used in text-to-image methods and show that an effective neural architecture can achieve state-of-the-art performance using a single stage training with a single generator and a single discriminator. We do so by applying deep residual networks along with a novel sentence interpolation strategy that enables learning a smooth conditional space. Finally, our work points a new direction for text-to-image research, which has not experimented with novel neural architectures recently.
Component Analysis for Visual Question Answering Architectures
Feb 12, 2020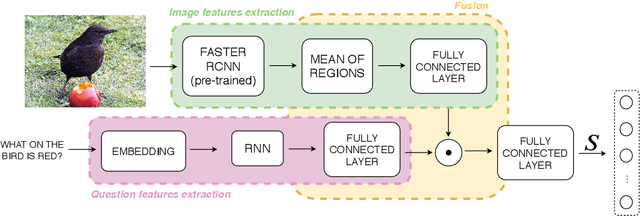
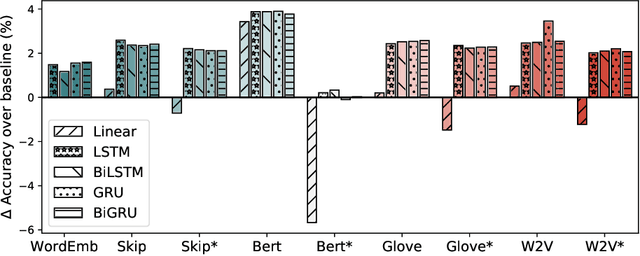
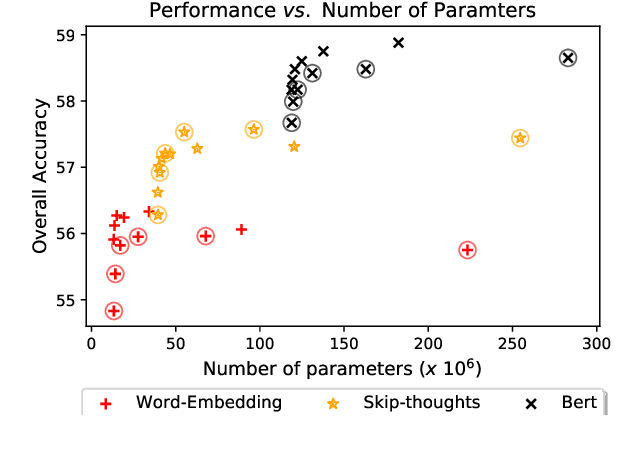
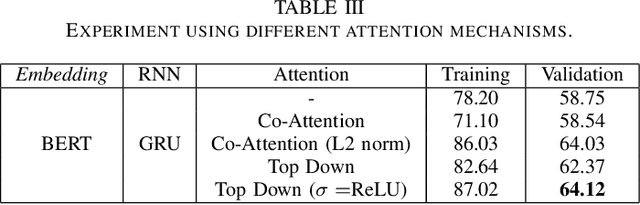
Recent research advances in Computer Vision and Natural Language Processing have introduced novel tasks that are paving the way for solving AI-complete problems. One of those tasks is called Visual Question Answering (VQA). A VQA system must take an image and a free-form, open-ended natural language question about the image, and produce a natural language answer as the output. Such a task has drawn great attention from the scientific community, which generated a plethora of approaches that aim to improve the VQA predictive accuracy. Most of them comprise three major components: (i) independent representation learning of images and questions; (ii) feature fusion so the model can use information from both sources to answer visual questions; and (iii) the generation of the correct answer in natural language. With so many approaches being recently introduced, it became unclear the real contribution of each component for the ultimate performance of the model. The main goal of this paper is to provide a comprehensive analysis regarding the impact of each component in VQA models. Our extensive set of experiments cover both visual and textual elements, as well as the combination of these representations in form of fusion and attention mechanisms. Our major contribution is to identify core components for training VQA models so as to maximize their predictive performance.
Order embeddings and character-level convolutions for multimodal alignment
Jun 03, 2017
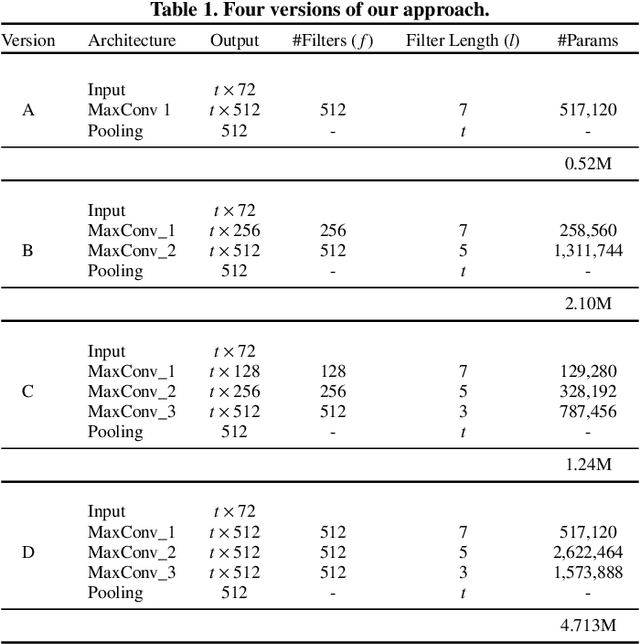
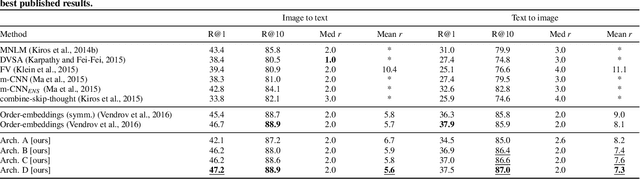
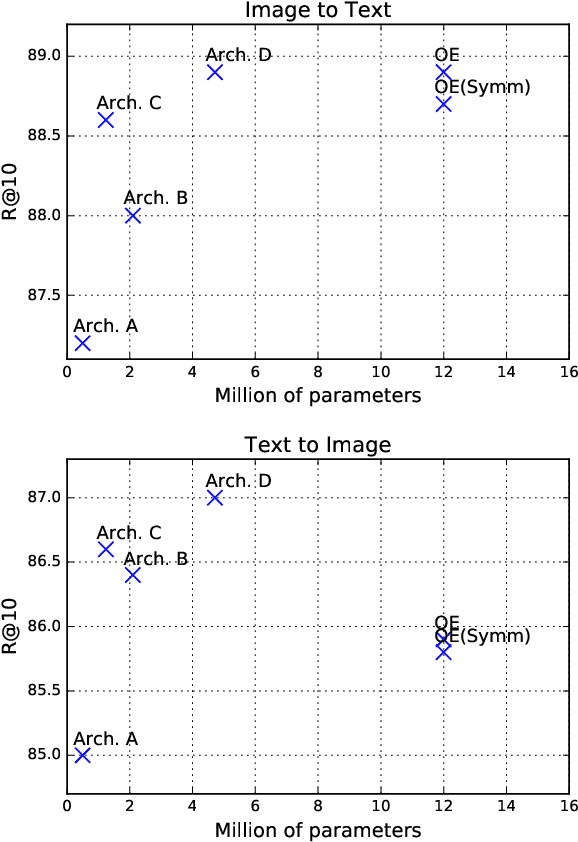
With the novel and fast advances in the area of deep neural networks, several challenging image-based tasks have been recently approached by researchers in pattern recognition and computer vision. In this paper, we address one of these tasks, which is to match image content with natural language descriptions, sometimes referred as multimodal content retrieval. Such a task is particularly challenging considering that we must find a semantic correspondence between captions and the respective image, a challenge for both computer vision and natural language processing areas. For such, we propose a novel multimodal approach based solely on convolutional neural networks for aligning images with their captions by directly convolving raw characters. Our proposed character-based textual embeddings allow the replacement of both word-embeddings and recurrent neural networks for text understanding, saving processing time and requiring fewer learnable parameters. Our method is based on the idea of projecting both visual and textual information into a common embedding space. For training such embeddings we optimize a contrastive loss function that is computed to minimize order-violations between images and their respective descriptions. We achieve state-of-the-art performance in the largest and most well-known image-text alignment dataset, namely Microsoft COCO, with a method that is conceptually much simpler and that possesses considerably fewer parameters than current approaches.