 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Explanation for Identification of the Brain Bases for Dyslexia on fMRI Data
Jul 17, 2020
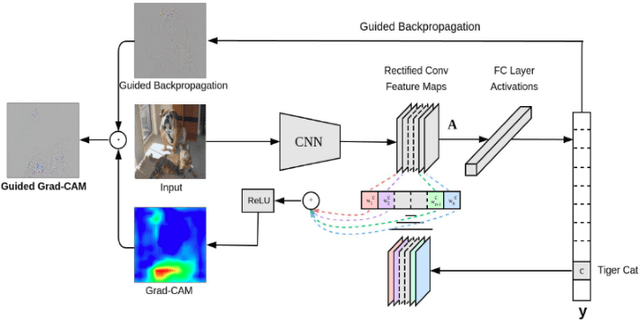

Brain imaging of mental health, neurodevelopmental and learning disorders has coupled with machine learning to identify patients based only on their brain activation, and ultimately identify features that generalize from smaller samples of data to larger ones. However, the success of machine learning classification algorithms on neurofunctional data has been limited to more homogeneous data sets of dozens of participants. More recently, larger brain imaging data sets have allowed for the application of deep learning techniques to classify brain states and clinical groups solely from neurofunctional features. Deep learning techniques provide helpful tools for classification in healthcare applications, including classification of structural 3D brain images. Recent approaches improved classification performance of larger functional brain imaging data sets, but they fail to provide diagnostic insights about the underlying conditions or provide an explanation from the neural features that informed the classification. We address this challenge by leveraging a number of network visualization techniques to show that, using such techniques in convolutional neural network layers responsible for learning high-level features, we are able to provide meaningful images for expert-backed insights into the condition being classified. Our results show not only accurate classification of developmental dyslexia from the brain imaging alone, but also provide automatic visualizations of the features involved that match contemporary neuroscientific knowledge, indicating that the visual explanations do help in unveiling the neurological bases of the disorder being classified.
Efficient Neural Architecture for Text-to-Image Synthesis
Apr 23, 2020

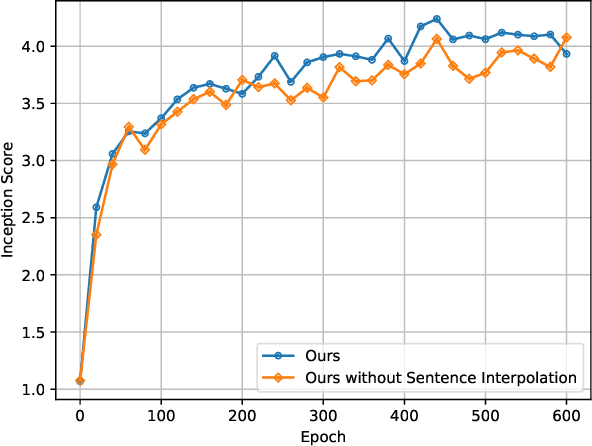

Text-to-image synthesis is the task of generating images from text descriptions. Image generation, by itself, is a challenging task. When we combine image generation and text, we bring complexity to a new level: we need to combine data from two different modalities. Most of recent works in text-to-image synthesis follow a similar approach when it comes to neural architectures. Due to aforementioned difficulties, plus the inherent difficulty of training GANs at high resolutions, most methods have adopted a multi-stage training strategy. In this paper we shift the architectural paradigm currently used in text-to-image methods and show that an effective neural architecture can achieve state-of-the-art performance using a single stage training with a single generator and a single discriminator. We do so by applying deep residual networks along with a novel sentence interpolation strategy that enables learning a smooth conditional space. Finally, our work points a new direction for text-to-image research, which has not experimented with novel neural architectures recently.