 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder embeddings and character-level convolutions for multimodal alignment
Paper and Code
Jun 03, 2017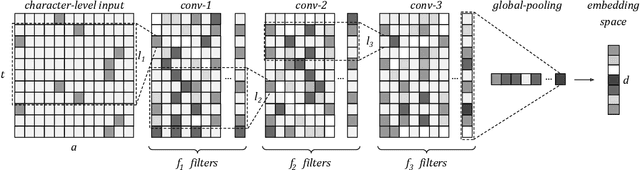
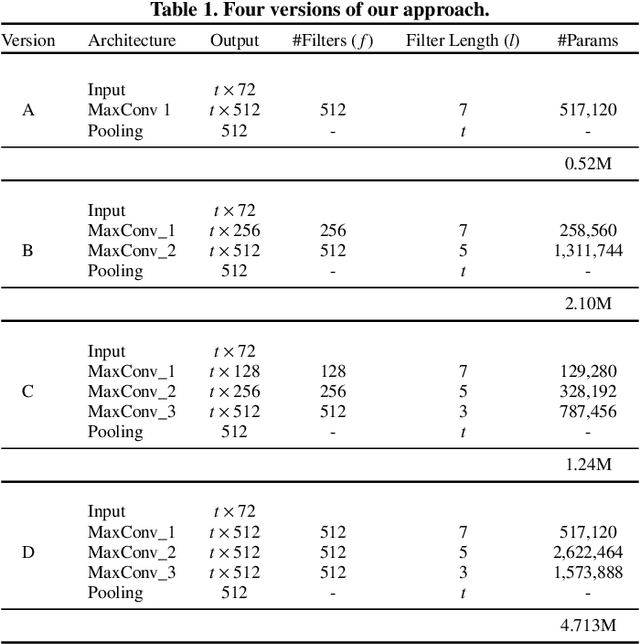
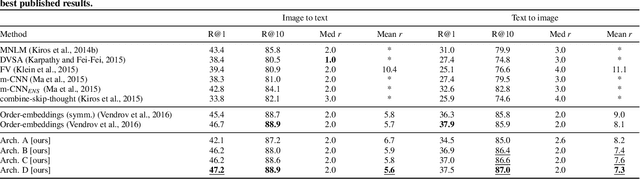
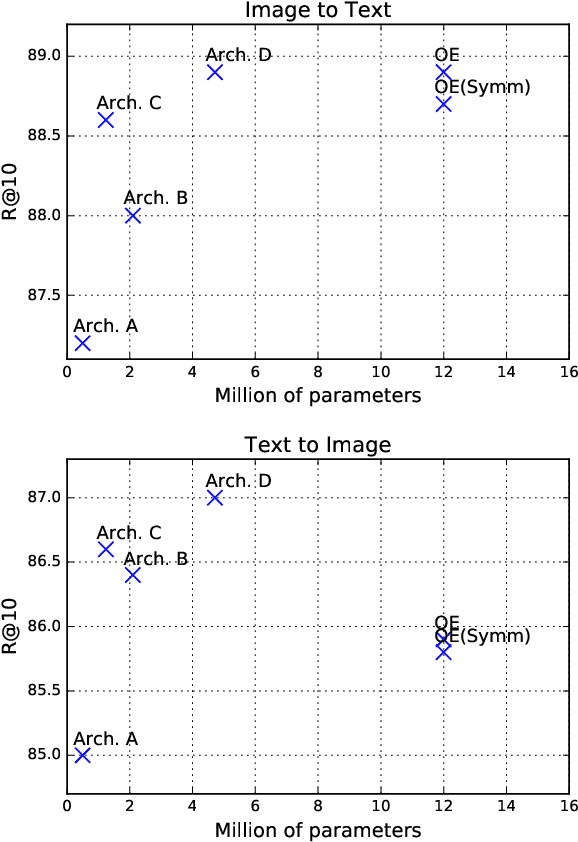
With the novel and fast advances in the area of deep neural networks, several challenging image-based tasks have been recently approached by researchers in pattern recognition and computer vision. In this paper, we address one of these tasks, which is to match image content with natural language descriptions, sometimes referred as multimodal content retrieval. Such a task is particularly challenging considering that we must find a semantic correspondence between captions and the respective image, a challenge for both computer vision and natural language processing areas. For such, we propose a novel multimodal approach based solely on convolutional neural networks for aligning images with their captions by directly convolving raw characters. Our proposed character-based textual embeddings allow the replacement of both word-embeddings and recurrent neural networks for text understanding, saving processing time and requiring fewer learnable parameters. Our method is based on the idea of projecting both visual and textual information into a common embedding space. For training such embeddings we optimize a contrastive loss function that is computed to minimize order-violations between images and their respective descriptions. We achieve state-of-the-art performance in the largest and most well-known image-text alignment dataset, namely Microsoft COCO, with a method that is conceptually much simpler and that possesses considerably fewer parameters than current approaches.