 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation
Dec 22, 2025Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the π_{0}, π_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs. Project page: https://martin-sedlacek.com/realm
6D Object Pose Tracking in Internet Videos for Robotic Manipulation
Mar 13, 2025



We seek to extract a temporally consistent 6D pose trajectory of a manipulated object from an Internet instructional video. This is a challenging set-up for current 6D pose estimation methods due to uncontrolled capturing conditions, subtle but dynamic object motions, and the fact that the exact mesh of the manipulated object is not known. To address these challenges, we present the following contributions. First, we develop a new method that estimates the 6D pose of any object in the input image without prior knowledge of the object itself. The method proceeds by (i) retrieving a CAD model similar to the depicted object from a large-scale model database, (ii) 6D aligning the retrieved CAD model with the input image, and (iii) grounding the absolute scale of the object with respect to the scene. Second, we extract smooth 6D object trajectories from Internet videos by carefully tracking the detected objects across video frames. The extracted object trajectories are then retargeted via trajectory optimization into the configuration space of a robotic manipulator. Third, we thoroughly evaluate and ablate our 6D pose estimation method on YCB-V and HOPE-Video datasets as well as a new dataset of instructional videos manually annotated with approximate 6D object trajectories. We demonstrate significant improvements over existing state-of-the-art RGB 6D pose estimation methods. Finally, we show that the 6D object motion estimated from Internet videos can be transferred to a 7-axis robotic manipulator both in a virtual simulator as well as in a real world set-up. We also successfully apply our method to egocentric videos taken from the EPIC-KITCHENS dataset, demonstrating potential for Embodied AI applications.
CNOS: A Strong Baseline for CAD-based Novel Object Segmentation
Aug 03, 2023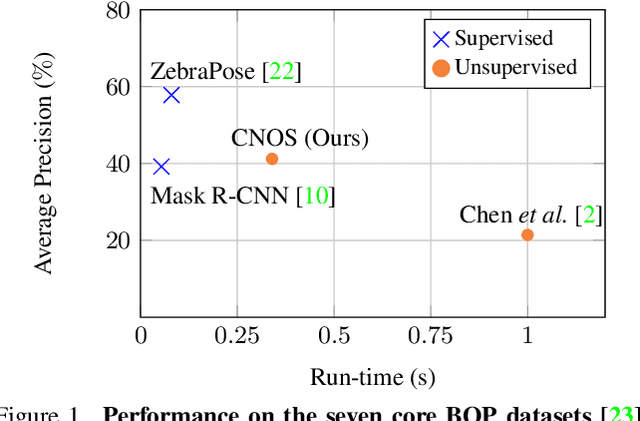



We propose a simple three-stage approach to segment unseen objects in RGB images using their CAD models. Leveraging recent powerful foundation models, DINOv2 and Segment Anything, we create descriptors and generate proposals, including binary masks for a given input RGB image. By matching proposals with reference descriptors created from CAD models, we achieve precise object ID assignment along with modal masks. We experimentally demonstrate that our method achieves state-of-the-art results in CAD-based novel object segmentation, surpassing existing approaches on the seven core datasets of the BOP challenge by 19.8% AP using the same BOP evaluation protocol. Our source code is available at https://github.com/nv-nguyen/cnos.
You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Apr 23, 2023We propose SeedAL, a method to seed active learning for efficient annotation of 3D point clouds for semantic segmentation. Active Learning (AL) iteratively selects relevant data fractions to annotate within a given budget, but requires a first fraction of the dataset (a 'seed') to be already annotated to estimate the benefit of annotating other data fractions. We first show that the choice of the seed can significantly affect the performance of many AL methods. We then propose a method for automatically constructing a seed that will ensure good performance for AL. Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds. It selects the point clouds for the seed by optimizing the diversity under an annotation budget, which can be done by solving a linear optimization problem. Our experiments demonstrate the effectiveness of our approach compared to random seeding and existing methods on both the S3DIS and SemanticKitti datasets. Code is available at \url{https://github.com/nerminsamet/seedal}.
A Simple and Powerful Global Optimization for Unsupervised Video Object Segmentation
Sep 19, 2022
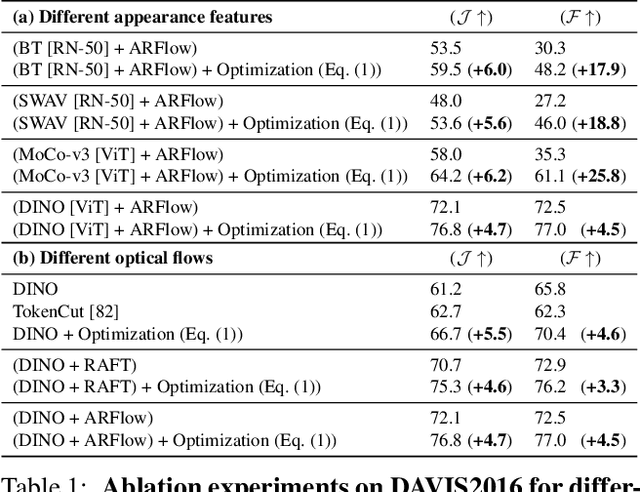


We propose a simple, yet powerful approach for unsupervised object segmentation in videos. We introduce an objective function whose minimum represents the mask of the main salient object over the input sequence. It only relies on independent image features and optical flows, which can be obtained using off-the-shelf self-supervised methods. It scales with the length of the sequence with no need for superpixels or sparsification, and it generalizes to different datasets without any specific training. This objective function can actually be derived from a form of spectral clustering applied to the entire video. Our method achieves on-par performance with the state of the art on standard benchmarks (DAVIS2016, SegTrack-v2, FBMS59), while being conceptually and practically much simpler. Code is available at https://ponimatkin.github.io/ssl-vos.
Focal Length and Object Pose Estimation via Render and Compare
Apr 11, 2022

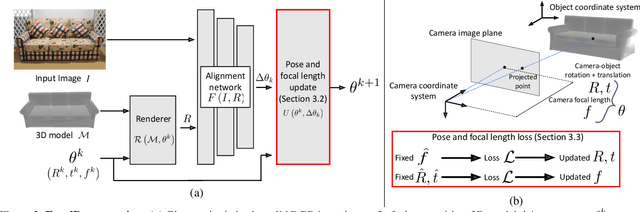

We introduce FocalPose, a neural render-and-compare method for jointly estimating the camera-object 6D pose and camera focal length given a single RGB input image depicting a known object. The contributions of this work are twofold. First, we derive a focal length update rule that extends an existing state-of-the-art render-and-compare 6D pose estimator to address the joint estimation task. Second, we investigate several different loss functions for jointly estimating the object pose and focal length. We find that a combination of direct focal length regression with a reprojection loss disentangling the contribution of translation, rotation, and focal length leads to improved results. We show results on three challenging benchmark datasets that depict known 3D models in uncontrolled settings. We demonstrate that our focal length and 6D pose estimates have lower error than the existing state-of-the-art methods.