 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Diffusion Video Generation
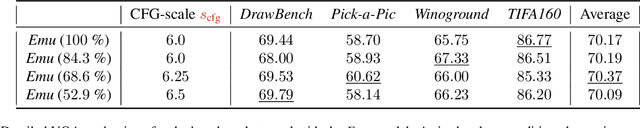
Apr 23, 2026We introduce Sparse Forcing, a training-and-inference paradigm for autoregressive video diffusion models that improves long-horizon generation quality while reducing decoding latency. Sparse Forcing is motivated by an empirical observation in autoregressive diffusion rollouts: attention concentrates on a persistent subset of salient visual blocks, forming an implicit spatiotemporal memory in the KV cache, and exhibits a locally structured block-sparse pattern within sliding windows. Building on this observation, we propose a trainable native sparsity mechanism that learns to compress, preserve, and update these persistent blocks while restricting computation within each local window to a dynamically selected local neighborhood. To make the approach practical at scale for both training and inference, we further propose Persistent Block-Sparse Attention (PBSA), an efficient GPU kernel that accelerates sparse attention and memory updates for low-latency, memory-efficient decoding. Experiments show that Sparse Forcing improves the VBench score by +0.26 over Self-Forcing on 5-second text-to-video generation while delivering a 1.11-1.17x decoding speedup and 42% lower peak KV-cache footprint. The gains are more pronounced on longer-horizon rollouts, delivering improved visual quality with +0.68 and +2.74 VBench improvements, and 1.22x and 1.27x speedups on 20-second and 1-minute generations, respectively.
SneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
Autoregressive Distillation of Diffusion Transformers
Apr 15, 2025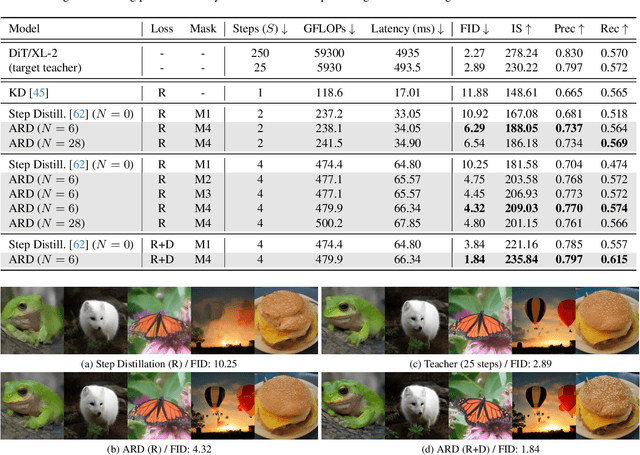
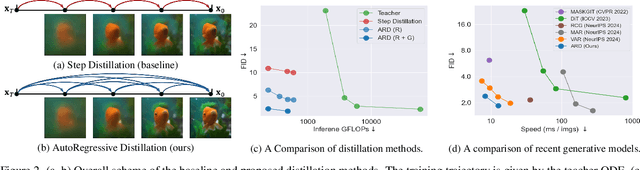
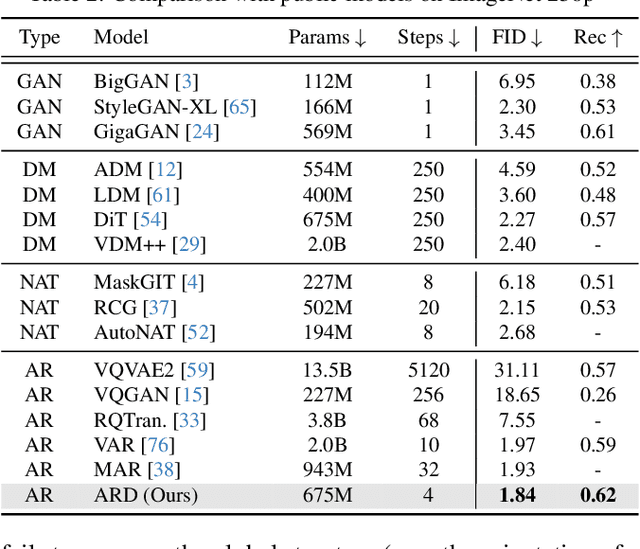
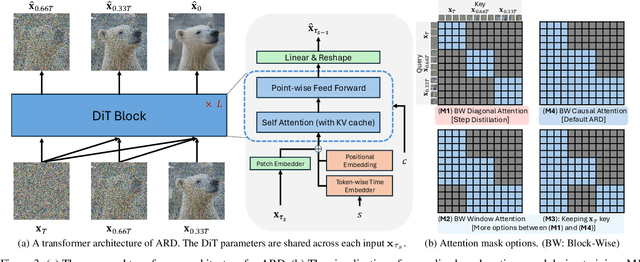
Diffusion models with transformer architectures have demonstrated promising capabilities in generating high-fidelity images and scalability for high resolution. However, iterative sampling process required for synthesis is very resource-intensive. A line of work has focused on distilling solutions to probability flow ODEs into few-step student models. Nevertheless, existing methods have been limited by their reliance on the most recent denoised samples as input, rendering them susceptible to exposure bias. To address this limitation, we propose AutoRegressive Distillation (ARD), a novel approach that leverages the historical trajectory of the ODE to predict future steps. ARD offers two key benefits: 1) it mitigates exposure bias by utilizing a predicted historical trajectory that is less susceptible to accumulated errors, and 2) it leverages the previous history of the ODE trajectory as a more effective source of coarse-grained information. ARD modifies the teacher transformer architecture by adding token-wise time embedding to mark each input from the trajectory history and employs a block-wise causal attention mask for training. Furthermore, incorporating historical inputs only in lower transformer layers enhances performance and efficiency. We validate the effectiveness of ARD in a class-conditioned generation on ImageNet and T2I synthesis. Our model achieves a $5\times$ reduction in FID degradation compared to the baseline methods while requiring only 1.1\% extra FLOPs on ImageNet-256. Moreover, ARD reaches FID of 1.84 on ImageNet-256 in merely 4 steps and outperforms the publicly available 1024p text-to-image distilled models in prompt adherence score with a minimal drop in FID compared to the teacher. Project page: https://github.com/alsdudrla10/ARD.
FlexiDiT: Your Diffusion Transformer Can Easily Generate High-Quality Samples with Less Compute
Feb 27, 2025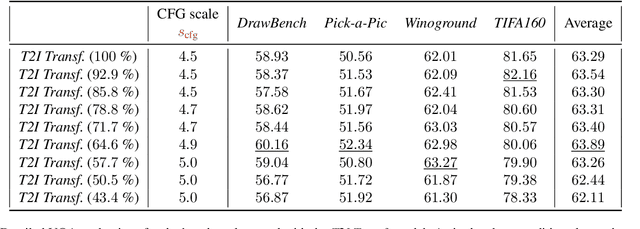


Despite their remarkable performance, modern Diffusion Transformers are hindered by substantial resource requirements during inference, stemming from the fixed and large amount of compute needed for each denoising step. In this work, we revisit the conventional static paradigm that allocates a fixed compute budget per denoising iteration and propose a dynamic strategy instead. Our simple and sample-efficient framework enables pre-trained DiT models to be converted into \emph{flexible} ones -- dubbed FlexiDiT -- allowing them to process inputs at varying compute budgets. We demonstrate how a single \emph{flexible} model can generate images without any drop in quality, while reducing the required FLOPs by more than $40$\% compared to their static counterparts, for both class-conditioned and text-conditioned image generation. Our method is general and agnostic to input and conditioning modalities. We show how our approach can be readily extended for video generation, where FlexiDiT models generate samples with up to $75$\% less compute without compromising performance.
Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
Jan 31, 2025



The performance of large language models (LLMs) is closely linked to their underlying size, leading to ever-growing networks and hence slower inference. Speculative decoding has been proposed as a technique to accelerate autoregressive generation, leveraging a fast draft model to propose candidate tokens, which are then verified in parallel based on their likelihood under the target model. While this approach guarantees to reproduce the target output, it incurs a substantial penalty: many high-quality draft tokens are rejected, even when they represent objectively valid continuations. Indeed, we show that even powerful draft models such as GPT-4o, as well as human text cannot achieve high acceptance rates under the standard verification scheme. This severely limits the speedup potential of current speculative decoding methods, as an early rejection becomes overwhelmingly likely when solely relying on alignment of draft and target. We thus ask the following question: Can we adapt verification to recognize correct, but non-aligned replies? To this end, we draw inspiration from the LLM-as-a-judge framework, which demonstrated that LLMs are able to rate answers in a versatile way. We carefully design a dataset to elicit the same capability in the target model by training a compact module on top of the embeddings to produce ``judgements" of the current continuation. We showcase our strategy on the Llama-3.1 family, where our 8b/405B-Judge achieves a speedup of 9x over Llama-405B, while maintaining its quality on a large range of benchmarks. These benefits remain present even in optimized inference frameworks, where our method reaches up to 141 tokens/s for 8B/70B-Judge and 129 tokens/s for 8B/405B on 2 and 8 H100s respectively.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
Apr 17, 2023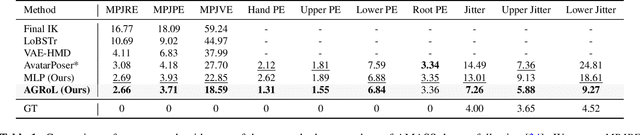
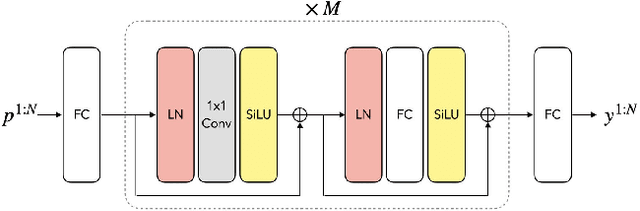
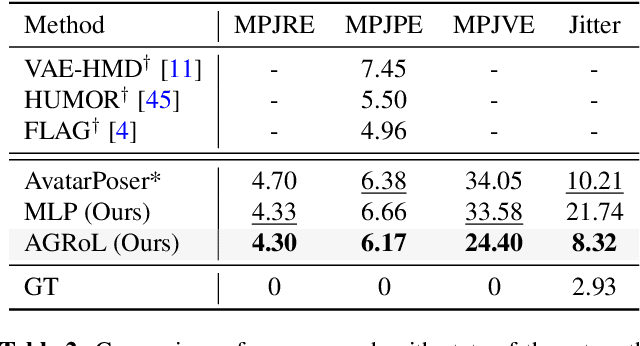
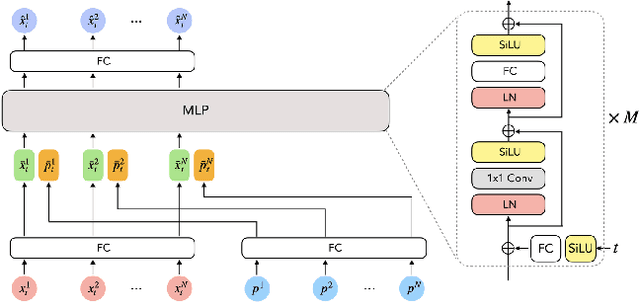
With the recent surge in popularity of AR/VR applications, realistic and accurate control of 3D full-body avatars has become a highly demanded feature. A particular challenge is that only a sparse tracking signal is available from standalone HMDs (Head Mounted Devices), often limited to tracking the user's head and wrists. While this signal is resourceful for reconstructing the upper body motion, the lower body is not tracked and must be synthesized from the limited information provided by the upper body joints. In this paper, we present AGRoL, a novel conditional diffusion model specifically designed to track full bodies given sparse upper-body tracking signals. Our model is based on a simple multi-layer perceptron (MLP) architecture and a novel conditioning scheme for motion data. It can predict accurate and smooth full-body motion, particularly the challenging lower body movement. Unlike common diffusion architectures, our compact architecture can run in real-time, making it suitable for online body-tracking applications. We train and evaluate our model on AMASS motion capture dataset, and demonstrate that our approach outperforms state-of-the-art methods in generated motion accuracy and smoothness. We further justify our design choices through extensive experiments and ablation studies.
Multi-Finger Grasping Like Humans
Nov 14, 2022Robots with multi-fingered grippers could perform advanced manipulation tasks for us if we were able to properly specify to them what to do. In this study, we take a step in that direction by making a robot grasp an object like a grasping demonstration performed by a human. We propose a novel optimization-based approach for transferring human grasp demonstrations to any multi-fingered grippers, which produces robotic grasps that mimic the human hand orientation and the contact area with the object, while alleviating interpenetration. Extensive experiments with the Allegro and BarrettHand grippers show that our method leads to grasps more similar to the human demonstration than existing approaches, without requiring any gripper-specific tuning. We confirm these findings through a user study and validate the applicability of our approach on a real robot.
* presented at IROS 2022 conference
A Simple and Powerful Global Optimization for Unsupervised Video Object Segmentation
Sep 19, 2022
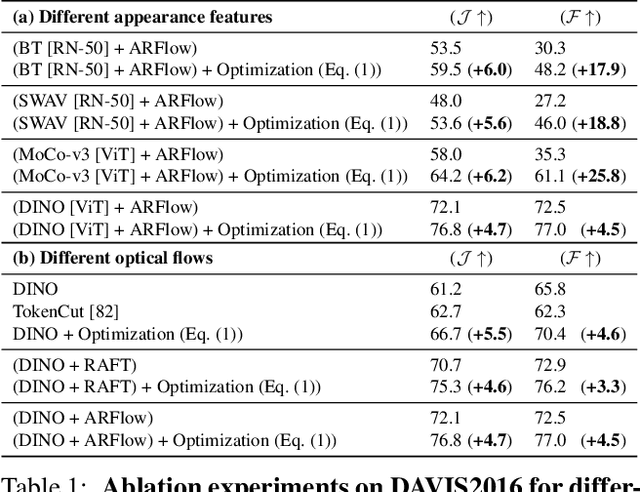


We propose a simple, yet powerful approach for unsupervised object segmentation in videos. We introduce an objective function whose minimum represents the mask of the main salient object over the input sequence. It only relies on independent image features and optical flows, which can be obtained using off-the-shelf self-supervised methods. It scales with the length of the sequence with no need for superpixels or sparsification, and it generalizes to different datasets without any specific training. This objective function can actually be derived from a form of spectral clustering applied to the entire video. Our method achieves on-par performance with the state of the art on standard benchmarks (DAVIS2016, SegTrack-v2, FBMS59), while being conceptually and practically much simpler. Code is available at https://ponimatkin.github.io/ssl-vos.
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022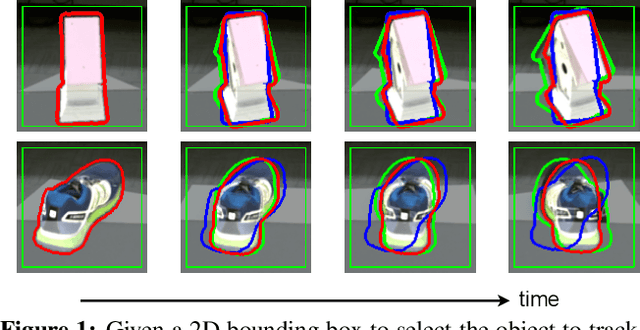
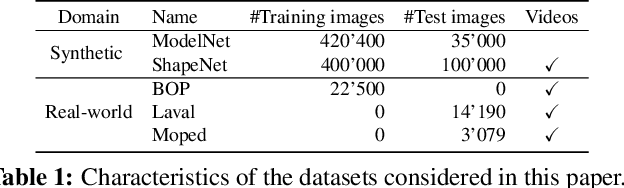
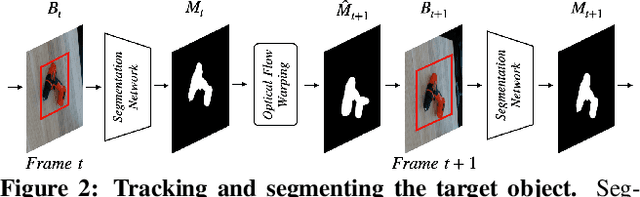
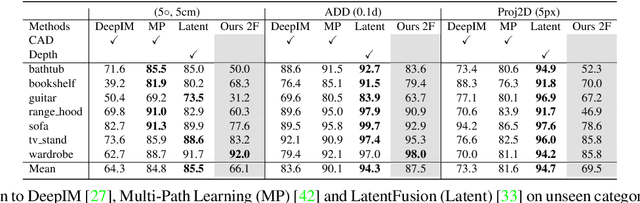
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza