 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Mesh Modeling for Anny Body
Nov 05, 2025Parametric body models are central to many human-centric tasks, yet existing models often rely on costly 3D scans and learned shape spaces that are proprietary and demographically narrow. We introduce Anny, a simple, fully differentiable, and scan-free human body model grounded in anthropometric knowledge from the MakeHuman community. Anny defines a continuous, interpretable shape space, where phenotype parameters (e.g. gender, age, height, weight) control blendshapes spanning a wide range of human forms -- across ages (from infants to elders), body types, and proportions. Calibrated using WHO population statistics, it provides realistic and demographically grounded human shape variation within a single unified model. Thanks to its openness and semantic control, Anny serves as a versatile foundation for 3D human modeling -- supporting millimeter-accurate scan fitting, controlled synthetic data generation, and Human Mesh Recovery (HMR). We further introduce Anny-One, a collection of 800k photorealistic humans generated with Anny, showing that despite its simplicity, HMR models trained with Anny can match the performance of those trained with scan-based body models, while remaining interpretable and broadly representative. The Anny body model and its code are released under the Apache 2.0 license, making Anny an accessible foundation for human-centric 3D modeling.
What does really matter in image goal navigation?
Jul 02, 2025Image goal navigation requires two different skills: firstly, core navigation skills, including the detection of free space and obstacles, and taking decisions based on an internal representation; and secondly, computing directional information by comparing visual observations to the goal image. Current state-of-the-art methods either rely on dedicated image-matching, or pre-training of computer vision modules on relative pose estimation. In this paper, we study whether this task can be efficiently solved with end-to-end training of full agents with RL, as has been claimed by recent work. A positive answer would have impact beyond Embodied AI and allow training of relative pose estimation from reward for navigation alone. In a large study we investigate the effect of architectural choices like late fusion, channel stacking, space-to-depth projections and cross-attention, and their role in the emergence of relative pose estimators from navigation training. We show that the success of recent methods is influenced up to a certain extent by simulator settings, leading to shortcuts in simulation. However, we also show that these capabilities can be transferred to more realistic setting, up to some extend. We also find evidence for correlations between navigation performance and probed (emerging) relative pose estimation performance, an important sub skill.
Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
Mar 21, 2025We present Pow3r, a novel large 3D vision regression model that is highly versatile in the input modalities it accepts. Unlike previous feed-forward models that lack any mechanism to exploit known camera or scene priors at test time, Pow3r incorporates any combination of auxiliary information such as intrinsics, relative pose, dense or sparse depth, alongside input images, within a single network. Building upon the recent DUSt3R paradigm, a transformer-based architecture that leverages powerful pre-training, our lightweight and versatile conditioning acts as additional guidance for the network to predict more accurate estimates when auxiliary information is available. During training we feed the model with random subsets of modalities at each iteration, which enables the model to operate under different levels of known priors at test time. This in turn opens up new capabilities, such as performing inference in native image resolution, or point-cloud completion. Our experiments on 3D reconstruction, depth completion, multi-view depth prediction, multi-view stereo, and multi-view pose estimation tasks yield state-of-the-art results and confirm the effectiveness of Pow3r at exploiting all available information. The project webpage is https://europe.naverlabs.com/pow3r.
DUNE: Distilling a Universal Encoder from Heterogeneous 2D and 3D Teachers
Mar 18, 2025Recent multi-teacher distillation methods have unified the encoders of multiple foundation models into a single encoder, achieving competitive performance on core vision tasks like classification, segmentation, and depth estimation. This led us to ask: Could similar success be achieved when the pool of teachers also includes vision models specialized in diverse tasks across both 2D and 3D perception? In this paper, we define and investigate the problem of heterogeneous teacher distillation, or co-distillation, a challenging multi-teacher distillation scenario where teacher models vary significantly in both (a) their design objectives and (b) the data they were trained on. We explore data-sharing strategies and teacher-specific encoding, and introduce DUNE, a single encoder excelling in 2D vision, 3D understanding, and 3D human perception. Our model achieves performance comparable to that of its larger teachers, sometimes even outperforming them, on their respective tasks. Notably, DUNE surpasses MASt3R in Map-free Visual Relocalization with a much smaller encoder.
MASt3R-SfM: a Fully-Integrated Solution for Unconstrained Structure-from-Motion
Sep 27, 2024



Structure-from-Motion (SfM), a task aiming at jointly recovering camera poses and 3D geometry of a scene given a set of images, remains a hard problem with still many open challenges despite decades of significant progress. The traditional solution for SfM consists of a complex pipeline of minimal solvers which tends to propagate errors and fails when images do not sufficiently overlap, have too little motion, etc. Recent methods have attempted to revisit this paradigm, but we empirically show that they fall short of fixing these core issues. In this paper, we propose instead to build upon a recently released foundation model for 3D vision that can robustly produce local 3D reconstructions and accurate matches. We introduce a low-memory approach to accurately align these local reconstructions in a global coordinate system. We further show that such foundation models can serve as efficient image retrievers without any overhead, reducing the overall complexity from quadratic to linear. Overall, our novel SfM pipeline is simple, scalable, fast and truly unconstrained, i.e. it can handle any collection of images, ordered or not. Extensive experiments on multiple benchmarks show that our method provides steady performance across diverse settings, especially outperforming existing methods in small- and medium-scale settings.
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Sep 10, 2024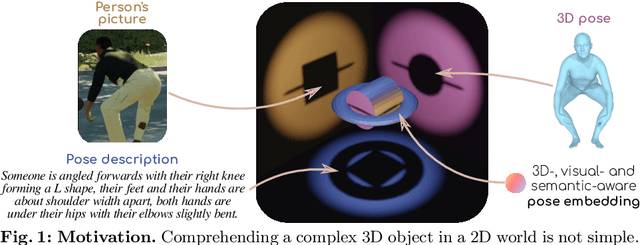
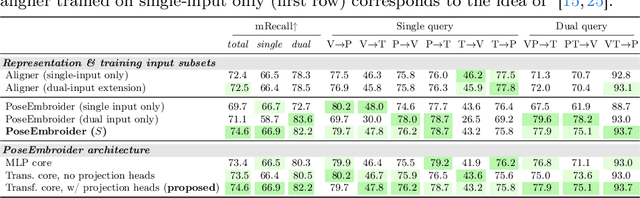
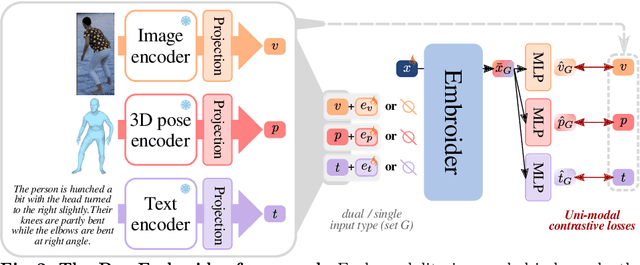
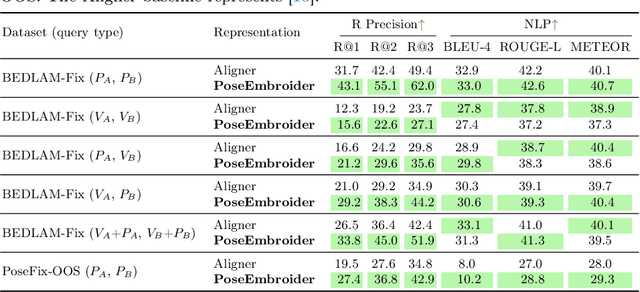
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
UNIC: Universal Classification Models via Multi-teacher Distillation
Aug 09, 2024Pretrained models have become a commodity and offer strong results on a broad range of tasks. In this work, we focus on classification and seek to learn a unique encoder able to take from several complementary pretrained models. We aim at even stronger generalization across a variety of classification tasks. We propose to learn such an encoder via multi-teacher distillation. We first thoroughly analyse standard distillation when driven by multiple strong teachers with complementary strengths. Guided by this analysis, we gradually propose improvements to the basic distillation setup. Among those, we enrich the architecture of the encoder with a ladder of expendable projectors, which increases the impact of intermediate features during distillation, and we introduce teacher dropping, a regularization mechanism that better balances the teachers' influence. Our final distillation strategy leads to student models of the same capacity as any of the teachers, while retaining or improving upon the performance of the best teacher for each task. Project page and code: https://europe.naverlabs.com/unic
Purposer: Putting Human Motion Generation in Context
Apr 19, 2024We present a novel method to generate human motion to populate 3D indoor scenes. It can be controlled with various combinations of conditioning signals such as a path in a scene, target poses, past motions, and scenes represented as 3D point clouds. State-of-the-art methods are either models specialized to one single setting, require vast amounts of high-quality and diverse training data, or are unconditional models that do not integrate scene or other contextual information. As a consequence, they have limited applicability and rely on costly training data. To address these limitations, we propose a new method ,dubbed Purposer, based on neural discrete representation learning. Our model is capable of exploiting, in a flexible manner, different types of information already present in open access large-scale datasets such as AMASS. First, we encode unconditional human motion into a discrete latent space. Second, an autoregressive generative model, conditioned with key contextual information, either with prompting or additive tokens, and trained for next-step prediction in this space, synthesizes sequences of latent indices. We further design a novel conditioning block to handle future conditioning information in such a causal model by using a network with two branches to compute separate stacks of features. In this manner, Purposer can generate realistic motion sequences in diverse test scenes. Through exhaustive evaluation, we demonstrate that our multi-contextual solution outperforms existing specialized approaches for specific contextual information, both in terms of quality and diversity. Our model is trained with short sequences, but a byproduct of being able to use various conditioning signals is that at test time different combinations can be used to chain short sequences together and generate long motions within a context scene.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024



We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
Weatherproofing Retrieval for Localization with Generative AI and Geometric Consistency
Feb 14, 2024



State-of-the-art visual localization approaches generally rely on a first image retrieval step whose role is crucial. Yet, retrieval often struggles when facing varying conditions, due to e.g. weather or time of day, with dramatic consequences on the visual localization accuracy. In this paper, we improve this retrieval step and tailor it to the final localization task. Among the several changes we advocate for, we propose to synthesize variants of the training set images, obtained from generative text-to-image models, in order to automatically expand the training set towards a number of nameable variations that particularly hurt visual localization. After expanding the training set, we propose a training approach that leverages the specificities and the underlying geometry of this mix of real and synthetic images. We experimentally show that those changes translate into large improvements for the most challenging visual localization datasets. Project page: https://europe.naverlabs.com/ret4loc