 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Sep 10, 2024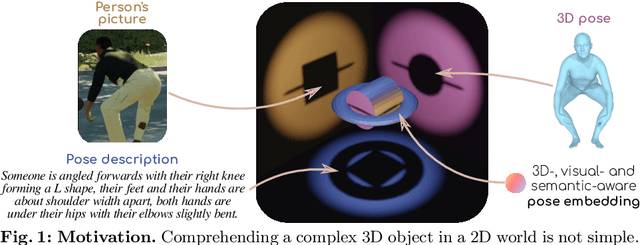
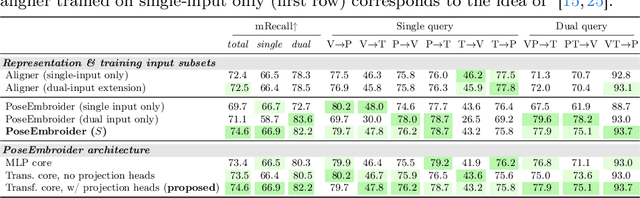
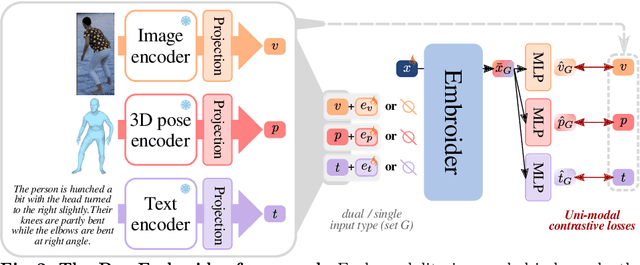
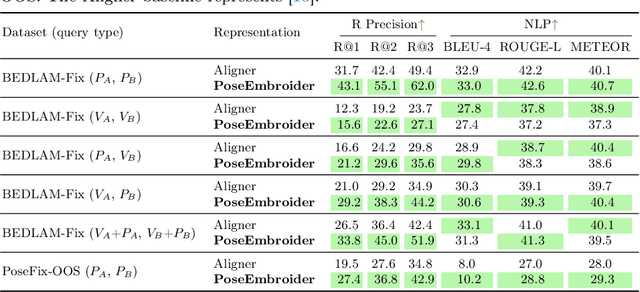
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024



We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
Cross-view and Cross-pose Completion for 3D Human Understanding
Nov 15, 2023



Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
PoseFix: Correcting 3D Human Poses with Natural Language
Sep 15, 2023Automatically producing instructions to modify one's posture could open the door to endless applications, such as personalized coaching and in-home physical therapy. Tackling the reverse problem (i.e., refining a 3D pose based on some natural language feedback) could help for assisted 3D character animation or robot teaching, for instance. Although a few recent works explore the connections between natural language and 3D human pose, none focus on describing 3D body pose differences. In this paper, we tackle the problem of correcting 3D human poses with natural language. To this end, we introduce the PoseFix dataset, which consists of several thousand paired 3D poses and their corresponding text feedback, that describe how the source pose needs to be modified to obtain the target pose. We demonstrate the potential of this dataset on two tasks: (1) text-based pose editing, that aims at generating corrected 3D body poses given a query pose and a text modifier; and (2) correctional text generation, where instructions are generated based on the differences between two body poses.
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting
Oct 19, 2022

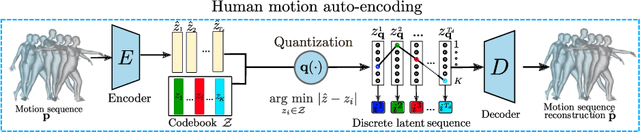
We address the problem of action-conditioned generation of human motion sequences. Existing work falls into two categories: forecast models conditioned on observed past motions, or generative models conditioned on action labels and duration only. In contrast, we generate motion conditioned on observations of arbitrary length, including none. To solve this generalized problem, we propose PoseGPT, an auto-regressive transformer-based approach which internally compresses human motion into quantized latent sequences. An auto-encoder first maps human motion to latent index sequences in a discrete space, and vice-versa. Inspired by the Generative Pretrained Transformer (GPT), we propose to train a GPT-like model for next-index prediction in that space; this allows PoseGPT to output distributions on possible futures, with or without conditioning on past motion. The discrete and compressed nature of the latent space allows the GPT-like model to focus on long-range signal, as it removes low-level redundancy in the input signal. Predicting discrete indices also alleviates the common pitfall of predicting averaged poses, a typical failure case when regressing continuous values, as the average of discrete targets is not a target itself. Our experimental results show that our proposed approach achieves state-of-the-art results on HumanAct12, a standard but small scale dataset, as well as on BABEL, a recent large scale MoCap dataset, and on GRAB, a human-object interactions dataset.
PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling
Aug 22, 2022
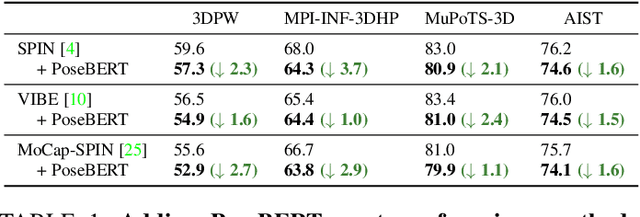
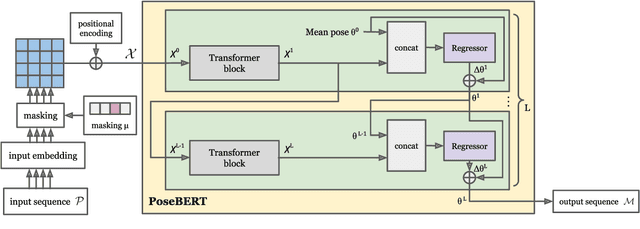
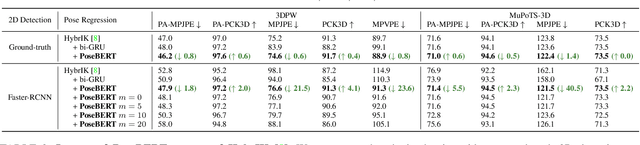
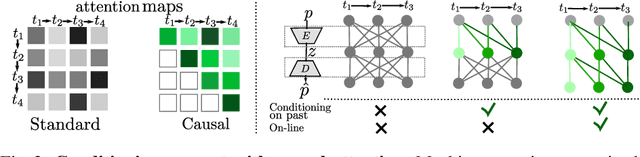
Training state-of-the-art models for human pose estimation in videos requires datasets with annotations that are really hard and expensive to obtain. Although transformers have been recently utilized for body pose sequence modeling, related methods rely on pseudo-ground truth to augment the currently limited training data available for learning such models. In this paper, we introduce PoseBERT, a transformer module that is fully trained on 3D Motion Capture (MoCap) data via masked modeling. It is simple, generic and versatile, as it can be plugged on top of any image-based model to transform it in a video-based model leveraging temporal information. We showcase variants of PoseBERT with different inputs varying from 3D skeleton keypoints to rotations of a 3D parametric model for either the full body (SMPL) or just the hands (MANO). Since PoseBERT training is task agnostic, the model can be applied to several tasks such as pose refinement, future pose prediction or motion completion without finetuning. Our experimental results validate that adding PoseBERT on top of various state-of-the-art pose estimation methods consistently improves their performances, while its low computational cost allows us to use it in a real-time demo for smoothly animating a robotic hand via a webcam. Test code and models are available at https://github.com/naver/posebert.
Make Some Noise: Reliable and Efficient Single-Step Adversarial Training
Feb 02, 2022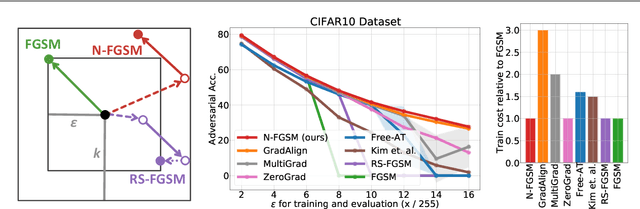
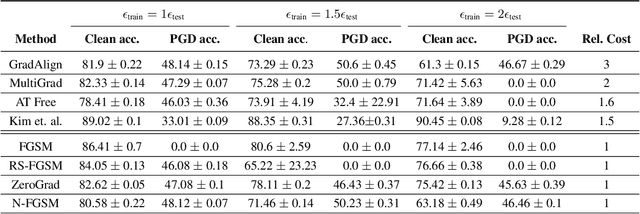
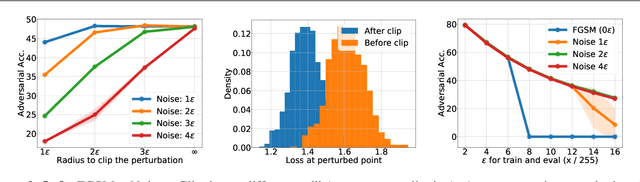
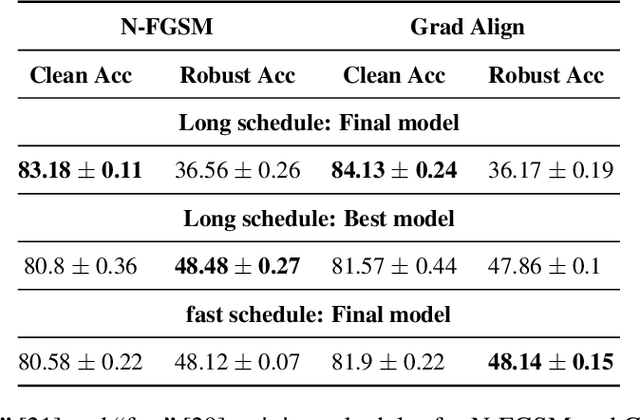
Recently, Wong et al. showed that adversarial training with single-step FGSM leads to a characteristic failure mode named catastrophic overfitting (CO), in which a model becomes suddenly vulnerable to multi-step attacks. They showed that adding a random perturbation prior to FGSM (RS-FGSM) seemed to be sufficient to prevent CO. However, Andriushchenko and Flammarion observed that RS-FGSM still leads to CO for larger perturbations, and proposed an expensive regularizer (GradAlign) to avoid CO. In this work, we methodically revisit the role of noise and clipping in single-step adversarial training. Contrary to previous intuitions, we find that using a stronger noise around the clean sample combined with not clipping is highly effective in avoiding CO for large perturbation radii. Based on these observations, we then propose Noise-FGSM (N-FGSM) that, while providing the benefits of single-step adversarial training, does not suffer from CO. Empirical analyses on a large suite of experiments show that N-FGSM is able to match or surpass the performance of previous single-step methods while achieving a 3$\times$ speed-up.
Leveraging MoCap Data for Human Mesh Recovery
Oct 18, 2021



Training state-of-the-art models for human body pose and shape recovery from images or videos requires datasets with corresponding annotations that are really hard and expensive to obtain. Our goal in this paper is to study whether poses from 3D Motion Capture (MoCap) data can be used to improve image-based and video-based human mesh recovery methods. We find that fine-tune image-based models with synthetic renderings from MoCap data can increase their performance, by providing them with a wider variety of poses, textures and backgrounds. In fact, we show that simply fine-tuning the batch normalization layers of the model is enough to achieve large gains. We further study the use of MoCap data for video, and introduce PoseBERT, a transformer module that directly regresses the pose parameters and is trained via masked modeling. It is simple, generic and can be plugged on top of any state-of-the-art image-based model in order to transform it in a video-based model leveraging temporal information. Our experimental results show that the proposed approaches reach state-of-the-art performance on various datasets including 3DPW, MPI-INF-3DHP, MuPoTS-3D, MCB and AIST. Test code and models will be available soon.
Continual Adaptation of Visual Representations via Domain Randomization and Meta-learning
Dec 08, 2020

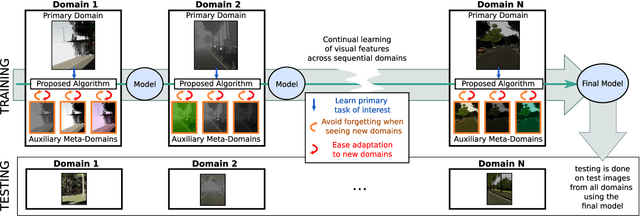

Most standard learning approaches lead to fragile models which are prone to drift when sequentially trained on samples of a different nature - the well-known "catastrophic forgetting" issue. In particular, when a model consecutively learns from different visual domains, it tends to forget the past ones in favor of the most recent. In this context, we show that one way to learn models that are inherently more robust against forgetting is domain randomization - for vision tasks, randomizing the current domain's distribution with heavy image manipulations. Building on this result, we devise a meta-learning strategy where a regularizer explicitly penalizes any loss associated with transferring the model from the current domain to different "auxiliary" meta-domains, while also easing adaptation to them. Such meta-domains, are also generated through randomized image manipulations. We empirically demonstrate in a variety of experiments - spanning from classification to semantic segmentation - that our approach results in models that are less prone to catastrophic forgetting when transferred to new domains.
SMPLy Benchmarking 3D Human Pose Estimation in the Wild
Dec 04, 2020
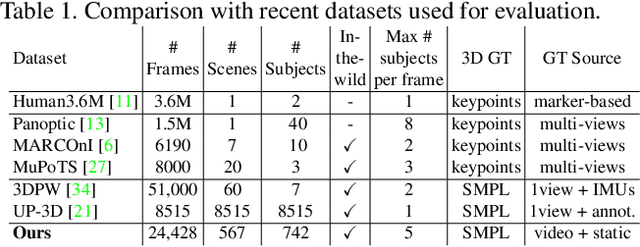

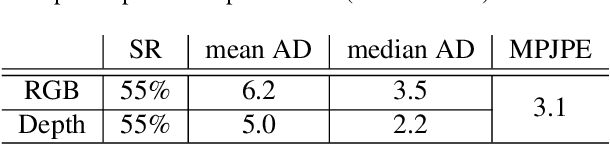
Predicting 3D human pose from images has seen great recent improvements. Novel approaches that can even predict both pose and shape from a single input image have been introduced, often relying on a parametric model of the human body such as SMPL. While qualitative results for such methods are often shown for images captured in-the-wild, a proper benchmark in such conditions is still missing, as it is cumbersome to obtain ground-truth 3D poses elsewhere than in a motion capture room. This paper presents a pipeline to easily produce and validate such a dataset with accurate ground-truth, with which we benchmark recent 3D human pose estimation methods in-the-wild. We make use of the recently introduced Mannequin Challenge dataset which contains in-the-wild videos of people frozen in action like statues and leverage the fact that people are static and the camera moving to accurately fit the SMPL model on the sequences. A total of 24,428 frames with registered body models are then selected from 567 scenes at almost no cost, using only online RGB videos. We benchmark state-of-the-art SMPL-based human pose estimation methods on this dataset. Our results highlight that challenges remain, in particular for difficult poses or for scenes where the persons are partially truncated or occluded.