 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormCoach: Lift Smarter, Not Harder
Aug 10, 2025Good form is the difference between strength and strain, yet for the fast-growing community of at-home fitness enthusiasts, expert feedback is often out of reach. FormCoach transforms a simple camera into an always-on, interactive AI training partner, capable of spotting subtle form errors and delivering tailored corrections in real time, leveraging vision-language models (VLMs). We showcase this capability through a web interface and benchmark state-of-the-art VLMs on a dataset of 1,700 expert-annotated user-reference video pairs spanning 22 strength and mobility exercises. To accelerate research in AI-driven coaching, we release both the dataset and an automated, rubric-based evaluation pipeline, enabling standardized comparison across models. Our benchmarks reveal substantial gaps compared to human-level coaching, underscoring both the challenges and opportunities in integrating nuanced, context-aware movement analysis into interactive AI systems. By framing form correction as a collaborative and creative process between humans and machines, FormCoach opens a new frontier in embodied AI.
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Sep 10, 2024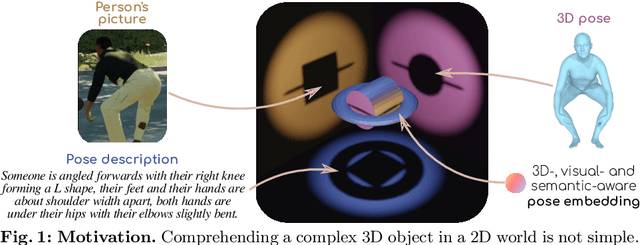
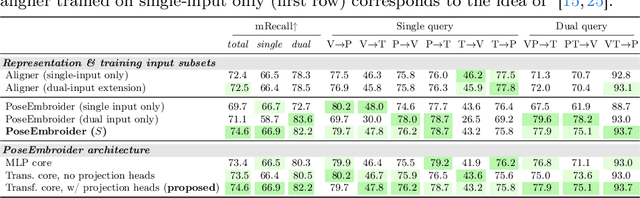
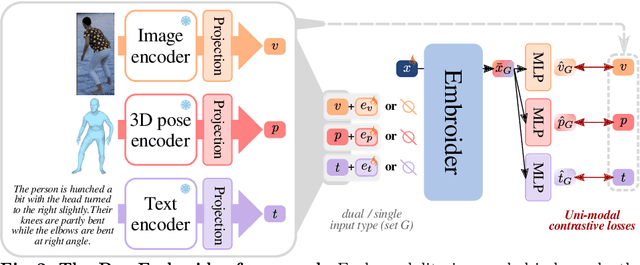
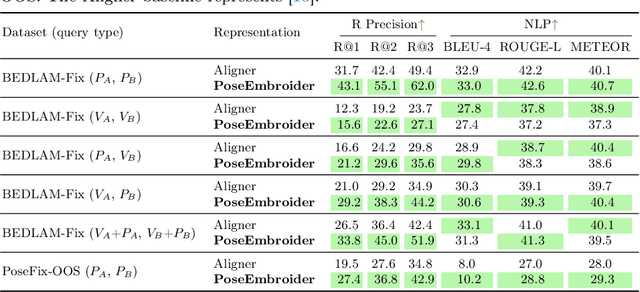
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
PoseFix: Correcting 3D Human Poses with Natural Language
Sep 15, 2023

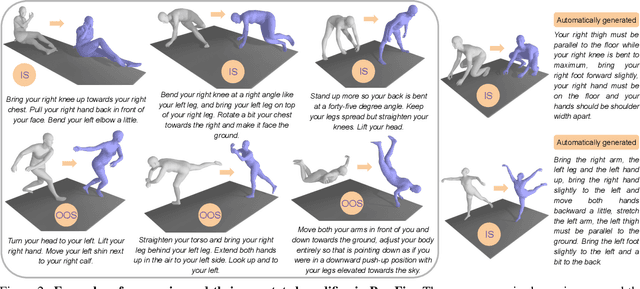
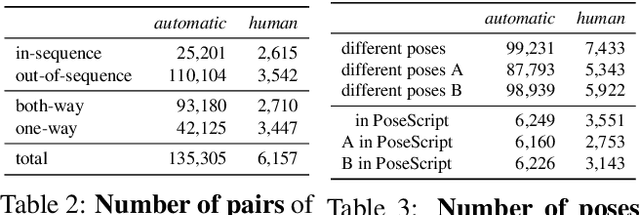
Automatically producing instructions to modify one's posture could open the door to endless applications, such as personalized coaching and in-home physical therapy. Tackling the reverse problem (i.e., refining a 3D pose based on some natural language feedback) could help for assisted 3D character animation or robot teaching, for instance. Although a few recent works explore the connections between natural language and 3D human pose, none focus on describing 3D body pose differences. In this paper, we tackle the problem of correcting 3D human poses with natural language. To this end, we introduce the PoseFix dataset, which consists of several thousand paired 3D poses and their corresponding text feedback, that describe how the source pose needs to be modified to obtain the target pose. We demonstrate the potential of this dataset on two tasks: (1) text-based pose editing, that aims at generating corrected 3D body poses given a query pose and a text modifier; and (2) correctional text generation, where instructions are generated based on the differences between two body poses.
ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity
Mar 15, 2022
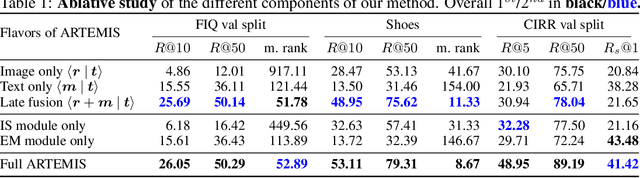
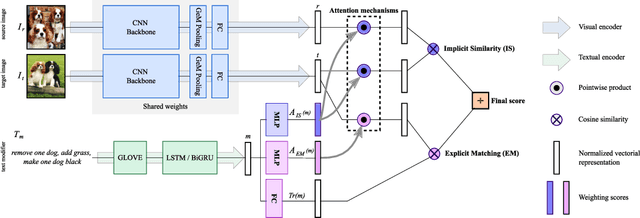
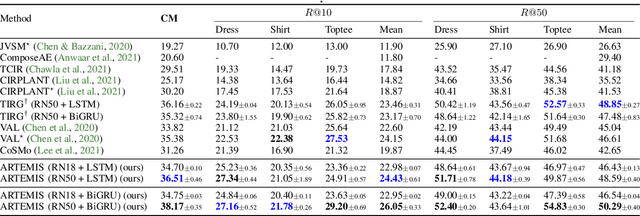
An intuitive way to search for images is to use queries composed of an example image and a complementary text. While the first provides rich and implicit context for the search, the latter explicitly calls for new traits, or specifies how some elements of the example image should be changed to retrieve the desired target image. Current approaches typically combine the features of each of the two elements of the query into a single representation, which can then be compared to the ones of the potential target images. Our work aims at shedding new light on the task by looking at it through the prism of two familiar and related frameworks: text-to-image and image-to-image retrieval. Taking inspiration from them, we exploit the specific relation of each query element with the targeted image and derive light-weight attention mechanisms which enable to mediate between the two complementary modalities. We validate our approach on several retrieval benchmarks, querying with images and their associated free-form text modifiers. Our method obtains state-of-the-art results without resorting to side information, multi-level features, heavy pre-training nor large architectures as in previous works.