 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Adaptation of Visual Representations via Domain Randomization and Meta-learning
Paper and Code


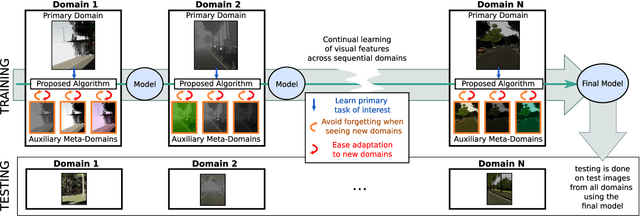

Most standard learning approaches lead to fragile models which are prone to drift when sequentially trained on samples of a different nature - the well-known "catastrophic forgetting" issue. In particular, when a model consecutively learns from different visual domains, it tends to forget the past ones in favor of the most recent. In this context, we show that one way to learn models that are inherently more robust against forgetting is domain randomization - for vision tasks, randomizing the current domain's distribution with heavy image manipulations. Building on this result, we devise a meta-learning strategy where a regularizer explicitly penalizes any loss associated with transferring the model from the current domain to different "auxiliary" meta-domains, while also easing adaptation to them. Such meta-domains, are also generated through randomized image manipulations. We empirically demonstrate in a variety of experiments - spanning from classification to semantic segmentation - that our approach results in models that are less prone to catastrophic forgetting when transferred to new domains.