 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-HMR 2: Multi-Person Camera-Centric Human Detection, Mesh Recovery and Tracking
Jun 12, 2026Most advances in human mesh recovery (HMR) have focused on pelvis-centered recovery, overlooking metric 3D localization and detection accuracy in the camera coordinate system - two key factors for real-world applications such as human-robot interaction and social scene understanding. Current evaluation protocols often ignore these aspects, emphasizing per-person, root-centered recovery rather than camera-space perception. As a result, existing approaches rely on fixed camera assumptions or handcrafted post-processing, limiting their robustness and practical deployment. We introduce Multi-HMR 2, a simple yet robust DETR-based framework for Multi-person Camera-centric Human detection, mesh Recovery, and tracking. Multi-HMR 2 predicts a scene-consistent camera together with human meshes, enabling metric 3D localization without ground-truth intrinsics. Moreover, by distilling image-based memory features from SAM2, Multi-HMR 2 extends to tracking, achieving consistent identity association without video supervision. Despite its conceptual simplicity - no handcrafted components, no video input, and no ground-truth cameras - Multi-HMR 2 achieves state-of-the-art pelvis-centered performance while substantially improving detection accuracy and metric 3D localization.
Anny-Fit: All-Age Human Mesh Recovery
May 06, 2026Recovering 3D human pose and shape from a single image remains a cornerstone of human-centric vision, yet most methods assume adult subjects and optimize each person independently. These assumptions fail in real-world, all-age scenes, where body proportions and depth must be resolved jointly. We introduce Anny-Fit, a multi-person, camera-space optimization framework for all-age 3D human mesh recovery (HMR). Unlike existing per-person fitting methods, Anny-Fit jointly optimizes all individuals directly in the camera coordinate system, enforcing global spatial consistency. At the core of our approach is the use of multiple forms of expert knowledge -- including metric depth maps, instance segmentation, 2D keypoints, and, VLM-derived semantic attributes such as age and gender -- each obtained from dedicated off-the-shelf networks. These complementary signals jointly guide the optimization, constraining the depth-scale ambiguity characteristic of all-age scenes. Across diverse datasets, Anny-Fit consistently improves 2D reprojection accuracy (+13 to 16), relative depth ordering (+6 to 7), 3D estimation error (-9 to -29) and shape estimation (+25 to +82), producing more coherent scenes. Finally, we show that VLM-based semantic knowledge can be distilled into an HMR model via the pseudo-ground-truth annotations produced by Anny-Fit on training data, enabling it to learn semantically meaningful shape parameters while improving HMR performance. Our approach bridges adult-only and all-age modeling by enabling zero-shot adaptation of adult-trained HMR pipelines to the full age spectrum without retraining. Code is publicly available at https://github.com/naver/anny-fit.
Human Mesh Modeling for Anny Body
Nov 05, 2025Parametric body models are central to many human-centric tasks, yet existing models often rely on costly 3D scans and learned shape spaces that are proprietary and demographically narrow. We introduce Anny, a simple, fully differentiable, and scan-free human body model grounded in anthropometric knowledge from the MakeHuman community. Anny defines a continuous, interpretable shape space, where phenotype parameters (e.g. gender, age, height, weight) control blendshapes spanning a wide range of human forms -- across ages (from infants to elders), body types, and proportions. Calibrated using WHO population statistics, it provides realistic and demographically grounded human shape variation within a single unified model. Thanks to its openness and semantic control, Anny serves as a versatile foundation for 3D human modeling -- supporting millimeter-accurate scan fitting, controlled synthetic data generation, and Human Mesh Recovery (HMR). We further introduce Anny-One, a collection of 800k photorealistic humans generated with Anny, showing that despite its simplicity, HMR models trained with Anny can match the performance of those trained with scan-based body models, while remaining interpretable and broadly representative. The Anny body model and its code are released under the Apache 2.0 license, making Anny an accessible foundation for human-centric 3D modeling.
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
Jun 02, 2024



In this paper, we address the challenging problem of long-term 3D human motion generation. Specifically, we aim to generate a long sequence of smoothly connected actions from a stream of multiple sentences (i.e., paragraph). Previous long-term motion generating approaches were mostly based on recurrent methods, using previously generated motion chunks as input for the next step. However, this approach has two drawbacks: 1) it relies on sequential datasets, which are expensive; 2) these methods yield unrealistic gaps between motions generated at each step. To address these issues, we introduce simple yet effective T2LM, a continuous long-term generation framework that can be trained without sequential data. T2LM comprises two components: a 1D-convolutional VQVAE, trained to compress motion to sequences of latent vectors, and a Transformer-based Text Encoder that predicts a latent sequence given an input text. At inference, a sequence of sentences is translated into a continuous stream of latent vectors. This is then decoded into a motion by the VQVAE decoder; the use of 1D convolutions with a local temporal receptive field avoids temporal inconsistencies between training and generated sequences. This simple constraint on the VQ-VAE allows it to be trained with short sequences only and produces smoother transitions. T2LM outperforms prior long-term generation models while overcoming the constraint of requiring sequential data; it is also competitive with SOTA single-action generation models.
Purposer: Putting Human Motion Generation in Context
Apr 19, 2024We present a novel method to generate human motion to populate 3D indoor scenes. It can be controlled with various combinations of conditioning signals such as a path in a scene, target poses, past motions, and scenes represented as 3D point clouds. State-of-the-art methods are either models specialized to one single setting, require vast amounts of high-quality and diverse training data, or are unconditional models that do not integrate scene or other contextual information. As a consequence, they have limited applicability and rely on costly training data. To address these limitations, we propose a new method ,dubbed Purposer, based on neural discrete representation learning. Our model is capable of exploiting, in a flexible manner, different types of information already present in open access large-scale datasets such as AMASS. First, we encode unconditional human motion into a discrete latent space. Second, an autoregressive generative model, conditioned with key contextual information, either with prompting or additive tokens, and trained for next-step prediction in this space, synthesizes sequences of latent indices. We further design a novel conditioning block to handle future conditioning information in such a causal model by using a network with two branches to compute separate stacks of features. In this manner, Purposer can generate realistic motion sequences in diverse test scenes. Through exhaustive evaluation, we demonstrate that our multi-contextual solution outperforms existing specialized approaches for specific contextual information, both in terms of quality and diversity. Our model is trained with short sequences, but a byproduct of being able to use various conditioning signals is that at test time different combinations can be used to chain short sequences together and generate long motions within a context scene.
Multi-HMR: Multi-Person Whole-Body Human Mesh Recovery in a Single Shot
Feb 22, 2024



We present Multi-HMR, a strong single-shot model for multi-person 3D human mesh recovery from a single RGB image. Predictions encompass the whole body, i.e, including hands and facial expressions, using the SMPL-X parametric model and spatial location in the camera coordinate system. Our model detects people by predicting coarse 2D heatmaps of person centers, using features produced by a standard Vision Transformer (ViT) backbone. It then predicts their whole-body pose, shape and spatial location using a new cross-attention module called the Human Prediction Head (HPH), with one query per detected center token, attending to the entire set of features. As direct prediction of SMPL-X parameters yields suboptimal results, we introduce CUFFS; the Close-Up Frames of Full-Body Subjects dataset, containing humans close to the camera with diverse hand poses. We show that incorporating this dataset into training further enhances predictions, particularly for hands, enabling us to achieve state-of-the-art performance. Multi-HMR also optionally accounts for camera intrinsics, if available, by encoding camera ray directions for each image token. This simple design achieves strong performance on whole-body and body-only benchmarks simultaneously. We train models with various backbone sizes and input resolutions. In particular, using a ViT-S backbone and $448\times448$ input images already yields a fast and competitive model with respect to state-of-the-art methods, while considering larger models and higher resolutions further improve performance.
Cross-view and Cross-pose Completion for 3D Human Understanding
Nov 15, 2023



Human perception and understanding is a major domain of computer vision which, like many other vision subdomains recently, stands to gain from the use of large models pre-trained on large datasets. We hypothesize that the most common pre-training strategy of relying on general purpose, object-centric image datasets such as ImageNet, is limited by an important domain shift. On the other hand, collecting domain specific ground truth such as 2D or 3D labels does not scale well. Therefore, we propose a pre-training approach based on self-supervised learning that works on human-centric data using only images. Our method uses pairs of images of humans: the first is partially masked and the model is trained to reconstruct the masked parts given the visible ones and a second image. It relies on both stereoscopic (cross-view) pairs, and temporal (cross-pose) pairs taken from videos, in order to learn priors about 3D as well as human motion. We pre-train a model for body-centric tasks and one for hand-centric tasks. With a generic transformer architecture, these models outperform existing self-supervised pre-training methods on a wide set of human-centric downstream tasks, and obtain state-of-the-art performance for instance when fine-tuning for model-based and model-free human mesh recovery.
SHOWMe: Benchmarking Object-agnostic Hand-Object 3D Reconstruction
Sep 19, 2023Recent hand-object interaction datasets show limited real object variability and rely on fitting the MANO parametric model to obtain groundtruth hand shapes. To go beyond these limitations and spur further research, we introduce the SHOWMe dataset which consists of 96 videos, annotated with real and detailed hand-object 3D textured meshes. Following recent work, we consider a rigid hand-object scenario, in which the pose of the hand with respect to the object remains constant during the whole video sequence. This assumption allows us to register sub-millimetre-precise groundtruth 3D scans to the image sequences in SHOWMe. Although simpler, this hypothesis makes sense in terms of applications where the required accuracy and level of detail is important eg., object hand-over in human-robot collaboration, object scanning, or manipulation and contact point analysis. Importantly, the rigidity of the hand-object systems allows to tackle video-based 3D reconstruction of unknown hand-held objects using a 2-stage pipeline consisting of a rigid registration step followed by a multi-view reconstruction (MVR) part. We carefully evaluate a set of non-trivial baselines for these two stages and show that it is possible to achieve promising object-agnostic 3D hand-object reconstructions employing an SfM toolbox or a hand pose estimator to recover the rigid transforms and off-the-shelf MVR algorithms. However, these methods remain sensitive to the initial camera pose estimates which might be imprecise due to lack of textures on the objects or heavy occlusions of the hands, leaving room for improvements in the reconstruction. Code and dataset are available at https://europe.naverlabs.com/research/showme
PoseGPT: Quantization-based 3D Human Motion Generation and Forecasting
Oct 19, 2022

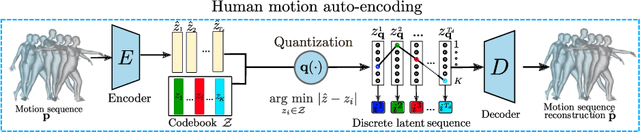
We address the problem of action-conditioned generation of human motion sequences. Existing work falls into two categories: forecast models conditioned on observed past motions, or generative models conditioned on action labels and duration only. In contrast, we generate motion conditioned on observations of arbitrary length, including none. To solve this generalized problem, we propose PoseGPT, an auto-regressive transformer-based approach which internally compresses human motion into quantized latent sequences. An auto-encoder first maps human motion to latent index sequences in a discrete space, and vice-versa. Inspired by the Generative Pretrained Transformer (GPT), we propose to train a GPT-like model for next-index prediction in that space; this allows PoseGPT to output distributions on possible futures, with or without conditioning on past motion. The discrete and compressed nature of the latent space allows the GPT-like model to focus on long-range signal, as it removes low-level redundancy in the input signal. Predicting discrete indices also alleviates the common pitfall of predicting averaged poses, a typical failure case when regressing continuous values, as the average of discrete targets is not a target itself. Our experimental results show that our proposed approach achieves state-of-the-art results on HumanAct12, a standard but small scale dataset, as well as on BABEL, a recent large scale MoCap dataset, and on GRAB, a human-object interactions dataset.
PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling
Aug 22, 2022
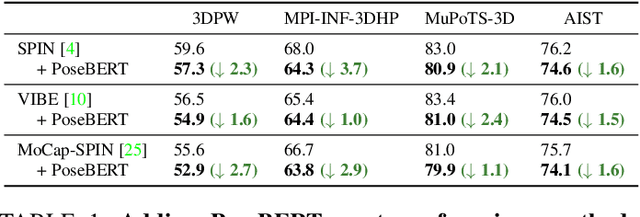
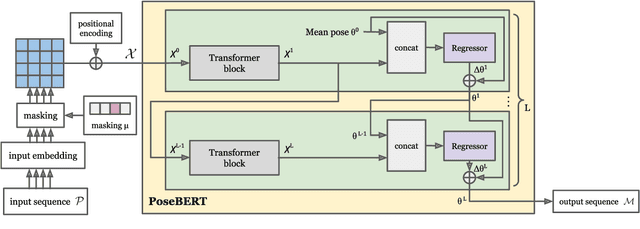
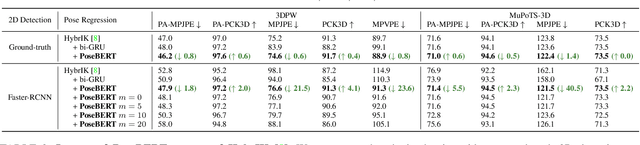
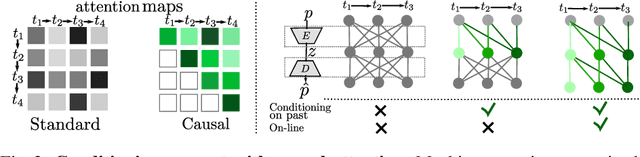
Training state-of-the-art models for human pose estimation in videos requires datasets with annotations that are really hard and expensive to obtain. Although transformers have been recently utilized for body pose sequence modeling, related methods rely on pseudo-ground truth to augment the currently limited training data available for learning such models. In this paper, we introduce PoseBERT, a transformer module that is fully trained on 3D Motion Capture (MoCap) data via masked modeling. It is simple, generic and versatile, as it can be plugged on top of any image-based model to transform it in a video-based model leveraging temporal information. We showcase variants of PoseBERT with different inputs varying from 3D skeleton keypoints to rotations of a 3D parametric model for either the full body (SMPL) or just the hands (MANO). Since PoseBERT training is task agnostic, the model can be applied to several tasks such as pose refinement, future pose prediction or motion completion without finetuning. Our experimental results validate that adding PoseBERT on top of various state-of-the-art pose estimation methods consistently improves their performances, while its low computational cost allows us to use it in a real-time demo for smoothly animating a robotic hand via a webcam. Test code and models are available at https://github.com/naver/posebert.