 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPHY: Counterfactual Learning of Physical Dynamics
Sep 26, 2019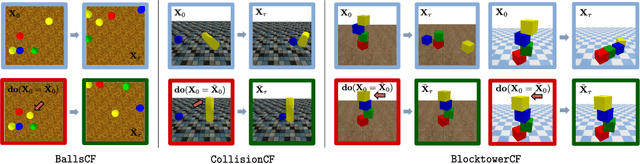
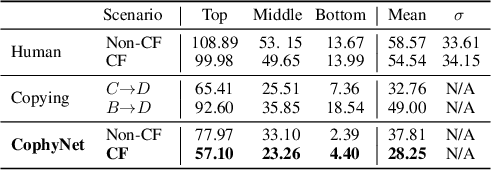
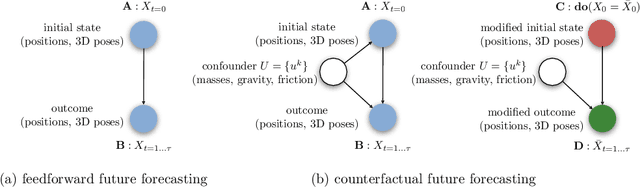
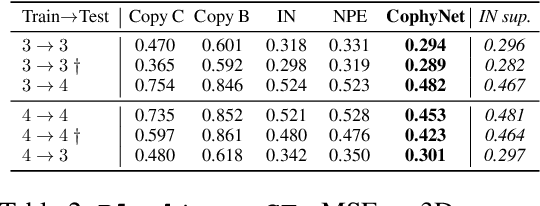
Understanding causes and effects in mechanical systems is an essential component of reasoning in the physical world. This work poses a new problem of counterfactual learning of object mechanics from visual input. We develop the COPHY benchmark to assess the capacity of the state-of-the-art models for causal physical reasoning in a synthetic 3D environment and propose a model for learning the physical dynamics in a counterfactual setting. Having observed a mechanical experiment that involves, for example, a falling tower of blocks, a set of bouncing balls or colliding objects, we learn to predict how its outcome is affected by an arbitrary intervention on its initial conditions, such as displacing one of the objects in the scene. The alternative future is predicted given the altered past and a latent representation of the confounders learned by the model in an end-to-end fashion with no supervision. We compare against feedforward video prediction baselines and show how observing alternative experiences allows the network to capture latent physical properties of the environment, which results in significantly more accurate predictions at the level of super human performance.
Object Level Visual Reasoning in Videos
Sep 20, 2018

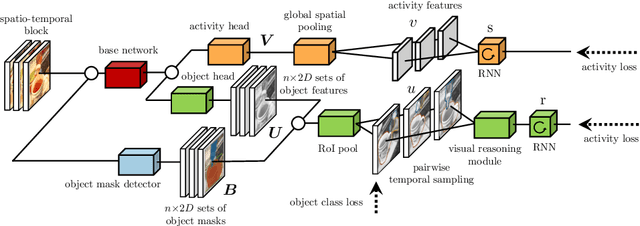
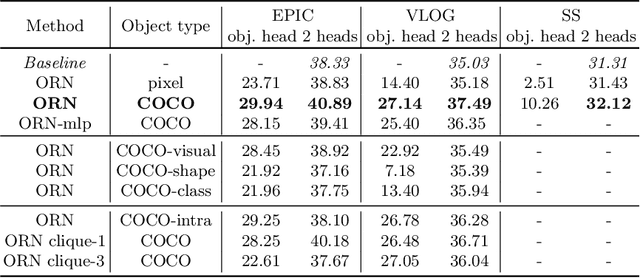
Human activity recognition is typically addressed by detecting key concepts like global and local motion, features related to object classes present in the scene, as well as features related to the global context. The next open challenges in activity recognition require a level of understanding that pushes beyond this and call for models with capabilities for fine distinction and detailed comprehension of interactions between actors and objects in a scene. We propose a model capable of learning to reason about semantically meaningful spatiotemporal interactions in videos. The key to our approach is a choice of performing this reasoning at the object level through the integration of state of the art object detection networks. This allows the model to learn detailed spatial interactions that exist at a semantic, object-interaction relevant level. We evaluate our method on three standard datasets (Twenty-BN Something-Something, VLOG and EPIC Kitchens) and achieve state of the art results on all of them. Finally, we show visualizations of the interactions learned by the model, which illustrate object classes and their interactions corresponding to different activity classes.
* Accepted at ECCV 2018 - long version (16 pages + ref)
Glimpse Clouds: Human Activity Recognition from Unstructured Feature Points
Aug 21, 2018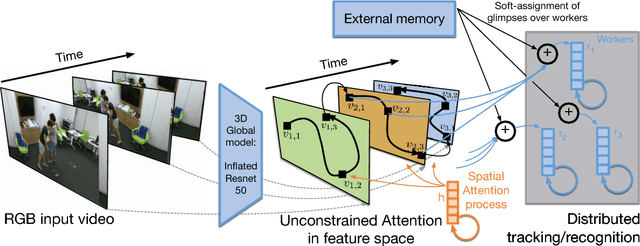
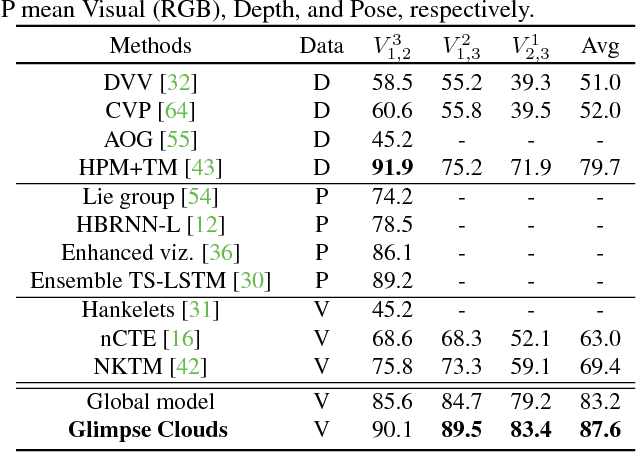
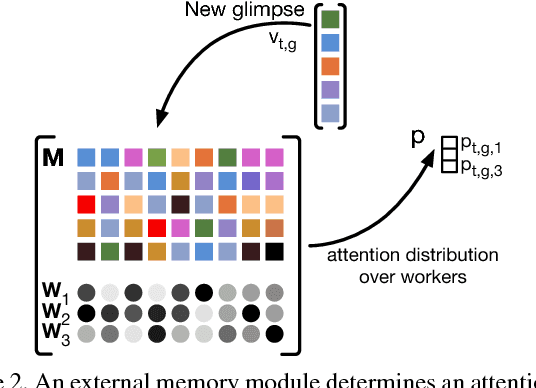
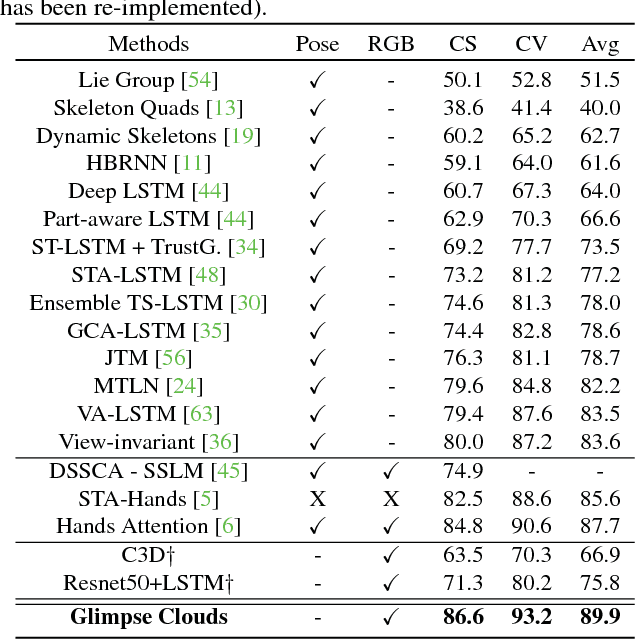
We propose a method for human activity recognition from RGB data that does not rely on any pose information during test time and does not explicitly calculate pose information internally. Instead, a visual attention module learns to predict glimpse sequences in each frame. These glimpses correspond to interest points in the scene that are relevant to the classified activities. No spatial coherence is forced on the glimpse locations, which gives the module liberty to explore different points at each frame and better optimize the process of scrutinizing visual information. Tracking and sequentially integrating this kind of unstructured data is a challenge, which we address by separating the set of glimpses from a set of recurrent tracking/recognition workers. These workers receive glimpses, jointly performing subsequent motion tracking and activity prediction. The glimpses are soft-assigned to the workers, optimizing coherence of the assignments in space, time and feature space using an external memory module. No hard decisions are taken, i.e. each glimpse point is assigned to all existing workers, albeit with different importance. Our methods outperform state-of-the-art methods on the largest human activity recognition dataset available to-date; NTU RGB+D Dataset, and on a smaller human action recognition dataset Northwestern-UCLA Multiview Action 3D Dataset. Our code is publicly available at https://github.com/fabienbaradel/glimpse_clouds.
* CVPR 2018 - project page: https://fabienbaradel.github.io/cvpr18_glimpseclouds/
Human Action Recognition: Pose-based Attention draws focus to Hands
Dec 20, 2017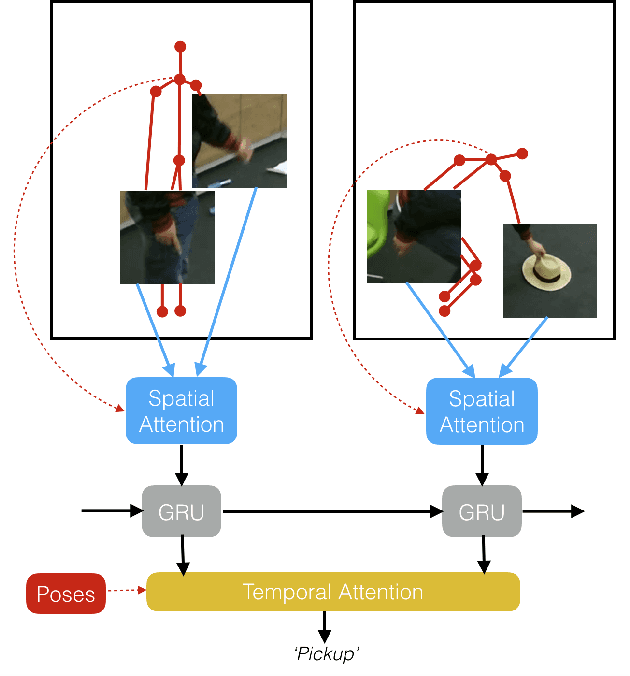
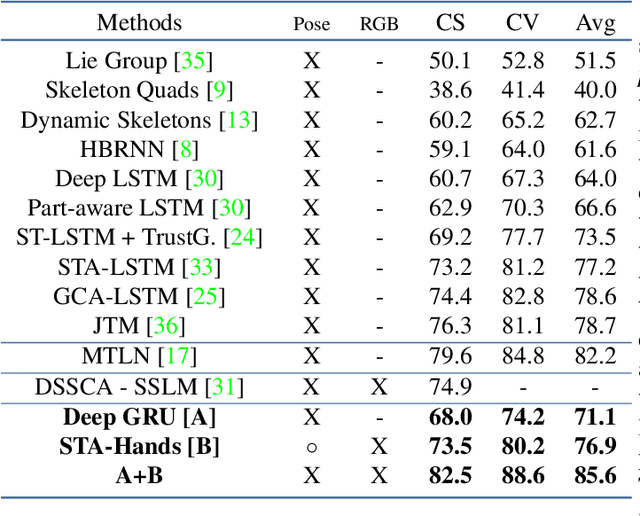
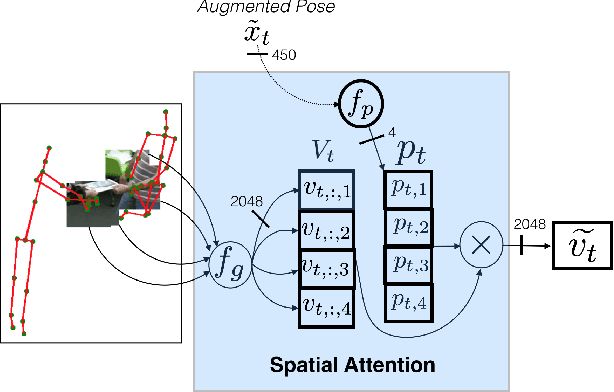
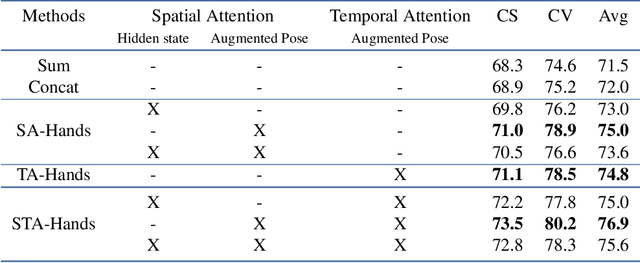
We propose a new spatio-temporal attention based mechanism for human action recognition able to automatically attend to the hands most involved into the studied action and detect the most discriminative moments in an action. Attention is handled in a recurrent manner employing Recurrent Neural Network (RNN) and is fully-differentiable. In contrast to standard soft-attention based mechanisms, our approach does not use the hidden RNN state as input to the attention model. Instead, attention distributions are extracted using external information: human articulated pose. We performed an extensive ablation study to show the strengths of this approach and we particularly studied the conditioning aspect of the attention mechanism. We evaluate the method on the largest currently available human action recognition dataset, NTU-RGB+D, and report state-of-the-art results. Other advantages of our model are certain aspects of explanability, as the spatial and temporal attention distributions at test time allow to study and verify on which parts of the input data the method focuses.
* ICCV 2017 Workshop "Hands in action". arXiv admin note: text overlap with arXiv:1703.10106
Pose-conditioned Spatio-Temporal Attention for Human Action Recognition
Aug 07, 2017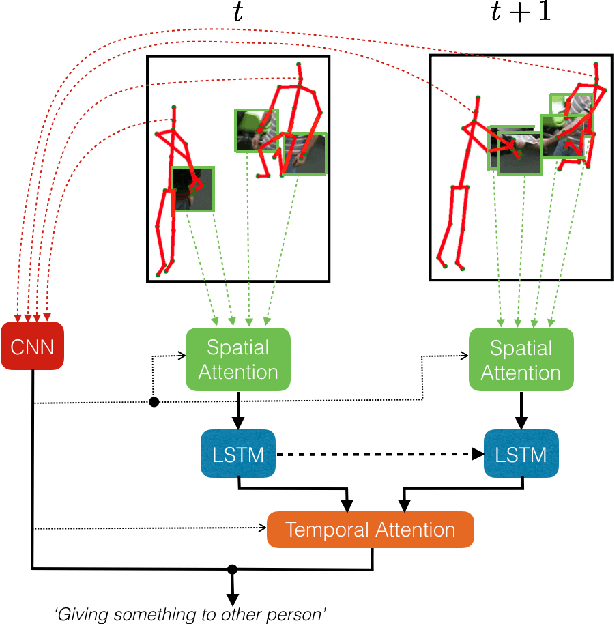
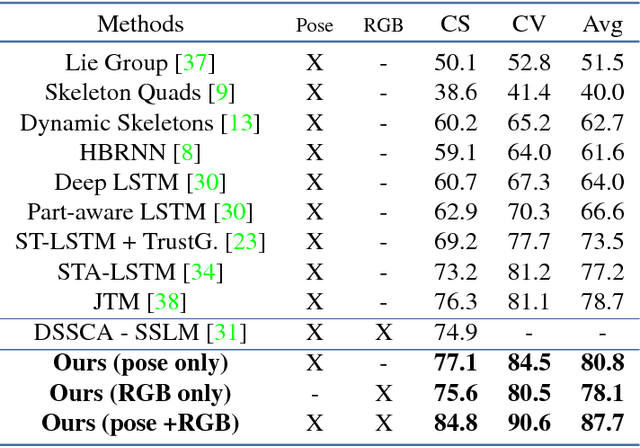
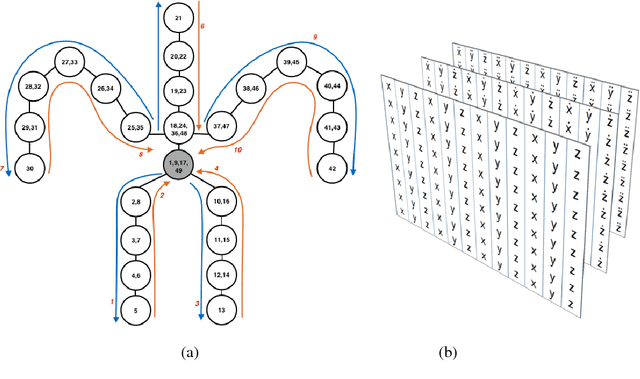
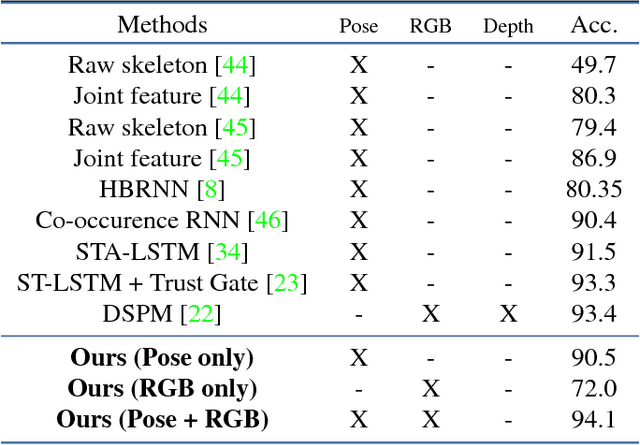
We address human action recognition from multi-modal video data involving articulated pose and RGB frames and propose a two-stream approach. The pose stream is processed with a convolutional model taking as input a 3D tensor holding data from a sub-sequence. A specific joint ordering, which respects the topology of the human body, ensures that different convolutional layers correspond to meaningful levels of abstraction. The raw RGB stream is handled by a spatio-temporal soft-attention mechanism conditioned on features from the pose network. An LSTM network receives input from a set of image locations at each instant. A trainable glimpse sensor extracts features on a set of predefined locations specified by the pose stream, namely the 4 hands of the two people involved in the activity. Appearance features give important cues on hand motion and on objects held in each hand. We show that it is of high interest to shift the attention to different hands at different time steps depending on the activity itself. Finally a temporal attention mechanism learns how to fuse LSTM features over time. We evaluate the method on 3 datasets. State-of-the-art results are achieved on the largest dataset for human activity recognition, namely NTU-RGB+D, as well as on the SBU Kinect Interaction dataset. Performance close to state-of-the-art is achieved on the smaller MSR Daily Activity 3D dataset.
Linear Algorithm for Digital Euclidean Connected Skeleton
Jun 02, 2014The skeleton is an essential shape characteristic providing a compact representation of the studied shape. Its computation on the image grid raises many issues. Due to the effects of discretization, the required properties of the skeleton - thinness, homotopy to the shape, reversibility, connectivity - may become incompatible. However, as regards practical use, the choice of a specific skeletonization algorithm depends on the application. This allows to classify the desired properties by order of importance, and tend towards the most critical ones. Our goal is to make a skeleton dedicated to shape matching for recognition. So, the discrete skeleton has to be thin - so that it can be represented by a graph -, robust to noise, reversible - so that the initial shape can be fully reconstructed - and homotopic to the shape. We propose a linear-time skeletonization algorithm based on the squared Euclidean distance map from which we extract the maximal balls and ridges. After a thinning and pruning process, we obtain the skeleton. The proposed method is finally compared to fairly recent methods.