 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLOS: Sign Language Generation with Temporally Aligned Gloss-Level Conditioning
Jun 09, 2025Sign language generation (SLG), or text-to-sign generation, bridges the gap between signers and non-signers. Despite recent progress in SLG, existing methods still often suffer from incorrect lexical ordering and low semantic accuracy. This is primarily due to sentence-level condition, which encodes the entire sentence of the input text into a single feature vector as a condition for SLG. This approach fails to capture the temporal structure of sign language and lacks the granularity of word-level semantics, often leading to disordered sign sequences and ambiguous motions. To overcome these limitations, we propose GLOS, a sign language generation framework with temporally aligned gloss-level conditioning. First, we employ gloss-level conditions, which we define as sequences of gloss embeddings temporally aligned with the motion sequence. This enables the model to access both the temporal structure of sign language and word-level semantics at each timestep. As a result, this allows for fine-grained control of signs and better preservation of lexical order. Second, we introduce a condition fusion module, temporal alignment conditioning (TAC), to efficiently deliver the word-level semantic and temporal structure provided by the gloss-level condition to the corresponding motion timesteps. Our method, which is composed of gloss-level conditions and TAC, generates signs with correct lexical order and high semantic accuracy, outperforming prior methods on CSL-Daily and Phoenix-2014T.
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
Jun 02, 2024



In this paper, we address the challenging problem of long-term 3D human motion generation. Specifically, we aim to generate a long sequence of smoothly connected actions from a stream of multiple sentences (i.e., paragraph). Previous long-term motion generating approaches were mostly based on recurrent methods, using previously generated motion chunks as input for the next step. However, this approach has two drawbacks: 1) it relies on sequential datasets, which are expensive; 2) these methods yield unrealistic gaps between motions generated at each step. To address these issues, we introduce simple yet effective T2LM, a continuous long-term generation framework that can be trained without sequential data. T2LM comprises two components: a 1D-convolutional VQVAE, trained to compress motion to sequences of latent vectors, and a Transformer-based Text Encoder that predicts a latent sequence given an input text. At inference, a sequence of sentences is translated into a continuous stream of latent vectors. This is then decoded into a motion by the VQVAE decoder; the use of 1D convolutions with a local temporal receptive field avoids temporal inconsistencies between training and generated sequences. This simple constraint on the VQ-VAE allows it to be trained with short sequences only and produces smoother transitions. T2LM outperforms prior long-term generation models while overcoming the constraint of requiring sequential data; it is also competitive with SOTA single-action generation models.
Human Part-wise 3D Motion Context Learning for Sign Language Recognition
Aug 18, 2023



In this paper, we propose P3D, the human part-wise motion context learning framework for sign language recognition. Our main contributions lie in two dimensions: learning the part-wise motion context and employing the pose ensemble to utilize 2D and 3D pose jointly. First, our empirical observation implies that part-wise context encoding benefits the performance of sign language recognition. While previous methods of sign language recognition learned motion context from the sequence of the entire pose, we argue that such methods cannot exploit part-specific motion context. In order to utilize part-wise motion context, we propose the alternating combination of a part-wise encoding Transformer (PET) and a whole-body encoding Transformer (WET). PET encodes the motion contexts from a part sequence, while WET merges them into a unified context. By learning part-wise motion context, our P3D achieves superior performance on WLASL compared to previous state-of-the-art methods. Second, our framework is the first to ensemble 2D and 3D poses for sign language recognition. Since the 3D pose holds rich motion context and depth information to distinguish the words, our P3D outperformed the previous state-of-the-art methods employing a pose ensemble.
Rethinking Self-Supervised Visual Representation Learning in Pre-training for 3D Human Pose and Shape Estimation
Mar 09, 2023



Recently, a few self-supervised representation learning (SSL) methods have outperformed the ImageNet classification pre-training for vision tasks such as object detection. However, its effects on 3D human body pose and shape estimation (3DHPSE) are open to question, whose target is fixed to a unique class, the human, and has an inherent task gap with SSL. We empirically study and analyze the effects of SSL and further compare it with other pre-training alternatives for 3DHPSE. The alternatives are 2D annotation-based pre-training and synthetic data pre-training, which share the motivation of SSL that aims to reduce the labeling cost. They have been widely utilized as a source of weak-supervision or fine-tuning, but have not been remarked as a pre-training source. SSL methods underperform the conventional ImageNet classification pre-training on multiple 3DHPSE benchmarks by 7.7% on average. In contrast, despite a much less amount of pre-training data, the 2D annotation-based pre-training improves accuracy on all benchmarks and shows faster convergence during fine-tuning. Our observations challenge the naive application of the current SSL pre-training to 3DHPSE and relight the value of other data types in the pre-training aspect.
MultiAct: Long-Term 3D Human Motion Generation from Multiple Action Labels
Dec 12, 2022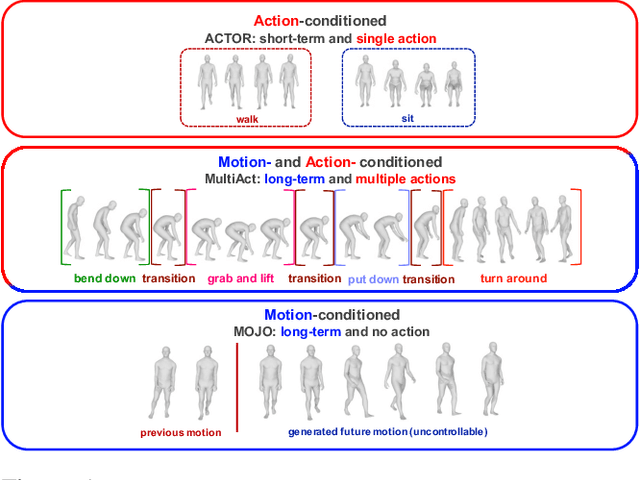
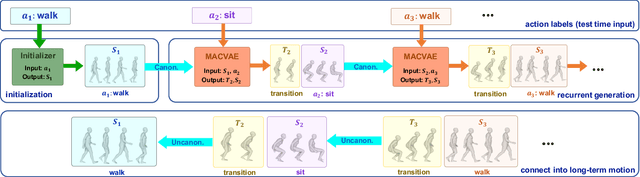

We tackle the problem of generating long-term 3D human motion from multiple action labels. Two main previous approaches, such as action- and motion-conditioned methods, have limitations to solve this problem. The action-conditioned methods generate a sequence of motion from a single action. Hence, it cannot generate long-term motions composed of multiple actions and transitions between actions. Meanwhile, the motion-conditioned methods generate future motions from initial motion. The generated future motions only depend on the past, so they are not controllable by the user's desired actions. We present MultiAct, the first framework to generate long-term 3D human motion from multiple action labels. MultiAct takes account of both action and motion conditions with a unified recurrent generation system. It repetitively takes the previous motion and action label; then, it generates a smooth transition and the motion of the given action. As a result, MultiAct produces realistic long-term motion controlled by the given sequence of multiple action labels. The code will be released.