 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVortSDF: 3D Modeling with Centroidal Voronoi Tesselation on Signed Distance Field
Jul 29, 2024Volumetric shape representations have become ubiquitous in multi-view reconstruction tasks. They often build on regular voxel grids as discrete representations of 3D shape functions, such as SDF or radiance fields, either as the full shape model or as sampled instantiations of continuous representations, as with neural networks. Despite their proven efficiency, voxel representations come with the precision versus complexity trade-off. This inherent limitation can significantly impact performance when moving away from simple and uncluttered scenes. In this paper we investigate an alternative discretization strategy with the Centroidal Voronoi Tesselation (CVT). CVTs allow to better partition the observation space with respect to shape occupancy and to focus the discretization around shape surfaces. To leverage this discretization strategy for multi-view reconstruction, we introduce a volumetric optimization framework that combines explicit SDF fields with a shallow color network, in order to estimate 3D shape properties over tetrahedral grids. Experimental results with Chamfer statistics validate this approach with unprecedented reconstruction quality on various scenarios such as objects, open scenes or human.
SHOWMe: Benchmarking Object-agnostic Hand-Object 3D Reconstruction
Sep 19, 2023Recent hand-object interaction datasets show limited real object variability and rely on fitting the MANO parametric model to obtain groundtruth hand shapes. To go beyond these limitations and spur further research, we introduce the SHOWMe dataset which consists of 96 videos, annotated with real and detailed hand-object 3D textured meshes. Following recent work, we consider a rigid hand-object scenario, in which the pose of the hand with respect to the object remains constant during the whole video sequence. This assumption allows us to register sub-millimetre-precise groundtruth 3D scans to the image sequences in SHOWMe. Although simpler, this hypothesis makes sense in terms of applications where the required accuracy and level of detail is important eg., object hand-over in human-robot collaboration, object scanning, or manipulation and contact point analysis. Importantly, the rigidity of the hand-object systems allows to tackle video-based 3D reconstruction of unknown hand-held objects using a 2-stage pipeline consisting of a rigid registration step followed by a multi-view reconstruction (MVR) part. We carefully evaluate a set of non-trivial baselines for these two stages and show that it is possible to achieve promising object-agnostic 3D hand-object reconstructions employing an SfM toolbox or a hand pose estimator to recover the rigid transforms and off-the-shelf MVR algorithms. However, these methods remain sensitive to the initial camera pose estimates which might be imprecise due to lack of textures on the objects or heavy occlusions of the hands, leaving room for improvements in the reconstruction. Code and dataset are available at https://europe.naverlabs.com/research/showme
4DHumanOutfit: a multi-subject 4D dataset of human motion sequences in varying outfits exhibiting large displacements
Jun 12, 2023
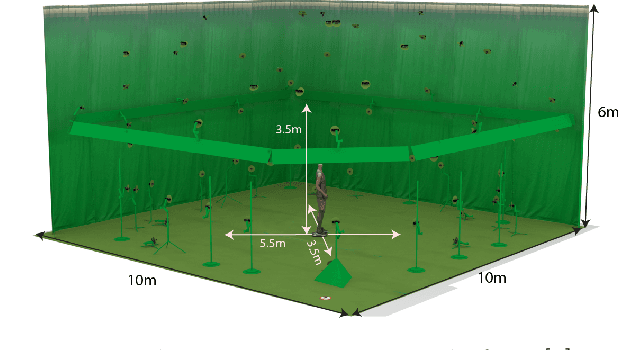

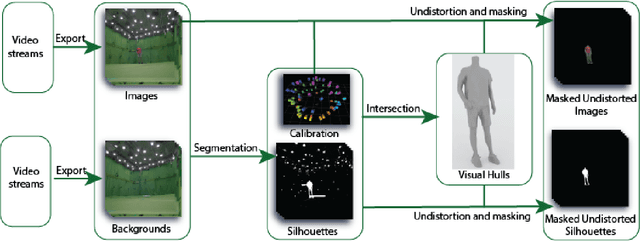
This work presents 4DHumanOutfit, a new dataset of densely sampled spatio-temporal 4D human motion data of different actors, outfits and motions. The dataset is designed to contain different actors wearing different outfits while performing different motions in each outfit. In this way, the dataset can be seen as a cube of data containing 4D motion sequences along 3 axes with identity, outfit and motion. This rich dataset has numerous potential applications for the processing and creation of digital humans, e.g. augmented reality, avatar creation and virtual try on. 4DHumanOutfit is released for research purposes at https://kinovis.inria.fr/4dhumanoutfit/. In addition to image data and 4D reconstructions, the dataset includes reference solutions for each axis. We present independent baselines along each axis that demonstrate the value of these reference solutions for evaluation tasks.
Spatio-temporal motion completion using a sequence of latent primitives
Jun 27, 2022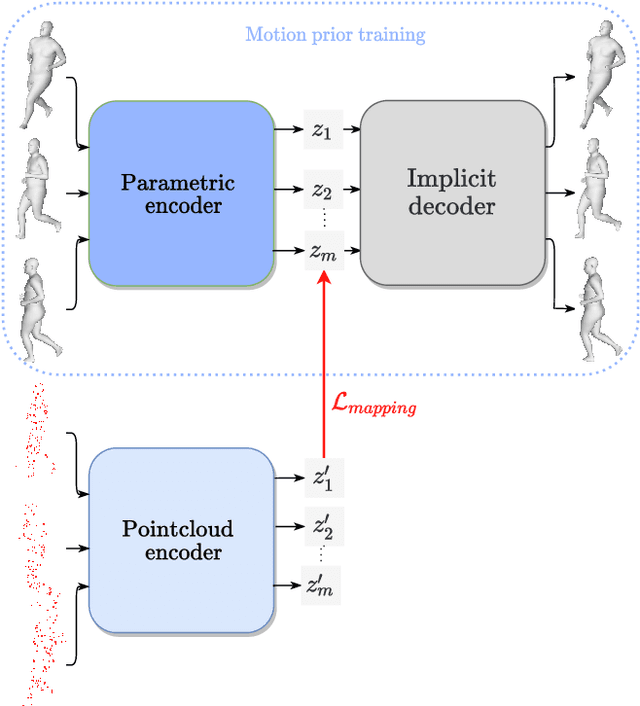
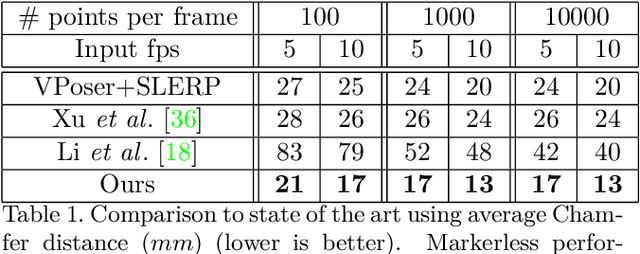
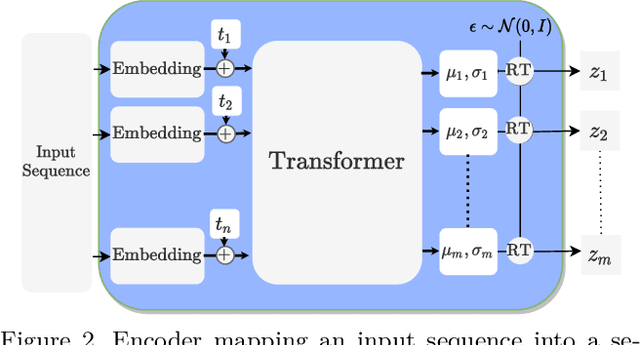
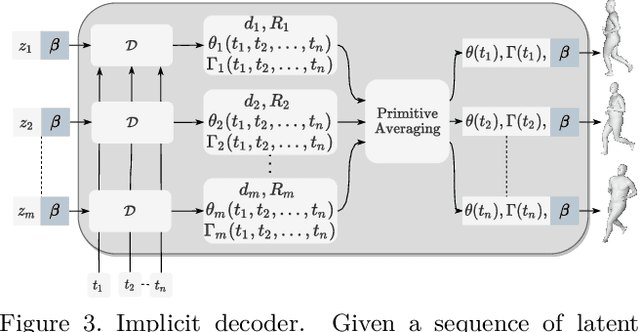
We propose a markerless performance capture method that computes a temporally coherent 4D representation of an actor deforming over time from a sparsely sampled sequence of untracked 3D point clouds. Our method proceeds by latent optimization with a spatio-temporal motion prior. Recently, task generic motion priors have been introduced and propose a coherent representation of human motion based on a single latent code, with encouraging results with short sequences and given temporal correspondences. Extending these methods to longer sequences without correspondences is all but straightforward. One latent code proves inefficient to encode longer term variability, and latent space optimization will be very susceptible to erroneous local minima due to possible inverted pose fittings. We address both problems by learning a motion prior that encodes a 4D human motion sequence into a sequence of latent primitives instead of one latent code. We also propose an additional mapping encoder which directly projects a sequence of point clouds into the learned latent space to provide a good initialization of the latent representation at inference time. Our temporal decoding from latent space is implicit and continuous in time, providing flexibility with temporal resolution. We show experimentally that our method outperforms state-of-the-art motion priors.
Moulding Humans: Non-parametric 3D Human Shape Estimation from Single Images
Aug 01, 2019

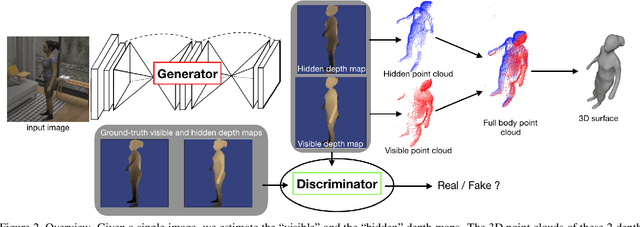
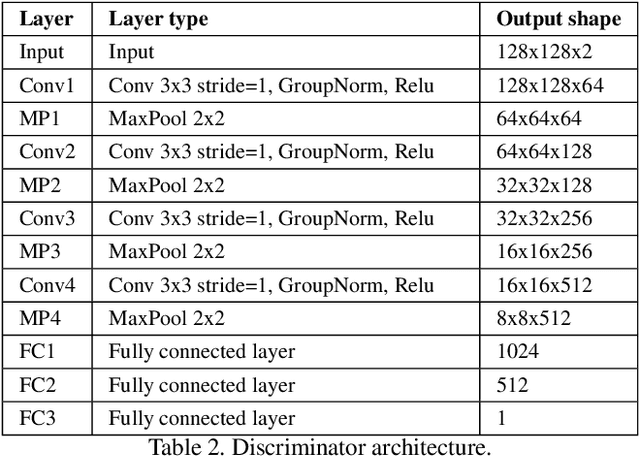
In this paper, we tackle the problem of 3D human shape estimation from single RGB images. While the recent progress in convolutional neural networks has allowed impressive results for 3D human pose estimation, estimating the full 3D shape of a person is still an open issue. Model-based approaches can output precise meshes of naked under-cloth human bodies but fail to estimate details and un-modelled elements such as hair or clothing. On the other hand, non-parametric volumetric approaches can potentially estimate complete shapes but, in practice, they are limited by the resolution of the output grid and cannot produce detailed estimates. In this work, we propose a non-parametric approach that employs a double depth map to represent the 3D shape of a person: a visible depth map and a "hidden" depth map are estimated and combined, to reconstruct the human 3D shape as done with a "mould". This representation through 2D depth maps allows a higher resolution output with a much lower dimension than voxel-based volumetric representations. Additionally, our fully derivable depth-based model allows us to efficiently incorporate a discriminator in an adversarial fashion to improve the accuracy and "humanness" of the 3D output. We train and quantitatively validate our approach on SURREAL and on 3D-HUMANS, a new photorealistic dataset made of semi-synthetic in-house videos annotated with 3D ground truth surfaces.
Shape Animation with Combined Captured and Simulated Dynamics
Jan 06, 2016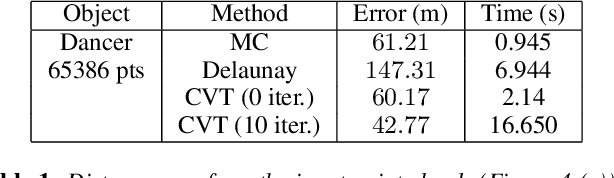



We present a novel volumetric animation generation framework to create new types of animations from raw 3D surface or point cloud sequence of captured real performances. The framework considers as input time incoherent 3D observations of a moving shape, and is thus particularly suitable for the output of performance capture platforms. In our system, a suitable virtual representation of the actor is built from real captures that allows seamless combination and simulation with virtual external forces and objects, in which the original captured actor can be reshaped, disassembled or reassembled from user-specified virtual physics. Instead of using the dominant surface-based geometric representation of the capture, which is less suitable for volumetric effects, our pipeline exploits Centroidal Voronoi tessellation decompositions as unified volumetric representation of the real captured actor, which we show can be used seamlessly as a building block for all processing stages, from capture and tracking to virtual physic simulation. The representation makes no human specific assumption and can be used to capture and re-simulate the actor with props or other moving scenery elements. We demonstrate the potential of this pipeline for virtual reanimation of a real captured event with various unprecedented volumetric visual effects, such as volumetric distortion, erosion, morphing, gravity pull, or collisions.