 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DHumanOutfit: a multi-subject 4D dataset of human motion sequences in varying outfits exhibiting large displacements
Jun 12, 2023
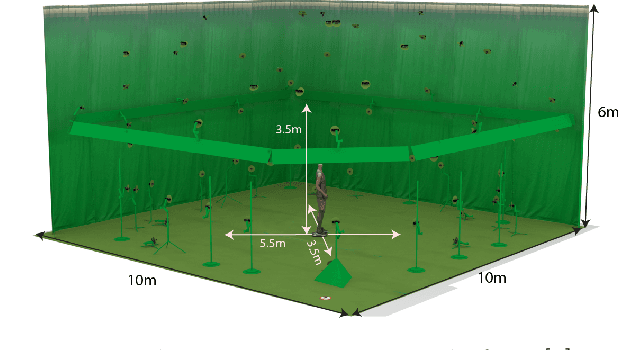

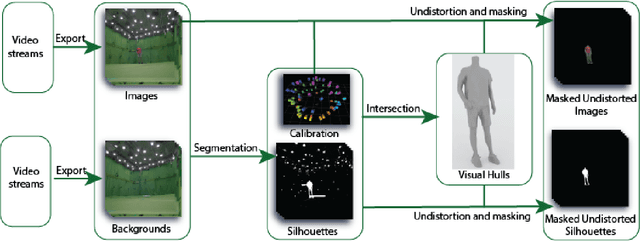
This work presents 4DHumanOutfit, a new dataset of densely sampled spatio-temporal 4D human motion data of different actors, outfits and motions. The dataset is designed to contain different actors wearing different outfits while performing different motions in each outfit. In this way, the dataset can be seen as a cube of data containing 4D motion sequences along 3 axes with identity, outfit and motion. This rich dataset has numerous potential applications for the processing and creation of digital humans, e.g. augmented reality, avatar creation and virtual try on. 4DHumanOutfit is released for research purposes at https://kinovis.inria.fr/4dhumanoutfit/. In addition to image data and 4D reconstructions, the dataset includes reference solutions for each axis. We present independent baselines along each axis that demonstrate the value of these reference solutions for evaluation tasks.
Correspondence-free online human motion retargeting
Feb 01, 2023



We present a novel data-driven framework for unsupervised human motion retargeting which animates a target body shape with a source motion. This allows to retarget motions between different characters by animating a target subject with a motion of a source subject. Our method is correspondence-free,~\ie neither spatial correspondences between the source and target shapes nor temporal correspondences between different frames of the source motion are required. Our proposed method directly animates a target shape with arbitrary sequences of humans in motion, possibly captured using 4D acquisition platforms or consumer devices. Our framework takes into account long-term temporal context of $1$ second during retargeting while accounting for surface details. To achieve this, we take inspiration from two lines of existing work: skeletal motion retargeting, which leverages long-term temporal context at the cost of surface detail, and surface-based retargeting, which preserves surface details without considering long-term temporal context. We unify the advantages of these works by combining a learnt skinning field with a skeletal retargeting approach. During inference, our method runs online,~\ie the input can be processed in a serial way, and retargeting is performed in a single forward pass per frame. Experiments show that including long-term temporal context during training improves the method's accuracy both in terms of the retargeted skeletal motion and the detail preservation. Furthermore, our method generalizes well on unobserved motions and body shapes. We demonstrate that the proposed framework achieves state-of-the-art results on two test datasets.
Spatio-temporal motion completion using a sequence of latent primitives
Jun 27, 2022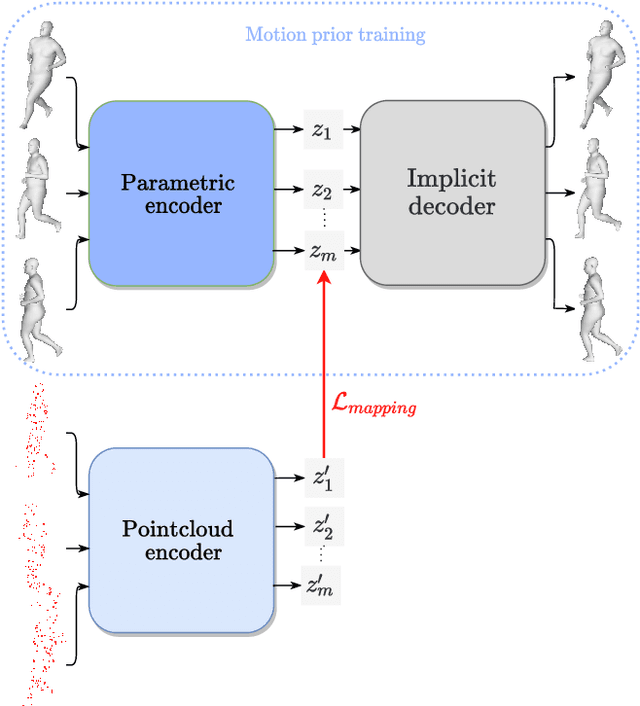
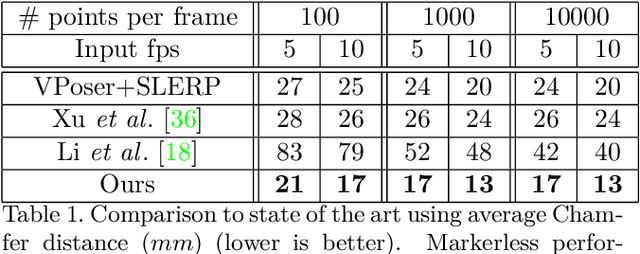
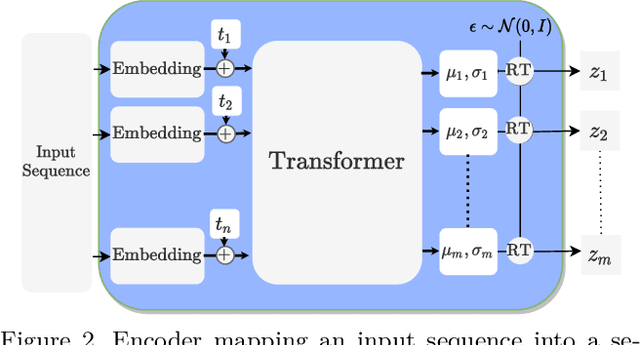
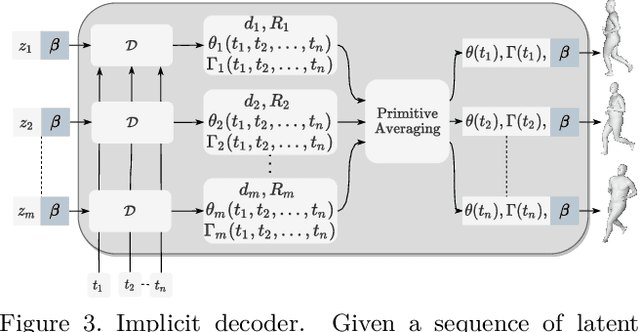
We propose a markerless performance capture method that computes a temporally coherent 4D representation of an actor deforming over time from a sparsely sampled sequence of untracked 3D point clouds. Our method proceeds by latent optimization with a spatio-temporal motion prior. Recently, task generic motion priors have been introduced and propose a coherent representation of human motion based on a single latent code, with encouraging results with short sequences and given temporal correspondences. Extending these methods to longer sequences without correspondences is all but straightforward. One latent code proves inefficient to encode longer term variability, and latent space optimization will be very susceptible to erroneous local minima due to possible inverted pose fittings. We address both problems by learning a motion prior that encodes a 4D human motion sequence into a sequence of latent primitives instead of one latent code. We also propose an additional mapping encoder which directly projects a sequence of point clouds into the learned latent space to provide a good initialization of the latent representation at inference time. Our temporal decoding from latent space is implicit and continuous in time, providing flexibility with temporal resolution. We show experimentally that our method outperforms state-of-the-art motion priors.