 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoulding Humans: Non-parametric 3D Human Shape Estimation from Single Images
Aug 01, 2019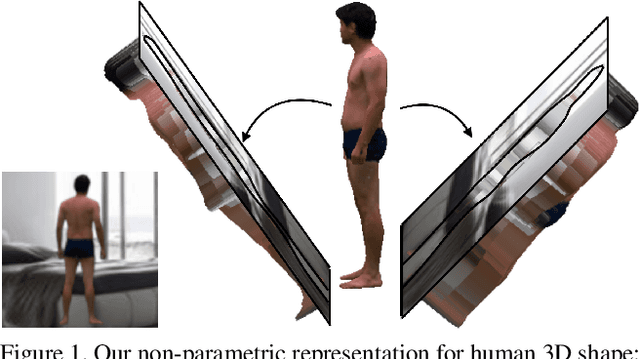

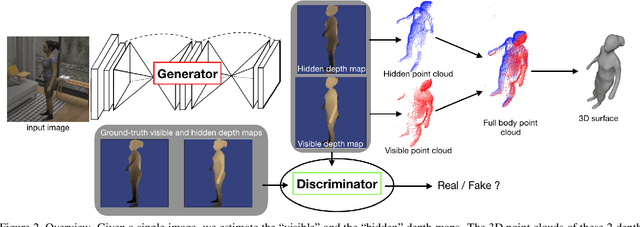
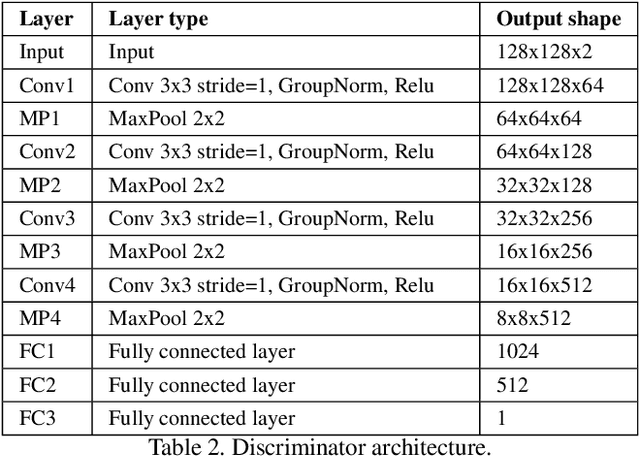
In this paper, we tackle the problem of 3D human shape estimation from single RGB images. While the recent progress in convolutional neural networks has allowed impressive results for 3D human pose estimation, estimating the full 3D shape of a person is still an open issue. Model-based approaches can output precise meshes of naked under-cloth human bodies but fail to estimate details and un-modelled elements such as hair or clothing. On the other hand, non-parametric volumetric approaches can potentially estimate complete shapes but, in practice, they are limited by the resolution of the output grid and cannot produce detailed estimates. In this work, we propose a non-parametric approach that employs a double depth map to represent the 3D shape of a person: a visible depth map and a "hidden" depth map are estimated and combined, to reconstruct the human 3D shape as done with a "mould". This representation through 2D depth maps allows a higher resolution output with a much lower dimension than voxel-based volumetric representations. Additionally, our fully derivable depth-based model allows us to efficiently incorporate a discriminator in an adversarial fashion to improve the accuracy and "humanness" of the 3D output. We train and quantitatively validate our approach on SURREAL and on 3D-HUMANS, a new photorealistic dataset made of semi-synthetic in-house videos annotated with 3D ground truth surfaces.
Learning from Synthetic Humans
Jan 19, 2018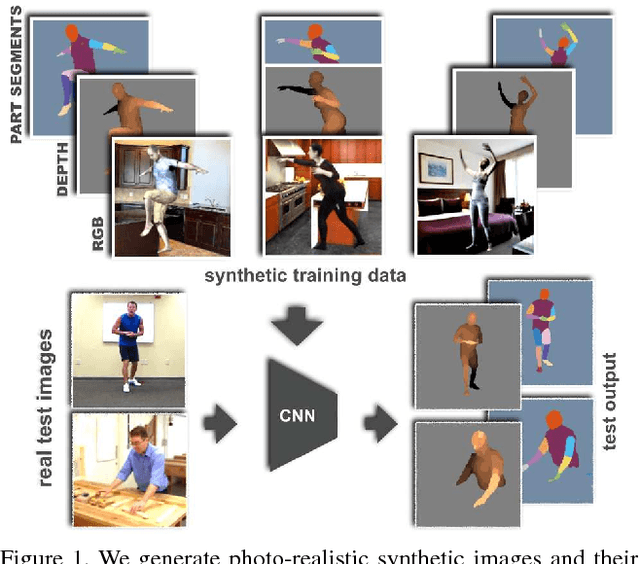
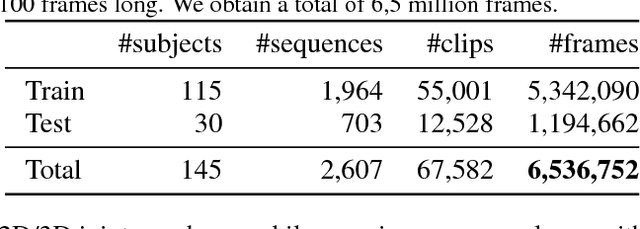
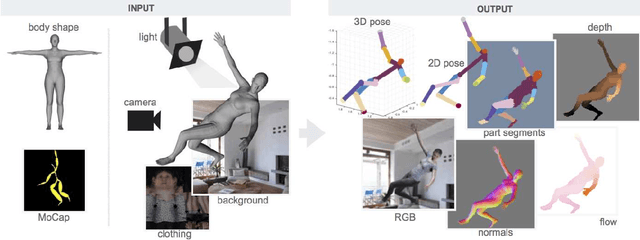
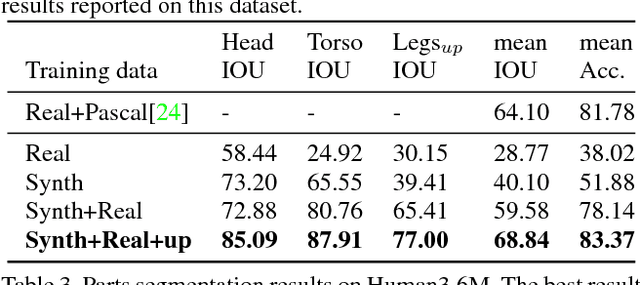
Estimating human pose, shape, and motion from images and videos are fundamental challenges with many applications. Recent advances in 2D human pose estimation use large amounts of manually-labeled training data for learning convolutional neural networks (CNNs). Such data is time consuming to acquire and difficult to extend. Moreover, manual labeling of 3D pose, depth and motion is impractical. In this work we present SURREAL (Synthetic hUmans foR REAL tasks): a new large-scale dataset with synthetically-generated but realistic images of people rendered from 3D sequences of human motion capture data. We generate more than 6 million frames together with ground truth pose, depth maps, and segmentation masks. We show that CNNs trained on our synthetic dataset allow for accurate human depth estimation and human part segmentation in real RGB images. Our results and the new dataset open up new possibilities for advancing person analysis using cheap and large-scale synthetic data.
Human Action Localization with Sparse Spatial Supervision
May 23, 2017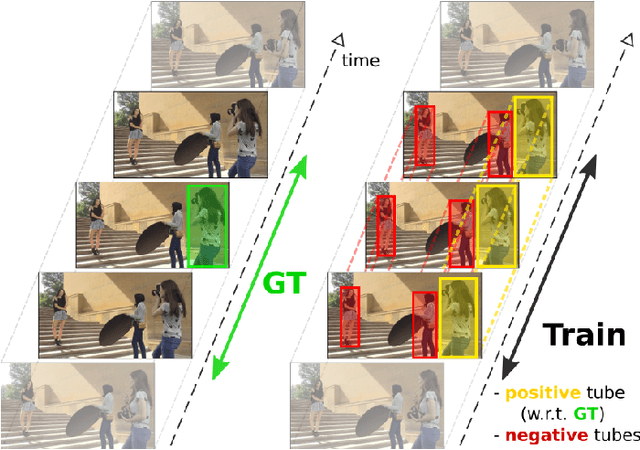
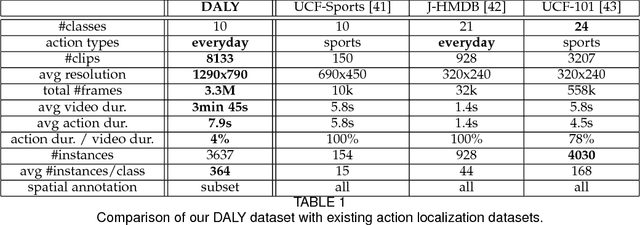
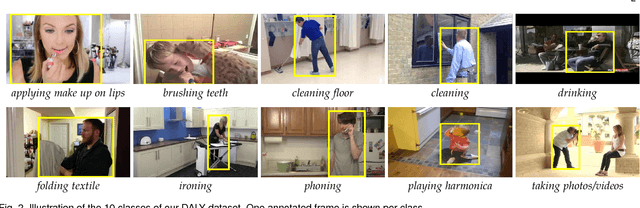
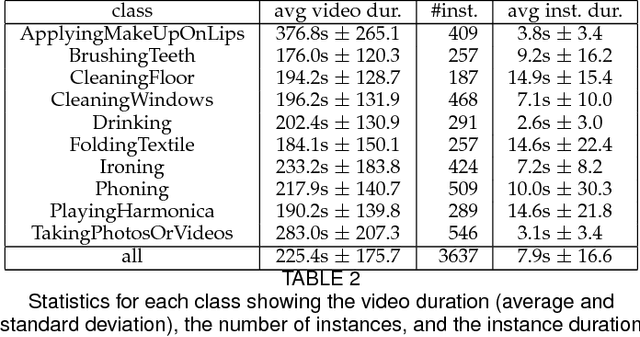
We introduce an approach for spatio-temporal human action localization using sparse spatial supervision. Our method leverages the large amount of annotated humans available today and extracts human tubes by combining a state-of-the-art human detector with a tracking-by-detection approach. Given these high-quality human tubes and temporal supervision, we select positive and negative tubes with very sparse spatial supervision, i.e., only one spatially annotated frame per instance. The selected tubes allow us to effectively learn a spatio-temporal action detector based on dense trajectories or CNNs. We conduct experiments on existing action localization benchmarks: UCF-Sports, J-HMDB and UCF-101. Our results show that our approach, despite using sparse spatial supervision, performs on par with methods using full supervision, i.e., one bounding box annotation per frame. To further validate our method, we introduce DALY (Daily Action Localization in YouTube), a dataset for realistic action localization in space and time. It contains high quality temporal and spatial annotations for 3.6k instances of 10 actions in 31 hours of videos (3.3M frames). It is an order of magnitude larger than existing datasets, with more diversity in appearance and long untrimmed videos.