 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action Localization with Sparse Spatial Supervision
Paper and Code
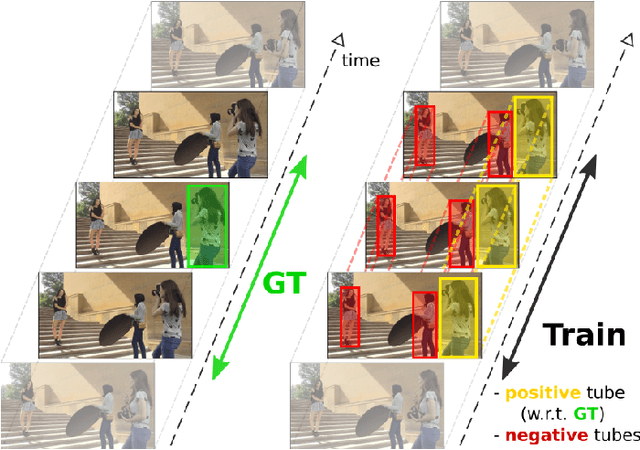
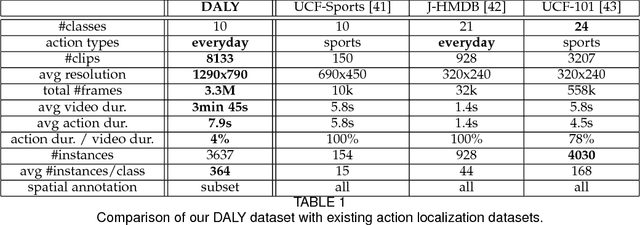
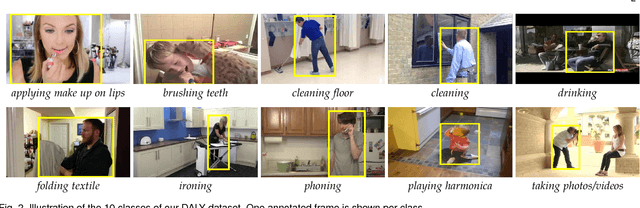
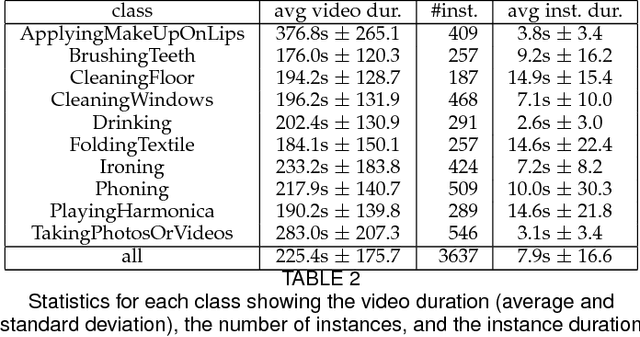
We introduce an approach for spatio-temporal human action localization using sparse spatial supervision. Our method leverages the large amount of annotated humans available today and extracts human tubes by combining a state-of-the-art human detector with a tracking-by-detection approach. Given these high-quality human tubes and temporal supervision, we select positive and negative tubes with very sparse spatial supervision, i.e., only one spatially annotated frame per instance. The selected tubes allow us to effectively learn a spatio-temporal action detector based on dense trajectories or CNNs. We conduct experiments on existing action localization benchmarks: UCF-Sports, J-HMDB and UCF-101. Our results show that our approach, despite using sparse spatial supervision, performs on par with methods using full supervision, i.e., one bounding box annotation per frame. To further validate our method, we introduce DALY (Daily Action Localization in YouTube), a dataset for realistic action localization in space and time. It contains high quality temporal and spatial annotations for 3.6k instances of 10 actions in 31 hours of videos (3.3M frames). It is an order of magnitude larger than existing datasets, with more diversity in appearance and long untrimmed videos.