 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPLy Benchmarking 3D Human Pose Estimation in the Wild
Dec 04, 2020
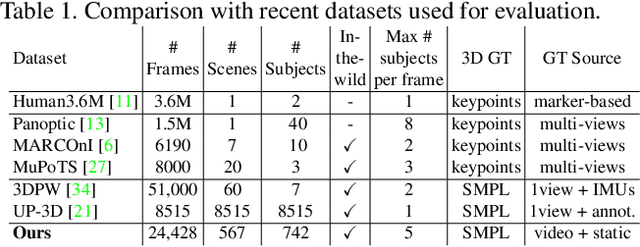

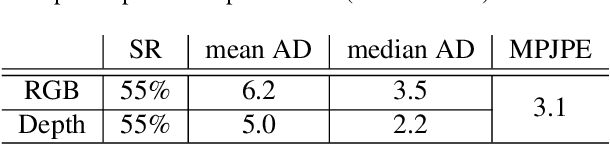
Predicting 3D human pose from images has seen great recent improvements. Novel approaches that can even predict both pose and shape from a single input image have been introduced, often relying on a parametric model of the human body such as SMPL. While qualitative results for such methods are often shown for images captured in-the-wild, a proper benchmark in such conditions is still missing, as it is cumbersome to obtain ground-truth 3D poses elsewhere than in a motion capture room. This paper presents a pipeline to easily produce and validate such a dataset with accurate ground-truth, with which we benchmark recent 3D human pose estimation methods in-the-wild. We make use of the recently introduced Mannequin Challenge dataset which contains in-the-wild videos of people frozen in action like statues and leverage the fact that people are static and the camera moving to accurately fit the SMPL model on the sequences. A total of 24,428 frames with registered body models are then selected from 567 scenes at almost no cost, using only online RGB videos. We benchmark state-of-the-art SMPL-based human pose estimation methods on this dataset. Our results highlight that challenges remain, in particular for difficult poses or for scenes where the persons are partially truncated or occluded.
DOPE: Distillation Of Part Experts for whole-body 3D pose estimation in the wild
Aug 21, 2020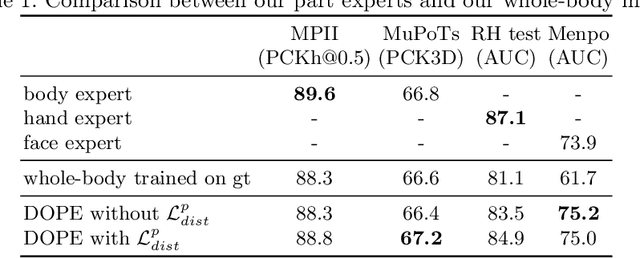

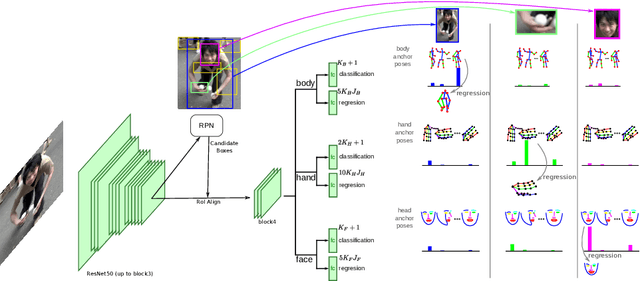

We introduce DOPE, the first method to detect and estimate whole-body 3D human poses, including bodies, hands and faces, in the wild. Achieving this level of details is key for a number of applications that require understanding the interactions of the people with each other or with the environment. The main challenge is the lack of in-the-wild data with labeled whole-body 3D poses. In previous work, training data has been annotated or generated for simpler tasks focusing on bodies, hands or faces separately. In this work, we propose to take advantage of these datasets to train independent experts for each part, namely a body, a hand and a face expert, and distill their knowledge into a single deep network designed for whole-body 2D-3D pose detection. In practice, given a training image with partial or no annotation, each part expert detects its subset of keypoints in 2D and 3D and the resulting estimations are combined to obtain whole-body pseudo ground-truth poses. A distillation loss encourages the whole-body predictions to mimic the experts' outputs. Our results show that this approach significantly outperforms the same whole-body model trained without distillation while staying close to the performance of the experts. Importantly, DOPE is computationally less demanding than the ensemble of experts and can achieve real-time performance. Test code and models are available at https://europe.naverlabs.com/research/computer-vision/dope.