 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Apr 10, 2026Recovering camera parameters from images and rendering scenes from novel viewpoints have long been treated as separate tasks in computer vision and graphics. This separation breaks down when image coverage is sparse or poses are ambiguous, since each task needs what the other produces. We propose Rays as Pixels, a Video Diffusion Model (VDM) that learns a joint distribution over videos and camera trajectories. We represent each camera as dense ray pixels (raxels) and denoise them jointly with video frames through Decoupled Self-Cross Attention mechanism. A single trained model handles three tasks: predicting camera trajectories from video, jointly generating video and camera trajectory from input images, and generating video from input images along a target camera trajectory. Because the model can both predict trajectories from a video and generate views conditioned on its own predictions, we evaluate it through a closed-loop self-consistency test, demonstrating that its forward and inverse predictions agree. Notably, trajectory prediction requires far fewer denoising steps than video generation, even a few denoising steps suffice for self-consistency. We report results on pose estimation and camera-controlled video generation.
DT-NVS: Diffusion Transformers for Novel View Synthesis
Nov 11, 2025Generating novel views of a natural scene, e.g., every-day scenes both indoors and outdoors, from a single view is an under-explored problem, even though it is an organic extension to the object-centric novel view synthesis. Existing diffusion-based approaches focus rather on small camera movements in real scenes or only consider unnatural object-centric scenes, limiting their potential applications in real-world settings. In this paper we move away from these constrained regimes and propose a 3D diffusion model trained with image-only losses on a large-scale dataset of real-world, multi-category, unaligned, and casually acquired videos of everyday scenes. We propose DT-NVS, a 3D-aware diffusion model for generalized novel view synthesis that exploits a transformer-based architecture backbone. We make significant contributions to transformer and self-attention architectures to translate images to 3d representations, and novel camera conditioning strategies to allow training on real-world unaligned datasets. In addition, we introduce a novel training paradigm swapping the role of reference frame between the conditioning image and the sampled noisy input. We evaluate our approach on the 3D task of generalized novel view synthesis from a single input image and show improvements over state-of-the-art 3D aware diffusion models and deterministic approaches, while generating diverse outputs.
Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
Mar 21, 2025


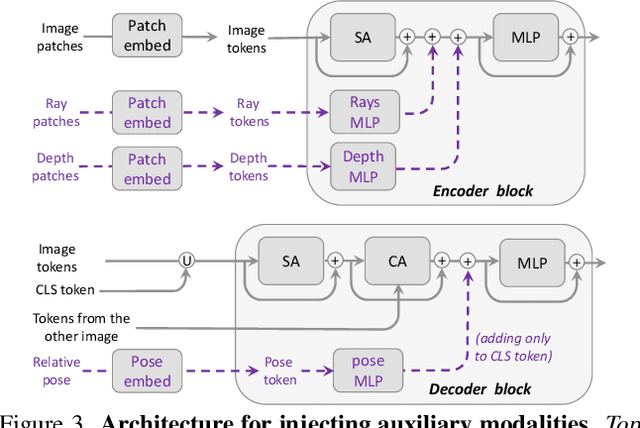
We present Pow3r, a novel large 3D vision regression model that is highly versatile in the input modalities it accepts. Unlike previous feed-forward models that lack any mechanism to exploit known camera or scene priors at test time, Pow3r incorporates any combination of auxiliary information such as intrinsics, relative pose, dense or sparse depth, alongside input images, within a single network. Building upon the recent DUSt3R paradigm, a transformer-based architecture that leverages powerful pre-training, our lightweight and versatile conditioning acts as additional guidance for the network to predict more accurate estimates when auxiliary information is available. During training we feed the model with random subsets of modalities at each iteration, which enables the model to operate under different levels of known priors at test time. This in turn opens up new capabilities, such as performing inference in native image resolution, or point-cloud completion. Our experiments on 3D reconstruction, depth completion, multi-view depth prediction, multi-view stereo, and multi-view pose estimation tasks yield state-of-the-art results and confirm the effectiveness of Pow3r at exploiting all available information. The project webpage is https://europe.naverlabs.com/pow3r.
NViST: In the Wild New View Synthesis from a Single Image with Transformers
Dec 13, 2023We propose NViST, a transformer-based model for novel-view synthesis from a single image, trained on a large-scale dataset of in-the-wild images with complex backgrounds. NViST transforms image inputs directly into a radiance field, adopting a scalable transformer-based architecture. In practice, NViST exploits the self-supervised features learnt by a masked autoencoder (MAE), and learns a novel decoder that translates features to 3D tokens via cross-attention and adaptive layer normalization. Our model is efficient at inference since only a single forward-pass is needed to predict a 3D representation, unlike methods that require test-time optimization or sampling such as 3D-aware diffusion models. We tackle further limitations of current new-view synthesis models. First, unlike most generative models that are trained in a category-specific manner, often on synthetic datasets or on masked inputs, our model is trained on MVImgNet, a large-scale dataset of real-world, casually-captured videos containing hundreds of object categories with diverse backgrounds. Secondly, our model does not require canonicalization of the training data - i.e. aligning all objects with a frontal view - only needing relative pose at training time which removes a substantial barrier to it being used on casually captured datasets. We show results on unseen objects and categories on MVImgNet and even casual phone captures. We conduct qualitative and quantitative evaluations on MVImgNet and ShapeNet to show that our model represents a step forward towards enabling true in-the-wild novel-view synthesis from a single image.
CodeNeRF: Disentangled Neural Radiance Fields for Object Categories
Sep 03, 2021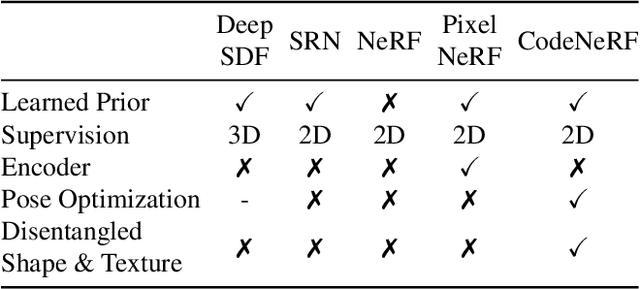
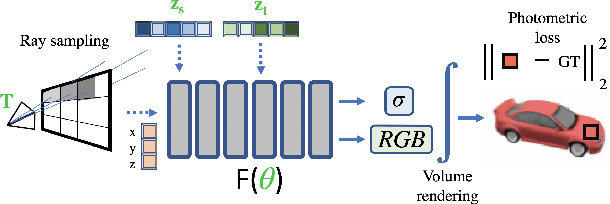
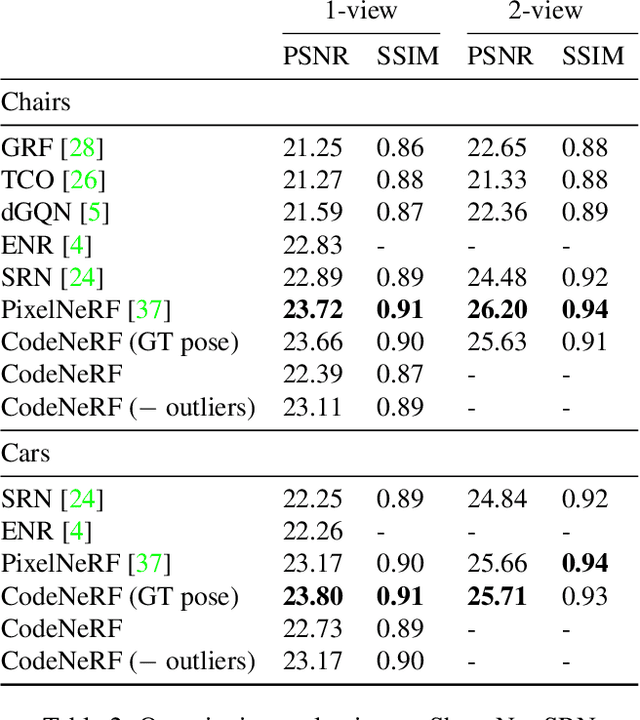
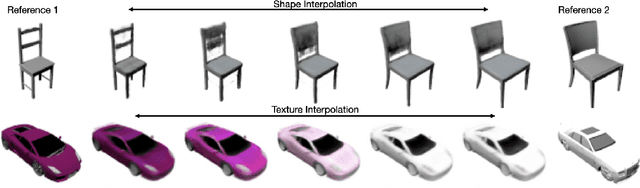
CodeNeRF is an implicit 3D neural representation that learns the variation of object shapes and textures across a category and can be trained, from a set of posed images, to synthesize novel views of unseen objects. Unlike the original NeRF, which is scene specific, CodeNeRF learns to disentangle shape and texture by learning separate embeddings. At test time, given a single unposed image of an unseen object, CodeNeRF jointly estimates camera viewpoint, and shape and appearance codes via optimization. Unseen objects can be reconstructed from a single image, and then rendered from new viewpoints or their shape and texture edited by varying the latent codes. We conduct experiments on the SRN benchmark, which show that CodeNeRF generalises well to unseen objects and achieves on-par performance with methods that require known camera pose at test time. Our results on real-world images demonstrate that CodeNeRF can bridge the sim-to-real gap. Project page: \url{https://github.com/wayne1123/code-nerf}
Sampling Using Neural Networks for colorizing the grayscale images
Dec 27, 2018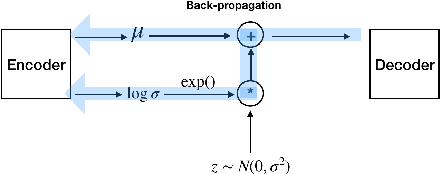
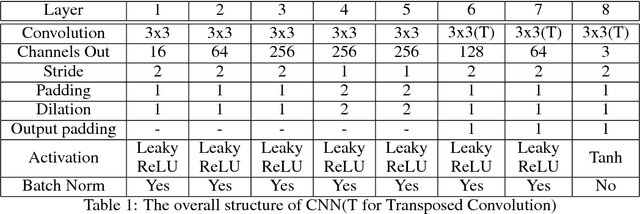
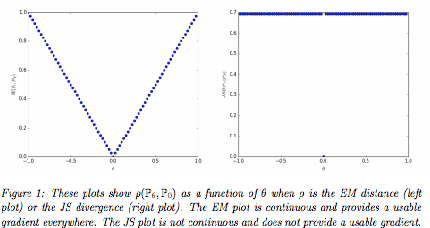
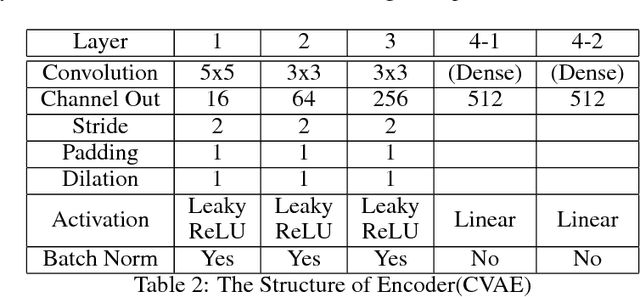
The main idea of this paper is to explore the possibilities of generating samples from the neural networks, mostly focusing on the colorization of the grey-scale images. I will compare the existing methods for colorization and explore the possibilities of using new generative modeling to the task of colorization. The contributions of this paper are to compare the existing structures with similar generating structures(Decoders) and to apply the novel structures including Conditional VAE(CVAE), Conditional Wasserstein GAN with Gradient Penalty(CWGAN-GP), CWGAN-GP with L1 reconstruction loss, Adversarial Generative Encoders(AGE) and Introspective VAE(IVAE). I trained these models using CIFAR-10 images. To measure the performance, I use Inception Score(IS) which measures how distinctive each image is and how diverse overall samples are as well as human eyes for CIFAR-10 images. It turns out that CVAE with L1 reconstruction loss and IVAE achieve the highest score in IS. CWGAN-GP with L1 tends to learn faster than CWGAN-GP, but IS does not increase from CWGAN-GP. CWGAN-GP tends to generate more diverse images than other models using reconstruction loss. Also, I figured out that the proper regularization plays a vital role in generative modeling.