 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-MUSt3R: Sliding Multi-view 3D Reconstruction
Feb 04, 2026The recent paradigm shift in 3D vision led to the rise of foundation models with remarkable capabilities in 3D perception from uncalibrated images. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. This work proposes S-MUSt3R, a simple and efficient pipeline that extends the limits of foundation models for monocular 3D reconstruction. Our approach addresses the scalability bottleneck of foundation models through a simple strategy of sequence segmentation followed by segment alignment and lightweight loop closure optimization. Without model retraining, we benefit from remarkable 3D reconstruction capacities of MUSt3R model and achieve trajectory and reconstruction performance comparable to traditional methods with more complex architecture. We evaluate S-MUSt3R on TUM, 7-Scenes and proprietary robot navigation datasets and show that S-MUSt3R runs successfully on long RGB sequences and produces accurate and consistent 3D reconstruction. Our results highlight the potential of leveraging the MUSt3R model for scalable monocular 3D scene in real-world settings, with an important advantage of making predictions directly in the metric space.
PanSt3R: Multi-view Consistent Panoptic Segmentation
Jun 26, 2025Panoptic segmentation of 3D scenes, involving the segmentation and classification of object instances in a dense 3D reconstruction of a scene, is a challenging problem, especially when relying solely on unposed 2D images. Existing approaches typically leverage off-the-shelf models to extract per-frame 2D panoptic segmentations, before optimizing an implicit geometric representation (often based on NeRF) to integrate and fuse the 2D predictions. We argue that relying on 2D panoptic segmentation for a problem inherently 3D and multi-view is likely suboptimal as it fails to leverage the full potential of spatial relationships across views. In addition to requiring camera parameters, these approaches also necessitate computationally expensive test-time optimization for each scene. Instead, in this work, we propose a unified and integrated approach PanSt3R, which eliminates the need for test-time optimization by jointly predicting 3D geometry and multi-view panoptic segmentation in a single forward pass. Our approach builds upon recent advances in 3D reconstruction, specifically upon MUSt3R, a scalable multi-view version of DUSt3R, and enhances it with semantic awareness and multi-view panoptic segmentation capabilities. We additionally revisit the standard post-processing mask merging procedure and introduce a more principled approach for multi-view segmentation. We also introduce a simple method for generating novel-view predictions based on the predictions of PanSt3R and vanilla 3DGS. Overall, the proposed PanSt3R is conceptually simple, yet fast and scalable, and achieves state-of-the-art performance on several benchmarks, while being orders of magnitude faster than existing methods.
Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
Mar 21, 2025


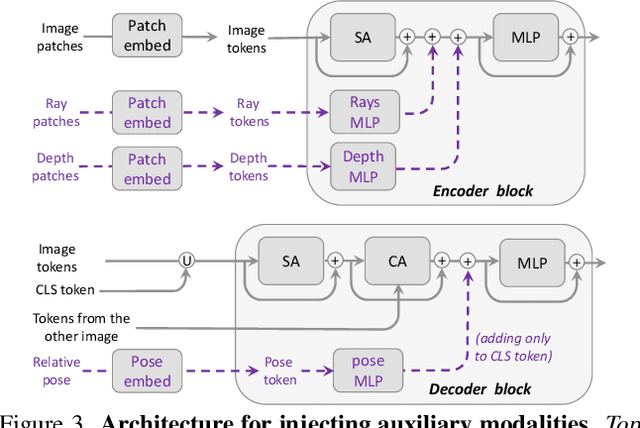
We present Pow3r, a novel large 3D vision regression model that is highly versatile in the input modalities it accepts. Unlike previous feed-forward models that lack any mechanism to exploit known camera or scene priors at test time, Pow3r incorporates any combination of auxiliary information such as intrinsics, relative pose, dense or sparse depth, alongside input images, within a single network. Building upon the recent DUSt3R paradigm, a transformer-based architecture that leverages powerful pre-training, our lightweight and versatile conditioning acts as additional guidance for the network to predict more accurate estimates when auxiliary information is available. During training we feed the model with random subsets of modalities at each iteration, which enables the model to operate under different levels of known priors at test time. This in turn opens up new capabilities, such as performing inference in native image resolution, or point-cloud completion. Our experiments on 3D reconstruction, depth completion, multi-view depth prediction, multi-view stereo, and multi-view pose estimation tasks yield state-of-the-art results and confirm the effectiveness of Pow3r at exploiting all available information. The project webpage is https://europe.naverlabs.com/pow3r.
MUSt3R: Multi-view Network for Stereo 3D Reconstruction
Mar 03, 2025DUSt3R introduced a novel paradigm in geometric computer vision by proposing a model that can provide dense and unconstrained Stereo 3D Reconstruction of arbitrary image collections with no prior information about camera calibration nor viewpoint poses. Under the hood, however, DUSt3R processes image pairs, regressing local 3D reconstructions that need to be aligned in a global coordinate system. The number of pairs, growing quadratically, is an inherent limitation that becomes especially concerning for robust and fast optimization in the case of large image collections. In this paper, we propose an extension of DUSt3R from pairs to multiple views, that addresses all aforementioned concerns. Indeed, we propose a Multi-view Network for Stereo 3D Reconstruction, or MUSt3R, that modifies the DUSt3R architecture by making it symmetric and extending it to directly predict 3D structure for all views in a common coordinate frame. Second, we entail the model with a multi-layer memory mechanism which allows to reduce the computational complexity and to scale the reconstruction to large collections, inferring thousands of 3D pointmaps at high frame-rates with limited added complexity. The framework is designed to perform 3D reconstruction both offline and online, and hence can be seamlessly applied to SfM and visual SLAM scenarios showing state-of-the-art performance on various 3D downstream tasks, including uncalibrated Visual Odometry, relative camera pose, scale and focal estimation, 3D reconstruction and multi-view depth estimation.
MASt3R-SfM: a Fully-Integrated Solution for Unconstrained Structure-from-Motion
Sep 27, 2024



Structure-from-Motion (SfM), a task aiming at jointly recovering camera poses and 3D geometry of a scene given a set of images, remains a hard problem with still many open challenges despite decades of significant progress. The traditional solution for SfM consists of a complex pipeline of minimal solvers which tends to propagate errors and fails when images do not sufficiently overlap, have too little motion, etc. Recent methods have attempted to revisit this paradigm, but we empirically show that they fall short of fixing these core issues. In this paper, we propose instead to build upon a recently released foundation model for 3D vision that can robustly produce local 3D reconstructions and accurate matches. We introduce a low-memory approach to accurately align these local reconstructions in a global coordinate system. We further show that such foundation models can serve as efficient image retrievers without any overhead, reducing the overall complexity from quadratic to linear. Overall, our novel SfM pipeline is simple, scalable, fast and truly unconstrained, i.e. it can handle any collection of images, ordered or not. Extensive experiments on multiple benchmarks show that our method provides steady performance across diverse settings, especially outperforming existing methods in small- and medium-scale settings.
DUSt3R: Geometric 3D Vision Made Easy
Dec 21, 2023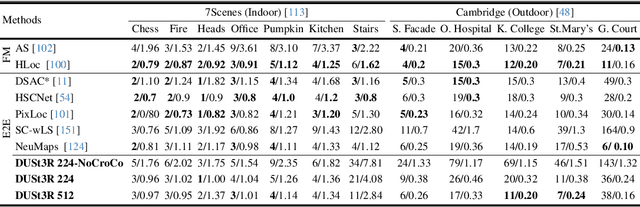
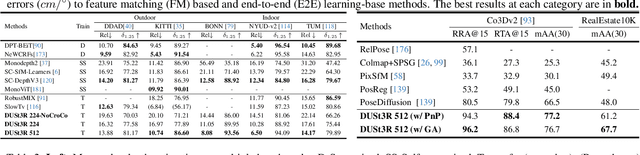

Multi-view stereo reconstruction (MVS) in the wild requires to first estimate the camera parameters e.g. intrinsic and extrinsic parameters. These are usually tedious and cumbersome to obtain, yet they are mandatory to triangulate corresponding pixels in 3D space, which is the core of all best performing MVS algorithms. In this work, we take an opposite stance and introduce DUSt3R, a radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction of arbitrary image collections, i.e. operating without prior information about camera calibration nor viewpoint poses. We cast the pairwise reconstruction problem as a regression of pointmaps, relaxing the hard constraints of usual projective camera models. We show that this formulation smoothly unifies the monocular and binocular reconstruction cases. In the case where more than two images are provided, we further propose a simple yet effective global alignment strategy that expresses all pairwise pointmaps in a common reference frame. We base our network architecture on standard Transformer encoders and decoders, allowing us to leverage powerful pretrained models. Our formulation directly provides a 3D model of the scene as well as depth information, but interestingly, we can seamlessly recover from it, pixel matches, relative and absolute camera. Exhaustive experiments on all these tasks showcase that the proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on monocular/multi-view depth estimation as well as relative pose estimation. In summary, DUSt3R makes many geometric 3D vision tasks easy.
MFOS: Model-Free & One-Shot Object Pose Estimation
Oct 03, 2023



Existing learning-based methods for object pose estimation in RGB images are mostly model-specific or category based. They lack the capability to generalize to new object categories at test time, hence severely hindering their practicability and scalability. Notably, recent attempts have been made to solve this issue, but they still require accurate 3D data of the object surface at both train and test time. In this paper, we introduce a novel approach that can estimate in a single forward pass the pose of objects never seen during training, given minimum input. In contrast to existing state-of-the-art approaches, which rely on task-specific modules, our proposed model is entirely based on a transformer architecture, which can benefit from recently proposed 3D-geometry general pretraining. We conduct extensive experiments and report state-of-the-art one-shot performance on the challenging LINEMOD benchmark. Finally, extensive ablations allow us to determine good practices with this relatively new type of architecture in the field.
Win-Win: Training High-Resolution Vision Transformers from Two Windows
Oct 01, 2023



Transformers have become the standard in state-of-the-art vision architectures, achieving impressive performance on both image-level and dense pixelwise tasks. However, training vision transformers for high-resolution pixelwise tasks has a prohibitive cost. Typical solutions boil down to hierarchical architectures, fast and approximate attention, or training on low-resolution crops. This latter solution does not constrain architectural choices, but it leads to a clear performance drop when testing at resolutions significantly higher than that used for training, thus requiring ad-hoc and slow post-processing schemes. In this paper, we propose a novel strategy for efficient training and inference of high-resolution vision transformers: the key principle is to mask out most of the high-resolution inputs during training, keeping only N random windows. This allows the model to learn local interactions between tokens inside each window, and global interactions between tokens from different windows. As a result, the model can directly process the high-resolution input at test time without any special trick. We show that this strategy is effective when using relative positional embedding such as rotary embeddings. It is 4 times faster to train than a full-resolution network, and it is straightforward to use at test time compared to existing approaches. We apply this strategy to the dense monocular task of semantic segmentation, and find that a simple setting with 2 windows performs best, hence the name of our method: Win-Win. To demonstrate the generality of our contribution, we further extend it to the binocular task of optical flow, reaching state-of-the-art performance on the Spring benchmark that contains Full-HD images with an inference time an order of magnitude faster than the best competitor.
SACReg: Scene-Agnostic Coordinate Regression for Visual Localization
Jul 28, 2023Scene coordinates regression (SCR), i.e., predicting 3D coordinates for every pixel of a given image, has recently shown promising potential. However, existing methods remain mostly scene-specific or limited to small scenes and thus hardly scale to realistic datasets. In this paper, we propose a new paradigm where a single generic SCR model is trained once to be then deployed to new test scenes, regardless of their scale and without further finetuning. For a given query image, it collects inputs from off-the-shelf image retrieval techniques and Structure-from-Motion databases: a list of relevant database images with sparse pointwise 2D-3D annotations. The model is based on the transformer architecture and can take a variable number of images and sparse 2D-3D annotations as input. It is trained on a few diverse datasets and significantly outperforms other scene regression approaches on several benchmarks, including scene-specific models, for visual localization. In particular, we set a new state of the art on the Cambridge localization benchmark, even outperforming feature-matching-based approaches.
Learning with Average Precision: Training Image Retrieval with a Listwise Loss
Jun 18, 2019
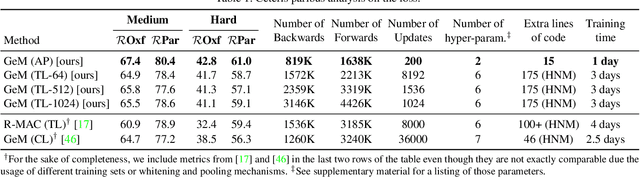
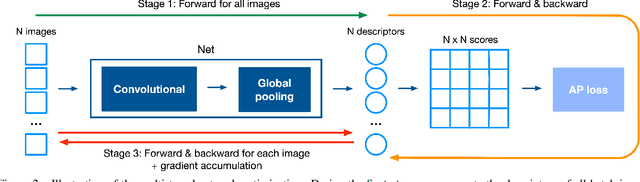
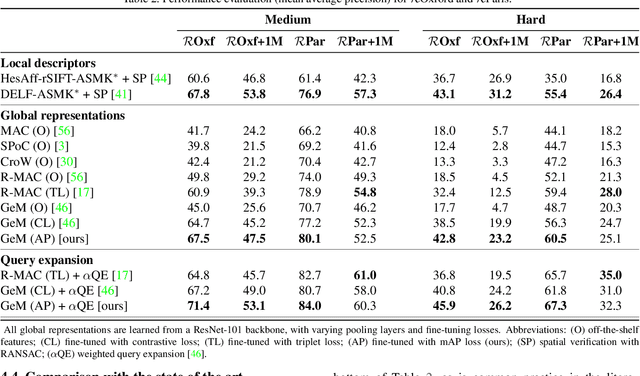
Image retrieval can be formulated as a ranking problem where the goal is to order database images by decreasing similarity to the query. Recent deep models for image retrieval have outperformed traditional methods by leveraging ranking-tailored loss functions, but important theoretical and practical problems remain. First, rather than directly optimizing the global ranking, they minimize an upper-bound on the essential loss, which does not necessarily result in an optimal mean average precision (mAP). Second, these methods require significant engineering efforts to work well, e.g. special pre-training and hard-negative mining. In this paper we propose instead to directly optimize the global mAP by leveraging recent advances in listwise loss formulations. Using a histogram binning approximation, the AP can be differentiated and thus employed to end-to-end learning. Compared to existing losses, the proposed method considers thousands of images simultaneously at each iteration and eliminates the need for ad hoc tricks. It also establishes a new state of the art on many standard retrieval benchmarks. Models and evaluation scripts have been made available at https://europe.naverlabs.com/Deep-Image-Retrieval/