 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR: Twin Learning for Dimensionality Reduction
Oct 18, 2021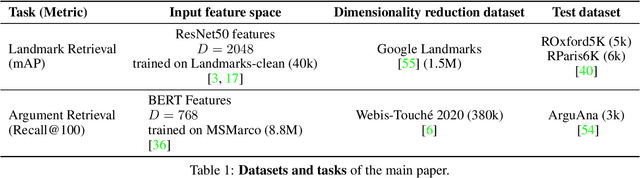
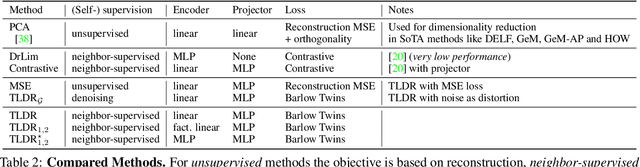
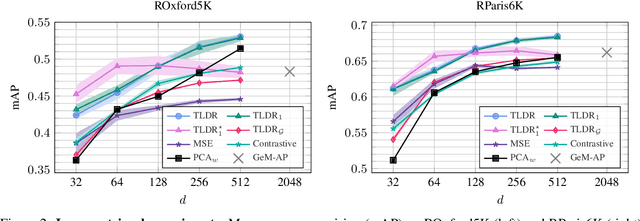

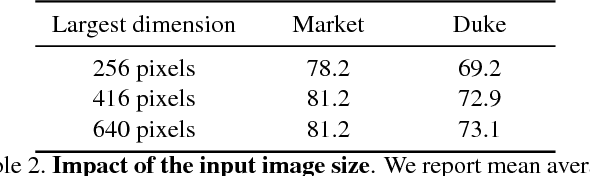
Dimensionality reduction methods are unsupervised approaches which learn low-dimensional spaces where some properties of the initial space, typically the notion of "neighborhood", are preserved. They are a crucial component of diverse tasks like visualization, compression, indexing, and retrieval. Aiming for a totally different goal, self-supervised visual representation learning has been shown to produce transferable representation functions by learning models that encode invariance to artificially created distortions, e.g. a set of hand-crafted image transformations. Unlike manifold learning methods that usually require propagation on large k-NN graphs or complicated optimization solvers, self-supervised learning approaches rely on simpler and more scalable frameworks for learning. In this paper, we unify these two families of approaches from the angle of manifold learning and propose TLDR, a dimensionality reduction method for generic input spaces that is porting the simple self-supervised learning framework of Barlow Twins to a setting where it is hard or impossible to define an appropriate set of distortions by hand. We propose to use nearest neighbors to build pairs from a training set and a redundancy reduction loss borrowed from the self-supervised literature to learn an encoder that produces representations invariant across such pairs. TLDR is a method that is simple, easy to implement and train, and of broad applicability; it consists of an offline nearest neighbor computation step that can be highly approximated, and a straightforward learning process that does not require mining negative samples to contrast, eigendecompositions, or cumbersome optimization solvers. By replacing PCA with TLDR, we are able to increase the performance of GeM-AP by 4% mAP for 128 dimensions, and to retain its performance with 16x fewer dimensions.
Learning with Average Precision: Training Image Retrieval with a Listwise Loss
Jun 18, 2019
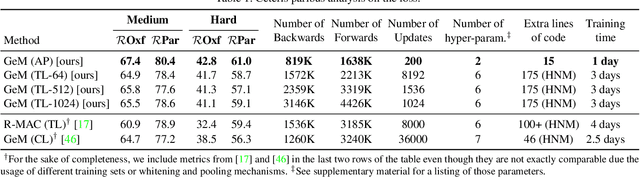
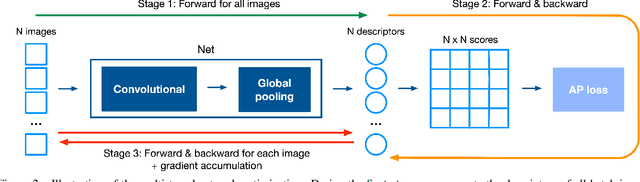
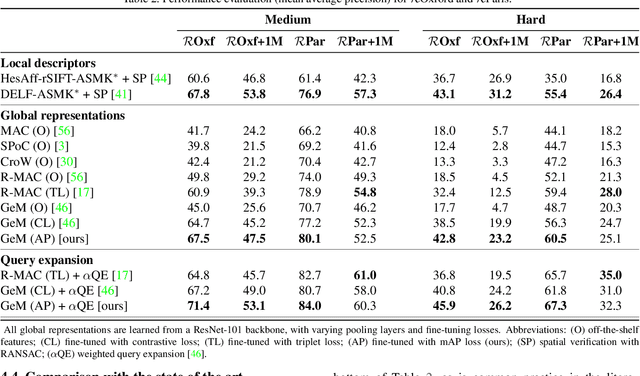
Image retrieval can be formulated as a ranking problem where the goal is to order database images by decreasing similarity to the query. Recent deep models for image retrieval have outperformed traditional methods by leveraging ranking-tailored loss functions, but important theoretical and practical problems remain. First, rather than directly optimizing the global ranking, they minimize an upper-bound on the essential loss, which does not necessarily result in an optimal mean average precision (mAP). Second, these methods require significant engineering efforts to work well, e.g. special pre-training and hard-negative mining. In this paper we propose instead to directly optimize the global mAP by leveraging recent advances in listwise loss formulations. Using a histogram binning approximation, the AP can be differentiated and thus employed to end-to-end learning. Compared to existing losses, the proposed method considers thousands of images simultaneously at each iteration and eliminates the need for ad hoc tricks. It also establishes a new state of the art on many standard retrieval benchmarks. Models and evaluation scripts have been made available at https://europe.naverlabs.com/Deep-Image-Retrieval/
Re-ID done right: towards good practices for person re-identification
Jan 16, 2018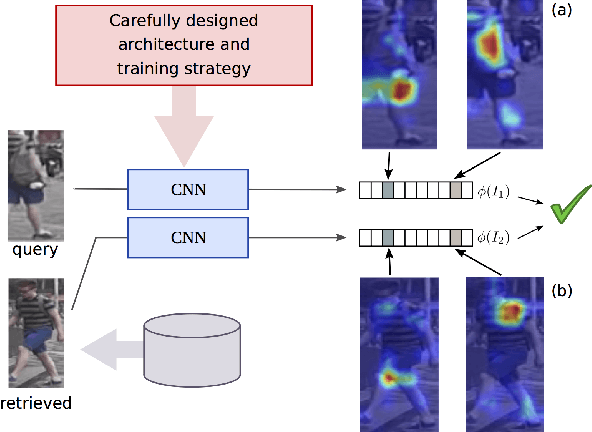

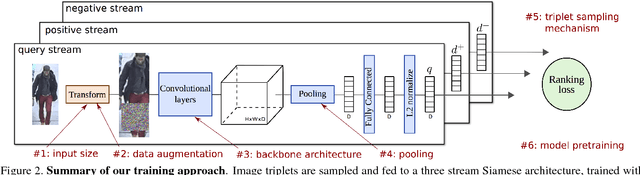
Training a deep architecture using a ranking loss has become standard for the person re-identification task. Increasingly, these deep architectures include additional components that leverage part detections, attribute predictions, pose estimators and other auxiliary information, in order to more effectively localize and align discriminative image regions. In this paper we adopt a different approach and carefully design each component of a simple deep architecture and, critically, the strategy for training it effectively for person re-identification. We extensively evaluate each design choice, leading to a list of good practices for person re-identification. By following these practices, our approach outperforms the state of the art, including more complex methods with auxiliary components, by large margins on four benchmark datasets. We also provide a qualitative analysis of our trained representation which indicates that, while compact, it is able to capture information from localized and discriminative regions, in a manner akin to an implicit attention mechanism.
End-to-end Learning of Deep Visual Representations for Image Retrieval
May 05, 2017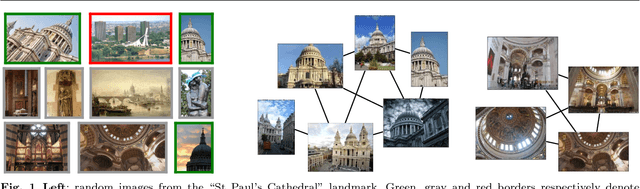
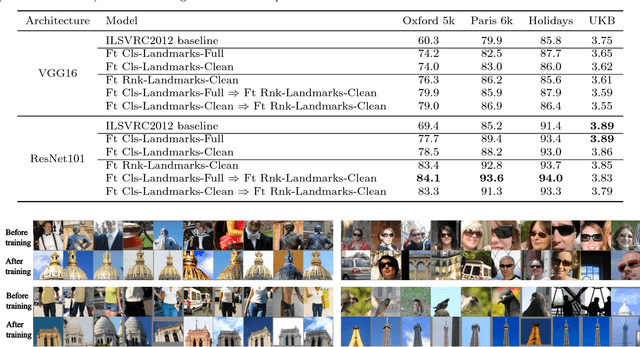

While deep learning has become a key ingredient in the top performing methods for many computer vision tasks, it has failed so far to bring similar improvements to instance-level image retrieval. In this article, we argue that reasons for the underwhelming results of deep methods on image retrieval are threefold: i) noisy training data, ii) inappropriate deep architecture, and iii) suboptimal training procedure. We address all three issues. First, we leverage a large-scale but noisy landmark dataset and develop an automatic cleaning method that produces a suitable training set for deep retrieval. Second, we build on the recent R-MAC descriptor, show that it can be interpreted as a deep and differentiable architecture, and present improvements to enhance it. Last, we train this network with a siamese architecture that combines three streams with a triplet loss. At the end of the training process, the proposed architecture produces a global image representation in a single forward pass that is well suited for image retrieval. Extensive experiments show that our approach significantly outperforms previous retrieval approaches, including state-of-the-art methods based on costly local descriptor indexing and spatial verification. On Oxford 5k, Paris 6k and Holidays, we respectively report 94.7, 96.6, and 94.8 mean average precision. Our representations can also be heavily compressed using product quantization with little loss in accuracy. For additional material, please see www.xrce.xerox.com/Deep-Image-Retrieval.
What is the right way to represent document images?
Dec 02, 2016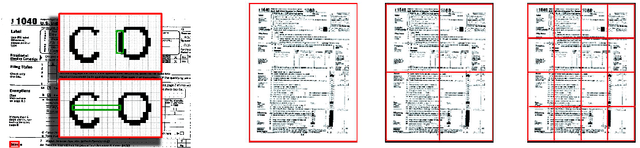
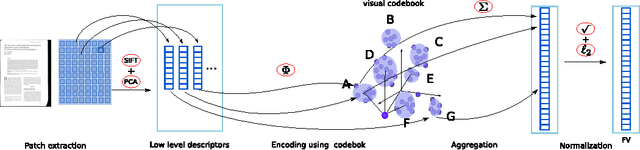

In this article we study the problem of document image representation based on visual features. We propose a comprehensive experimental study that compares three types of visual document image representations: (1) traditional so-called shallow features, such as the RunLength and the Fisher-Vector descriptors, (2) deep features based on Convolutional Neural Networks, and (3) features extracted from hybrid architectures that take inspiration from the two previous ones. We evaluate these features in several tasks (i.e. classification, clustering, and retrieval) and in different setups (e.g. domain transfer) using several public and in-house datasets. Our results show that deep features generally outperform other types of features when there is no domain shift and the new task is closely related to the one used to train the model. However, when a large domain or task shift is present, the Fisher-Vector shallow features generalize better and often obtain the best results.
Deep Image Retrieval: Learning global representations for image search
Jul 28, 2016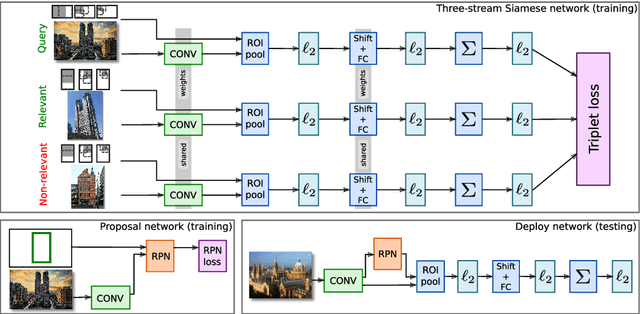
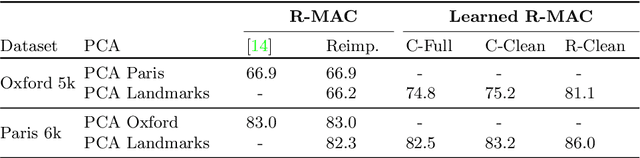
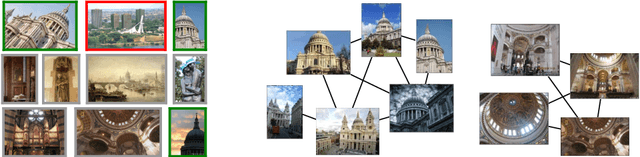
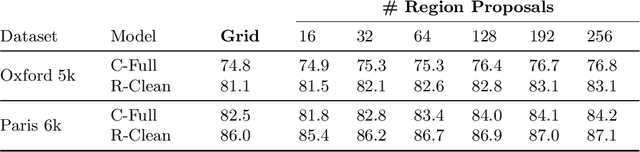
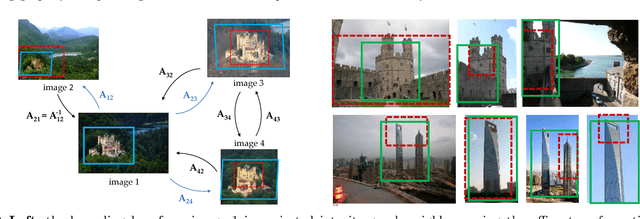
We propose a novel approach for instance-level image retrieval. It produces a global and compact fixed-length representation for each image by aggregating many region-wise descriptors. In contrast to previous works employing pre-trained deep networks as a black box to produce features, our method leverages a deep architecture trained for the specific task of image retrieval. Our contribution is twofold: (i) we leverage a ranking framework to learn convolution and projection weights that are used to build the region features; and (ii) we employ a region proposal network to learn which regions should be pooled to form the final global descriptor. We show that using clean training data is key to the success of our approach. To that aim, we use a large scale but noisy landmark dataset and develop an automatic cleaning approach. The proposed architecture produces a global image representation in a single forward pass. Our approach significantly outperforms previous approaches based on global descriptors on standard datasets. It even surpasses most prior works based on costly local descriptor indexing and spatial verification. Additional material is available at www.xrce.xerox.com/Deep-Image-Retrieval.
LEWIS: Latent Embeddings for Word Images and their Semantics
Sep 21, 2015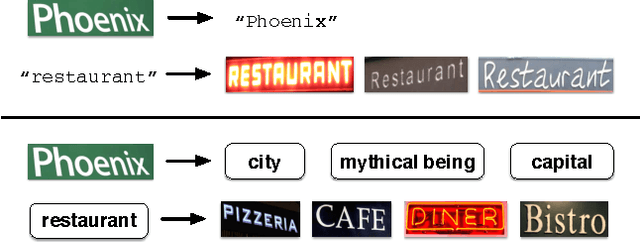

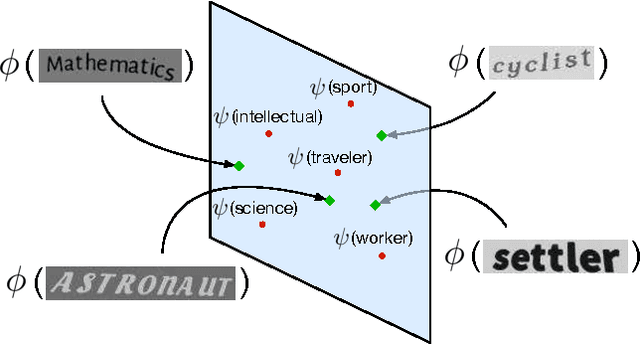
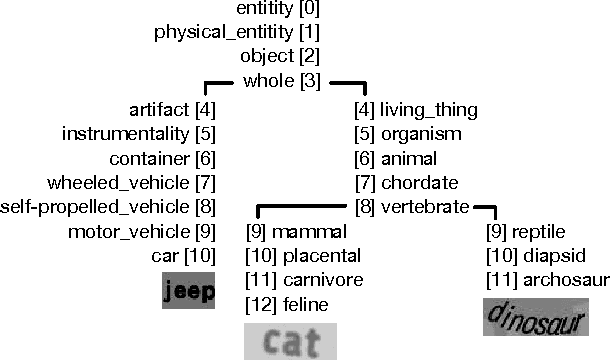
The goal of this work is to bring semantics into the tasks of text recognition and retrieval in natural images. Although text recognition and retrieval have received a lot of attention in recent years, previous works have focused on recognizing or retrieving exactly the same word used as a query, without taking the semantics into consideration. In this paper, we ask the following question: \emph{can we predict semantic concepts directly from a word image, without explicitly trying to transcribe the word image or its characters at any point?} For this goal we propose a convolutional neural network (CNN) with a weighted ranking loss objective that ensures that the concepts relevant to the query image are ranked ahead of those that are not relevant. This can also be interpreted as learning a Euclidean space where word images and concepts are jointly embedded. This model is learned in an end-to-end manner, from image pixels to semantic concepts, using a dataset of synthetically generated word images and concepts mined from a lexical database (WordNet). Our results show that, despite the complexity of the task, word images and concepts can indeed be associated with a high degree of accuracy