 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLDR: Twin Learning for Dimensionality Reduction
Paper and Code
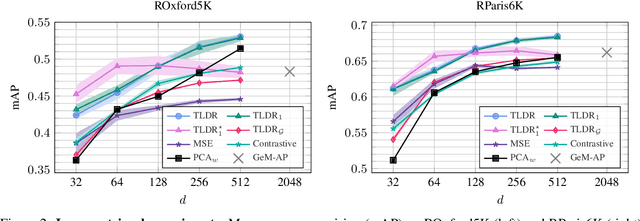

Dimensionality reduction methods are unsupervised approaches which learn low-dimensional spaces where some properties of the initial space, typically the notion of "neighborhood", are preserved. They are a crucial component of diverse tasks like visualization, compression, indexing, and retrieval. Aiming for a totally different goal, self-supervised visual representation learning has been shown to produce transferable representation functions by learning models that encode invariance to artificially created distortions, e.g. a set of hand-crafted image transformations. Unlike manifold learning methods that usually require propagation on large k-NN graphs or complicated optimization solvers, self-supervised learning approaches rely on simpler and more scalable frameworks for learning. In this paper, we unify these two families of approaches from the angle of manifold learning and propose TLDR, a dimensionality reduction method for generic input spaces that is porting the simple self-supervised learning framework of Barlow Twins to a setting where it is hard or impossible to define an appropriate set of distortions by hand. We propose to use nearest neighbors to build pairs from a training set and a redundancy reduction loss borrowed from the self-supervised literature to learn an encoder that produces representations invariant across such pairs. TLDR is a method that is simple, easy to implement and train, and of broad applicability; it consists of an offline nearest neighbor computation step that can be highly approximated, and a straightforward learning process that does not require mining negative samples to contrast, eigendecompositions, or cumbersome optimization solvers. By replacing PCA with TLDR, we are able to increase the performance of GeM-AP by 4% mAP for 128 dimensions, and to retain its performance with 16x fewer dimensions.