 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning of Deep Visual Representations for Image Retrieval
Paper and Code
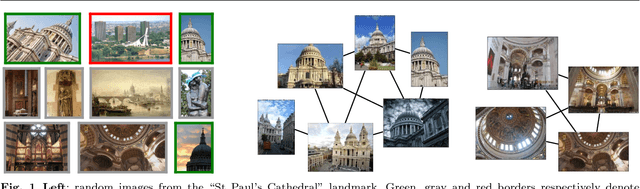
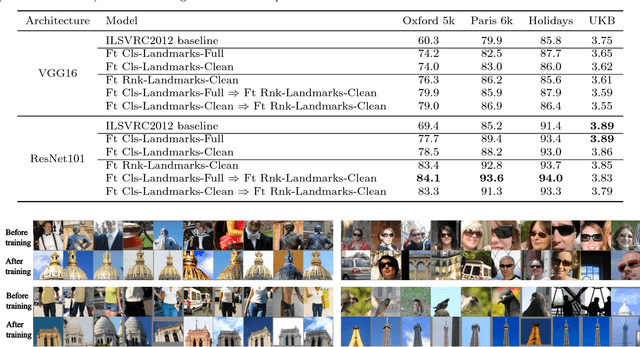
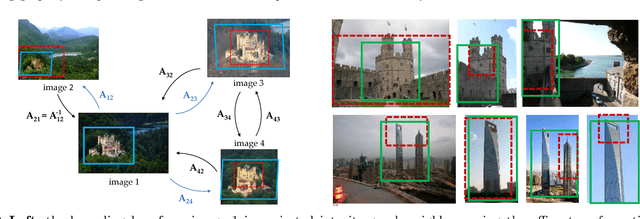

While deep learning has become a key ingredient in the top performing methods for many computer vision tasks, it has failed so far to bring similar improvements to instance-level image retrieval. In this article, we argue that reasons for the underwhelming results of deep methods on image retrieval are threefold: i) noisy training data, ii) inappropriate deep architecture, and iii) suboptimal training procedure. We address all three issues. First, we leverage a large-scale but noisy landmark dataset and develop an automatic cleaning method that produces a suitable training set for deep retrieval. Second, we build on the recent R-MAC descriptor, show that it can be interpreted as a deep and differentiable architecture, and present improvements to enhance it. Last, we train this network with a siamese architecture that combines three streams with a triplet loss. At the end of the training process, the proposed architecture produces a global image representation in a single forward pass that is well suited for image retrieval. Extensive experiments show that our approach significantly outperforms previous retrieval approaches, including state-of-the-art methods based on costly local descriptor indexing and spatial verification. On Oxford 5k, Paris 6k and Holidays, we respectively report 94.7, 96.6, and 94.8 mean average precision. Our representations can also be heavily compressed using product quantization with little loss in accuracy. For additional material, please see www.xrce.xerox.com/Deep-Image-Retrieval.