 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Alignment: A simple and effective proxy for model merging in computer vision
Apr 14, 2026Efficiently merging several models fine-tuned for different tasks, but stemming from the same pretrained base model, is of great practical interest. Despite extensive prior work, most evaluations of model merging in computer vision are restricted to image classification using CLIP, where different classification datasets define different tasks. In this work, our goal is to make model merging more practical and show its relevance on challenging scenarios beyond this specific setting. In most vision scenarios, different tasks rely on trainable and usually heterogeneous decoders. Differently from previous studies with frozen decoders, where merged models can be evaluated right away, the non-trivial cost of decoder training renders hyperparameter selection based on downstream performance impractical. To address this, we introduce the task alignment proxy, and show how it can be used to speed up hyperparameter selection by orders of magnitude while retaining performance. Equipped with the task alignment proxy, we extend the applicability of model merging to multi-task vision models beyond CLIP-based classification.
Interferences in match kernels
Nov 24, 2016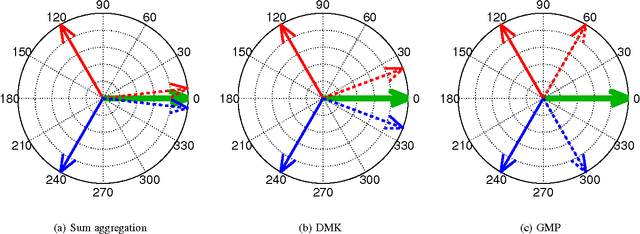
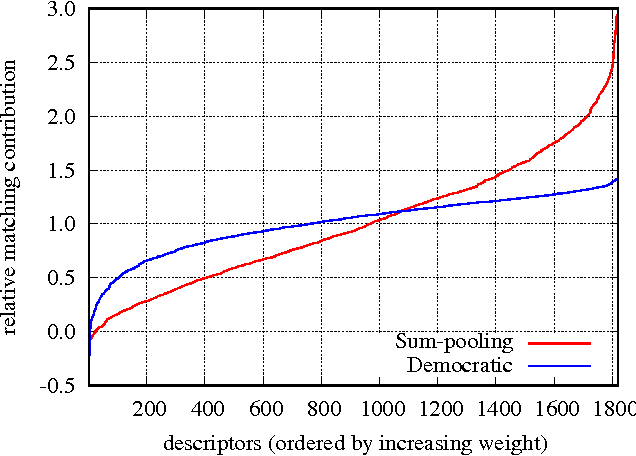
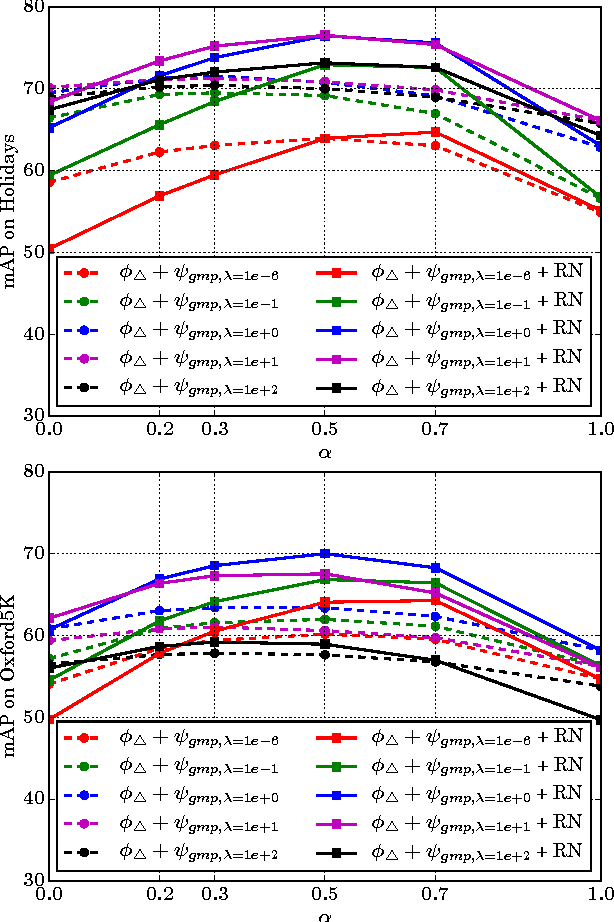
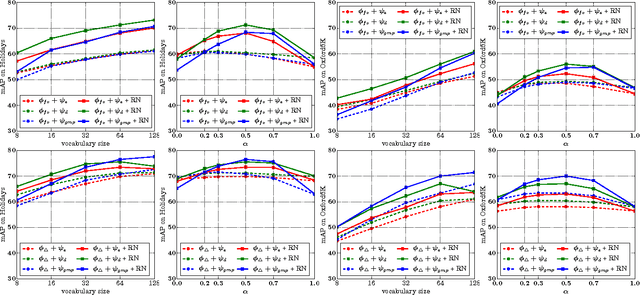
We consider the design of an image representation that embeds and aggregates a set of local descriptors into a single vector. Popular representations of this kind include the bag-of-visual-words, the Fisher vector and the VLAD. When two such image representations are compared with the dot-product, the image-to-image similarity can be interpreted as a match kernel. In match kernels, one has to deal with interference, i.e. with the fact that even if two descriptors are unrelated, their matching score may contribute to the overall similarity. We formalise this problem and propose two related solutions, both aimed at equalising the individual contributions of the local descriptors in the final representation. These methods modify the aggregation stage by including a set of per-descriptor weights. They differ by the objective function that is optimised to compute those weights. The first is a "democratisation" strategy that aims at equalising the relative importance of each descriptor in the set comparison metric. The second one involves equalising the match of a single descriptor to the aggregated vector. These concurrent methods give a substantial performance boost over the state of the art in image search with short or mid-size vectors, as demonstrated by our experiments on standard public image retrieval benchmarks.
Polysemous codes
Oct 10, 2016
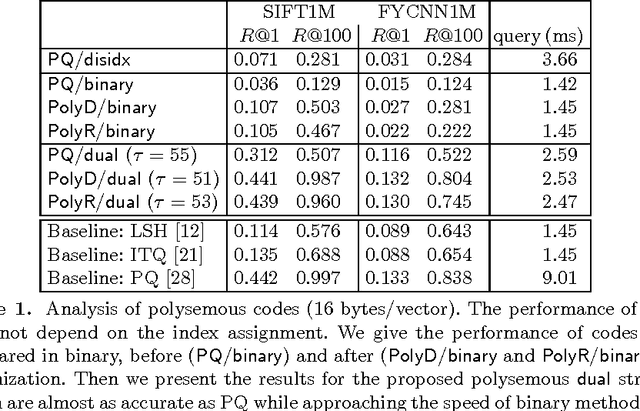


This paper considers the problem of approximate nearest neighbor search in the compressed domain. We introduce polysemous codes, which offer both the distance estimation quality of product quantization and the efficient comparison of binary codes with Hamming distance. Their design is inspired by algorithms introduced in the 90's to construct channel-optimized vector quantizers. At search time, this dual interpretation accelerates the search. Most of the indexed vectors are filtered out with Hamming distance, letting only a fraction of the vectors to be ranked with an asymmetric distance estimator. The method is complementary with a coarse partitioning of the feature space such as the inverted multi-index. This is shown by our experiments performed on several public benchmarks such as the BIGANN dataset comprising one billion vectors, for which we report state-of-the-art results for query times below 0.3\,millisecond per core. Last but not least, our approach allows the approximate computation of the k-NN graph associated with the Yahoo Flickr Creative Commons 100M, described by CNN image descriptors, in less than 8 hours on a single machine.
Convolutional Patch Representations for Image Retrieval: an Unsupervised Approach
Mar 01, 2016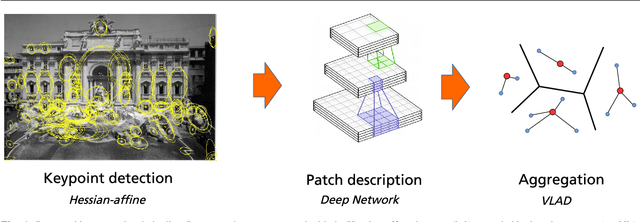

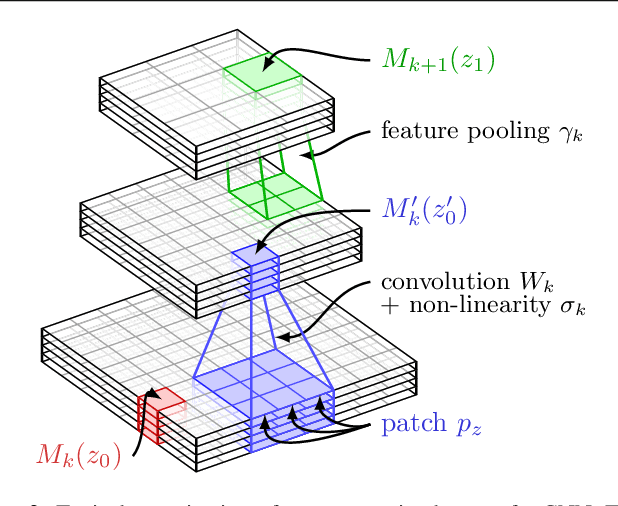
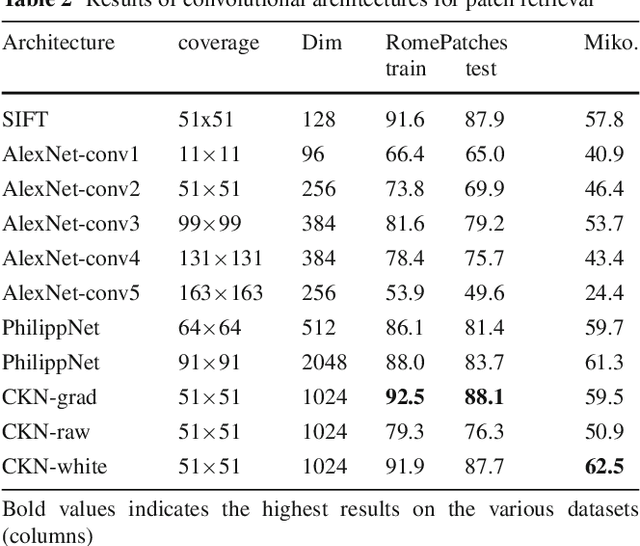
Convolutional neural networks (CNNs) have recently received a lot of attention due to their ability to model local stationary structures in natural images in a multi-scale fashion, when learning all model parameters with supervision. While excellent performance was achieved for image classification when large amounts of labeled visual data are available, their success for un-supervised tasks such as image retrieval has been moderate so far. Our paper focuses on this latter setting and explores several methods for learning patch descriptors without supervision with application to matching and instance-level retrieval. To that effect, we propose a new family of convolutional descriptors for patch representation , based on the recently introduced convolutional kernel networks. We show that our descriptor, named Patch-CKN, performs better than SIFT as well as other convolutional networks learned by artificially introducing supervision and is significantly faster to train. To demonstrate its effectiveness, we perform an extensive evaluation on standard benchmarks for patch and image retrieval where we obtain state-of-the-art results. We also introduce a new dataset called RomePatches, which allows to simultaneously study descriptor performance for patch and image retrieval.
Label-Embedding for Image Classification
Oct 01, 2015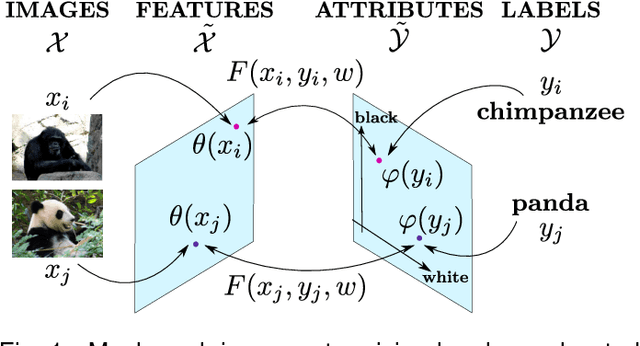
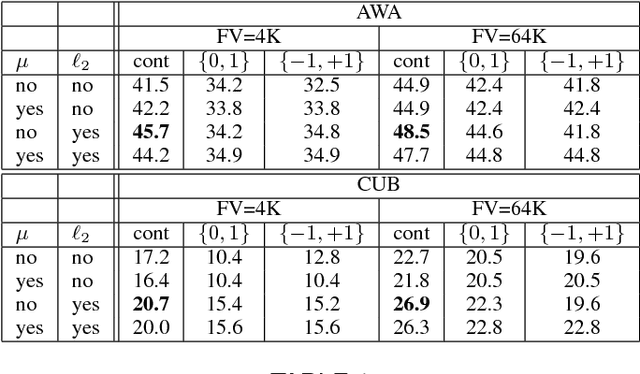
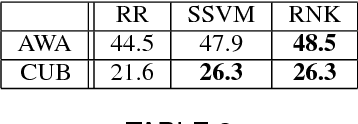
Attributes act as intermediate representations that enable parameter sharing between classes, a must when training data is scarce. We propose to view attribute-based image classification as a label-embedding problem: each class is embedded in the space of attribute vectors. We introduce a function that measures the compatibility between an image and a label embedding. The parameters of this function are learned on a training set of labeled samples to ensure that, given an image, the correct classes rank higher than the incorrect ones. Results on the Animals With Attributes and Caltech-UCSD-Birds datasets show that the proposed framework outperforms the standard Direct Attribute Prediction baseline in a zero-shot learning scenario. Label embedding enjoys a built-in ability to leverage alternative sources of information instead of or in addition to attributes, such as e.g. class hierarchies or textual descriptions. Moreover, label embedding encompasses the whole range of learning settings from zero-shot learning to regular learning with a large number of labeled examples.
LEWIS: Latent Embeddings for Word Images and their Semantics
Sep 21, 2015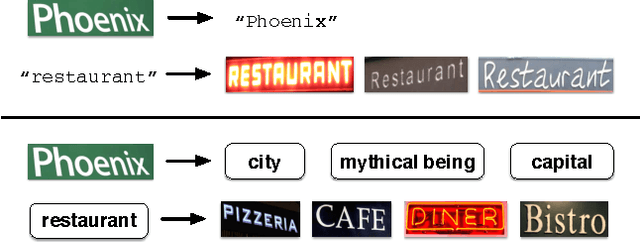

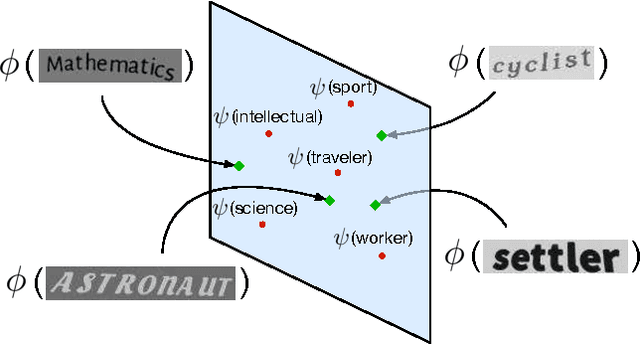
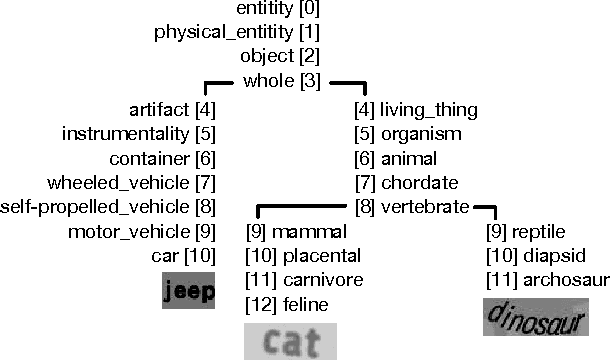
The goal of this work is to bring semantics into the tasks of text recognition and retrieval in natural images. Although text recognition and retrieval have received a lot of attention in recent years, previous works have focused on recognizing or retrieving exactly the same word used as a query, without taking the semantics into consideration. In this paper, we ask the following question: \emph{can we predict semantic concepts directly from a word image, without explicitly trying to transcribe the word image or its characters at any point?} For this goal we propose a convolutional neural network (CNN) with a weighted ranking loss objective that ensures that the concepts relevant to the query image are ranked ahead of those that are not relevant. This can also be interpreted as learning a Euclidean space where word images and concepts are jointly embedded. This model is learned in an end-to-end manner, from image pixels to semantic concepts, using a dataset of synthetically generated word images and concepts mined from a lexical database (WordNet). Our results show that, despite the complexity of the task, word images and concepts can indeed be associated with a high degree of accuracy
Deep Fishing: Gradient Features from Deep Nets
Jul 23, 2015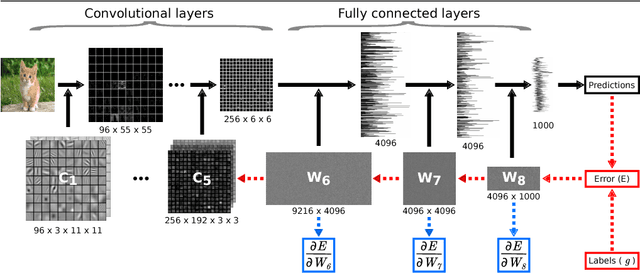
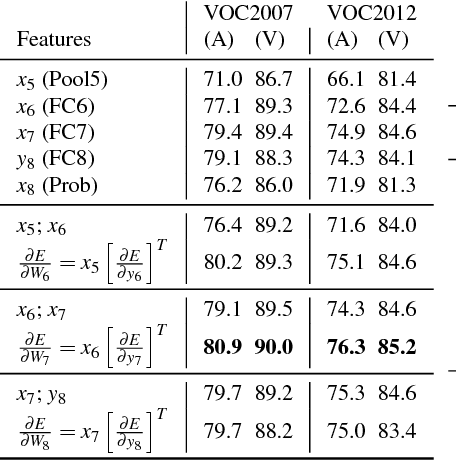
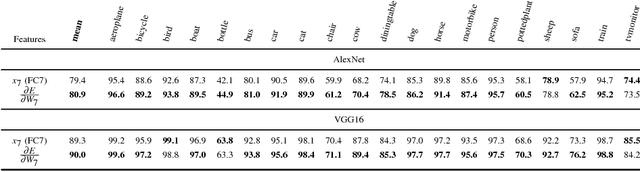
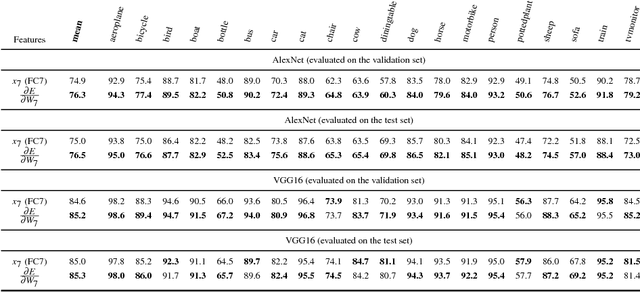
Convolutional Networks (ConvNets) have recently improved image recognition performance thanks to end-to-end learning of deep feed-forward models from raw pixels. Deep learning is a marked departure from the previous state of the art, the Fisher Vector (FV), which relied on gradient-based encoding of local hand-crafted features. In this paper, we discuss a novel connection between these two approaches. First, we show that one can derive gradient representations from ConvNets in a similar fashion to the FV. Second, we show that this gradient representation actually corresponds to a structured matrix that allows for efficient similarity computation. We experimentally study the benefits of transferring this representation over the outputs of ConvNet layers, and find consistent improvements on the Pascal VOC 2007 and 2012 datasets.
Understanding the Fisher Vector: a multimodal part model
Apr 18, 2015
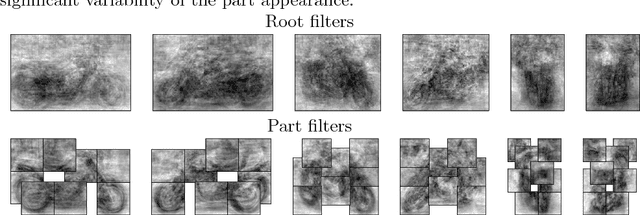
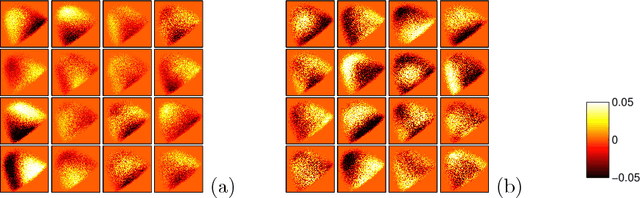

Fisher Vectors and related orderless visual statistics have demonstrated excellent performance in object detection, sometimes superior to established approaches such as the Deformable Part Models. However, it remains unclear how these models can capture complex appearance variations using visual codebooks of limited sizes and coarse geometric information. In this work, we propose to interpret Fisher-Vector-based object detectors as part-based models. Through the use of several visualizations and experiments, we show that this is a useful insight to explain the good performance of the model. Furthermore, we reveal for the first time several interesting properties of the FV, including its ability to work well using only a small subset of input patches and visual words. Finally, we discuss the relation of the FV and DPM detectors, pointing out differences and commonalities between them.
Discovering beautiful attributes for aesthetic image analysis
Dec 16, 2014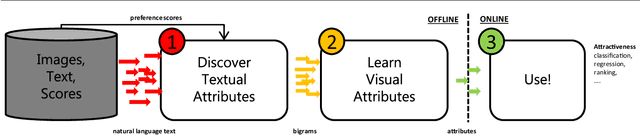
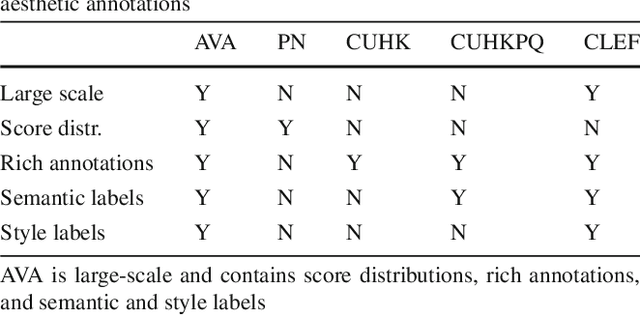

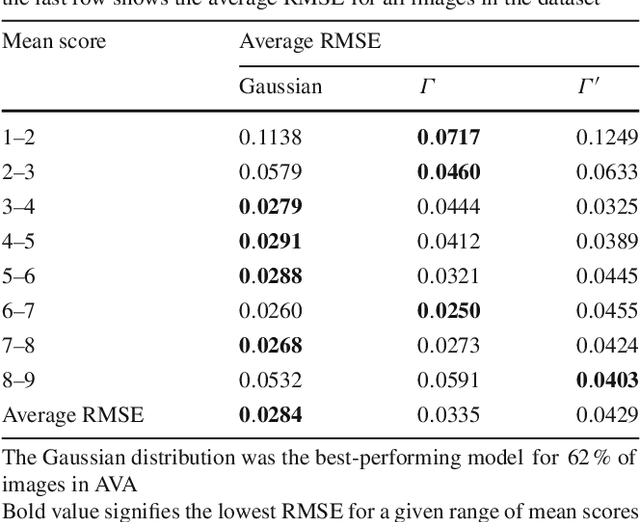
Aesthetic image analysis is the study and assessment of the aesthetic properties of images. Current computational approaches to aesthetic image analysis either provide accurate or interpretable results. To obtain both accuracy and interpretability by humans, we advocate the use of learned and nameable visual attributes as mid-level features. For this purpose, we propose to discover and learn the visual appearance of attributes automatically, using a recently introduced database, called AVA, which contains more than 250,000 images together with their aesthetic scores and textual comments given by photography enthusiasts. We provide a detailed analysis of these annotations as well as the context in which they were given. We then describe how these three key components of AVA - images, scores, and comments - can be effectively leveraged to learn visual attributes. Lastly, we show that these learned attributes can be successfully used in three applications: aesthetic quality prediction, image tagging and retrieval.
What makes an Image Iconic? A Fine-Grained Case Study
Aug 19, 2014
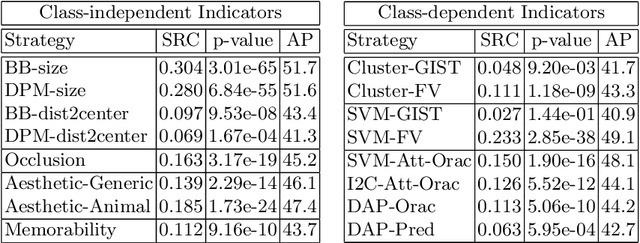

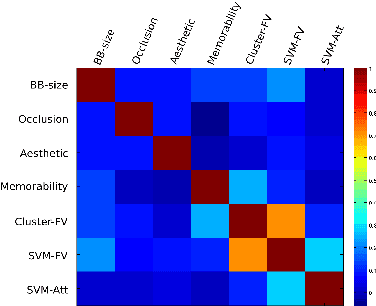
A natural approach to teaching a visual concept, e.g. a bird species, is to show relevant images. However, not all relevant images represent a concept equally well. In other words, they are not necessarily iconic. This observation raises three questions. Is iconicity a subjective property? If not, can we predict iconicity? And what exactly makes an image iconic? We provide answers to these questions through an extensive experimental study on a challenging fine-grained dataset of birds. We first show that iconicity ratings are consistent across individuals, even when they are not domain experts, thus demonstrating that iconicity is not purely subjective. We then consider an exhaustive list of properties that are intuitively related to iconicity and measure their correlation with these iconicity ratings. We combine them to predict iconicity of new unseen images. We also propose a direct iconicity predictor that is discriminatively trained with iconicity ratings. By combining both systems, we get an iconicity prediction that approaches human performance.