 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemous codes
Paper and Code

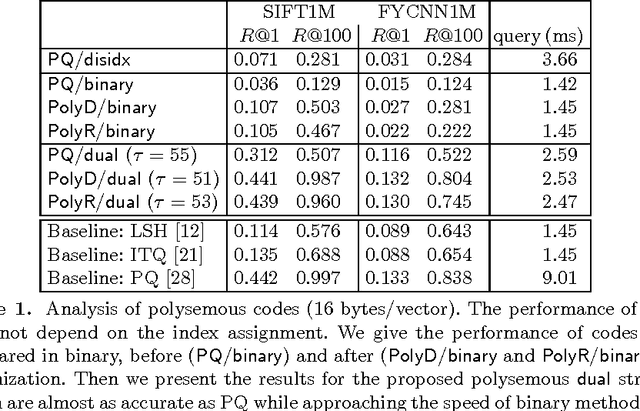


This paper considers the problem of approximate nearest neighbor search in the compressed domain. We introduce polysemous codes, which offer both the distance estimation quality of product quantization and the efficient comparison of binary codes with Hamming distance. Their design is inspired by algorithms introduced in the 90's to construct channel-optimized vector quantizers. At search time, this dual interpretation accelerates the search. Most of the indexed vectors are filtered out with Hamming distance, letting only a fraction of the vectors to be ranked with an asymmetric distance estimator. The method is complementary with a coarse partitioning of the feature space such as the inverted multi-index. This is shown by our experiments performed on several public benchmarks such as the BIGANN dataset comprising one billion vectors, for which we report state-of-the-art results for query times below 0.3\,millisecond per core. Last but not least, our approach allows the approximate computation of the k-NN graph associated with the Yahoo Flickr Creative Commons 100M, described by CNN image descriptors, in less than 8 hours on a single machine.