 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Fisher Vector: a multimodal part model
Paper and Code
Apr 18, 2015
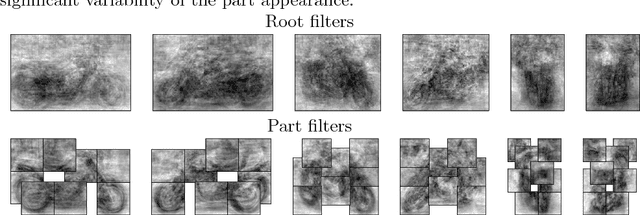
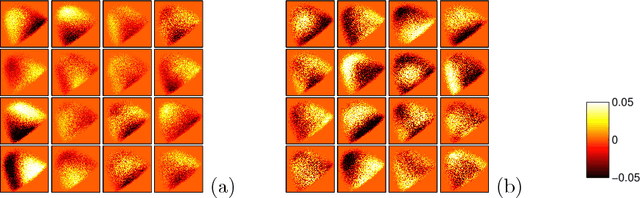

Fisher Vectors and related orderless visual statistics have demonstrated excellent performance in object detection, sometimes superior to established approaches such as the Deformable Part Models. However, it remains unclear how these models can capture complex appearance variations using visual codebooks of limited sizes and coarse geometric information. In this work, we propose to interpret Fisher-Vector-based object detectors as part-based models. Through the use of several visualizations and experiments, we show that this is a useful insight to explain the good performance of the model. Furthermore, we reveal for the first time several interesting properties of the FV, including its ability to work well using only a small subset of input patches and visual words. Finally, we discuss the relation of the FV and DPM detectors, pointing out differences and commonalities between them.