 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-MUSt3R: Sliding Multi-view 3D Reconstruction
Feb 04, 2026The recent paradigm shift in 3D vision led to the rise of foundation models with remarkable capabilities in 3D perception from uncalibrated images. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. This work proposes S-MUSt3R, a simple and efficient pipeline that extends the limits of foundation models for monocular 3D reconstruction. Our approach addresses the scalability bottleneck of foundation models through a simple strategy of sequence segmentation followed by segment alignment and lightweight loop closure optimization. Without model retraining, we benefit from remarkable 3D reconstruction capacities of MUSt3R model and achieve trajectory and reconstruction performance comparable to traditional methods with more complex architecture. We evaluate S-MUSt3R on TUM, 7-Scenes and proprietary robot navigation datasets and show that S-MUSt3R runs successfully on long RGB sequences and produces accurate and consistent 3D reconstruction. Our results highlight the potential of leveraging the MUSt3R model for scalable monocular 3D scene in real-world settings, with an important advantage of making predictions directly in the metric space.
PanSt3R: Multi-view Consistent Panoptic Segmentation
Jun 26, 2025Panoptic segmentation of 3D scenes, involving the segmentation and classification of object instances in a dense 3D reconstruction of a scene, is a challenging problem, especially when relying solely on unposed 2D images. Existing approaches typically leverage off-the-shelf models to extract per-frame 2D panoptic segmentations, before optimizing an implicit geometric representation (often based on NeRF) to integrate and fuse the 2D predictions. We argue that relying on 2D panoptic segmentation for a problem inherently 3D and multi-view is likely suboptimal as it fails to leverage the full potential of spatial relationships across views. In addition to requiring camera parameters, these approaches also necessitate computationally expensive test-time optimization for each scene. Instead, in this work, we propose a unified and integrated approach PanSt3R, which eliminates the need for test-time optimization by jointly predicting 3D geometry and multi-view panoptic segmentation in a single forward pass. Our approach builds upon recent advances in 3D reconstruction, specifically upon MUSt3R, a scalable multi-view version of DUSt3R, and enhances it with semantic awareness and multi-view panoptic segmentation capabilities. We additionally revisit the standard post-processing mask merging procedure and introduce a more principled approach for multi-view segmentation. We also introduce a simple method for generating novel-view predictions based on the predictions of PanSt3R and vanilla 3DGS. Overall, the proposed PanSt3R is conceptually simple, yet fast and scalable, and achieves state-of-the-art performance on several benchmarks, while being orders of magnitude faster than existing methods.
Reasoning in visual navigation of end-to-end trained agents: a dynamical systems approach
Mar 12, 2025Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at europe.naverlabs.com/research/publications/reasoning-in-visual-navigation-of-end-to-end-trained-agents.
MUSt3R: Multi-view Network for Stereo 3D Reconstruction
Mar 03, 2025DUSt3R introduced a novel paradigm in geometric computer vision by proposing a model that can provide dense and unconstrained Stereo 3D Reconstruction of arbitrary image collections with no prior information about camera calibration nor viewpoint poses. Under the hood, however, DUSt3R processes image pairs, regressing local 3D reconstructions that need to be aligned in a global coordinate system. The number of pairs, growing quadratically, is an inherent limitation that becomes especially concerning for robust and fast optimization in the case of large image collections. In this paper, we propose an extension of DUSt3R from pairs to multiple views, that addresses all aforementioned concerns. Indeed, we propose a Multi-view Network for Stereo 3D Reconstruction, or MUSt3R, that modifies the DUSt3R architecture by making it symmetric and extending it to directly predict 3D structure for all views in a common coordinate frame. Second, we entail the model with a multi-layer memory mechanism which allows to reduce the computational complexity and to scale the reconstruction to large collections, inferring thousands of 3D pointmaps at high frame-rates with limited added complexity. The framework is designed to perform 3D reconstruction both offline and online, and hence can be seamlessly applied to SfM and visual SLAM scenarios showing state-of-the-art performance on various 3D downstream tasks, including uncalibrated Visual Odometry, relative camera pose, scale and focal estimation, 3D reconstruction and multi-view depth estimation.
3D-Consistent Image Inpainting with Diffusion Models
Dec 08, 2024We address the problem of 3D inconsistency of image inpainting based on diffusion models. We propose a generative model using image pairs that belong to the same scene. To achieve the 3D-consistent and semantically coherent inpainting, we modify the generative diffusion model by incorporating an alternative point of view of the scene into the denoising process. This creates an inductive bias that allows to recover 3D priors while training to denoise in 2D, without explicit 3D supervision. Training unconditional diffusion models with additional images as in-context guidance allows to harmonize the masked and non-masked regions while repainting and ensures the 3D consistency. We evaluate our method on one synthetic and three real-world datasets and show that it generates semantically coherent and 3D-consistent inpaintings and outperforms the state-of-art methods.
Self-supervised Pretraining and Finetuning for Monocular Depth and Visual Odometry
Jun 16, 2024For the task of simultaneous monocular depth and visual odometry estimation, we propose learning self-supervised transformer-based models in two steps. Our first step consists in a generic pretraining to learn 3D geometry, using cross-view completion objective (CroCo), followed by self-supervised finetuning on non-annotated videos. We show that our self-supervised models can reach state-of-the-art performance 'without bells and whistles' using standard components such as visual transformers, dense prediction transformers and adapters. We demonstrate the effectiveness of our proposed method by running evaluations on six benchmark datasets, both static and dynamic, indoor and outdoor, with synthetic and real images. For all datasets, our method outperforms state-of-the-art methods, in particular for depth prediction task.
Zero-BEV: Zero-shot Projection of Any First-Person Modality to BEV Maps
Feb 21, 2024Bird's-eye view (BEV) maps are an important geometrically structured representation widely used in robotics, in particular self-driving vehicles and terrestrial robots. Existing algorithms either require depth information for the geometric projection, which is not always reliably available, or are trained end-to-end in a fully supervised way to map visual first-person observations to BEV representation, and are therefore restricted to the output modality they have been trained for. In contrast, we propose a new model capable of performing zero-shot projections of any modality available in a first person view to the corresponding BEV map. This is achieved by disentangling the geometric inverse perspective projection from the modality transformation, eg. RGB to occupancy. The method is general and we showcase experiments projecting to BEV three different modalities: semantic segmentation, motion vectors and object bounding boxes detected in first person. We experimentally show that the model outperforms competing methods, in particular the widely used baseline resorting to monocular depth estimation.
Learning to navigate efficiently and precisely in real environments
Jan 25, 2024In the context of autonomous navigation of terrestrial robots, the creation of realistic models for agent dynamics and sensing is a widespread habit in the robotics literature and in commercial applications, where they are used for model based control and/or for localization and mapping. The more recent Embodied AI literature, on the other hand, focuses on modular or end-to-end agents trained in simulators like Habitat or AI-Thor, where the emphasis is put on photo-realistic rendering and scene diversity, but high-fidelity robot motion is assigned a less privileged role. The resulting sim2real gap significantly impacts transfer of the trained models to real robotic platforms. In this work we explore end-to-end training of agents in simulation in settings which minimize the sim2real gap both, in sensing and in actuation. Our agent directly predicts (discretized) velocity commands, which are maintained through closed-loop control in the real robot. The behavior of the real robot (including the underlying low-level controller) is identified and simulated in a modified Habitat simulator. Noise models for odometry and localization further contribute in lowering the sim2real gap. We evaluate on real navigation scenarios, explore different localization and point goal calculation methods and report significant gains in performance and robustness compared to prior work.
Multi-Object Navigation in real environments using hybrid policies
Jan 24, 2024Navigation has been classically solved in robotics through the combination of SLAM and planning. More recently, beyond waypoint planning, problems involving significant components of (visual) high-level reasoning have been explored in simulated environments, mostly addressed with large-scale machine learning, in particular RL, offline-RL or imitation learning. These methods require the agent to learn various skills like local planning, mapping objects and querying the learned spatial representations. In contrast to simpler tasks like waypoint planning (PointGoal), for these more complex tasks the current state-of-the-art models have been thoroughly evaluated in simulation but, to our best knowledge, not yet in real environments. In this work we focus on sim2real transfer. We target the challenging Multi-Object Navigation (Multi-ON) task and port it to a physical environment containing real replicas of the originally virtual Multi-ON objects. We introduce a hybrid navigation method, which decomposes the problem into two different skills: (1) waypoint navigation is addressed with classical SLAM combined with a symbolic planner, whereas (2) exploration, semantic mapping and goal retrieval are dealt with deep neural networks trained with a combination of supervised learning and RL. We show the advantages of this approach compared to end-to-end methods both in simulation and a real environment and outperform the SOTA for this task.
DUSt3R: Geometric 3D Vision Made Easy
Dec 21, 2023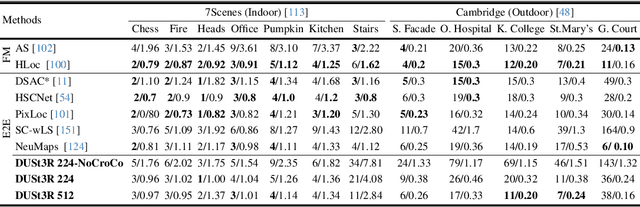
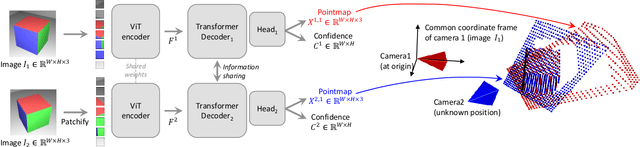
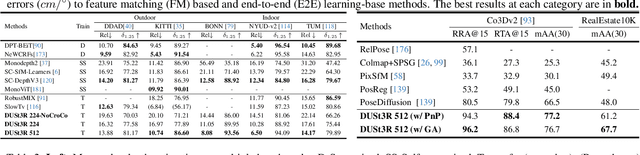

Multi-view stereo reconstruction (MVS) in the wild requires to first estimate the camera parameters e.g. intrinsic and extrinsic parameters. These are usually tedious and cumbersome to obtain, yet they are mandatory to triangulate corresponding pixels in 3D space, which is the core of all best performing MVS algorithms. In this work, we take an opposite stance and introduce DUSt3R, a radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction of arbitrary image collections, i.e. operating without prior information about camera calibration nor viewpoint poses. We cast the pairwise reconstruction problem as a regression of pointmaps, relaxing the hard constraints of usual projective camera models. We show that this formulation smoothly unifies the monocular and binocular reconstruction cases. In the case where more than two images are provided, we further propose a simple yet effective global alignment strategy that expresses all pairwise pointmaps in a common reference frame. We base our network architecture on standard Transformer encoders and decoders, allowing us to leverage powerful pretrained models. Our formulation directly provides a 3D model of the scene as well as depth information, but interestingly, we can seamlessly recover from it, pixel matches, relative and absolute camera. Exhaustive experiments on all these tasks showcase that the proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on monocular/multi-view depth estimation as well as relative pose estimation. In summary, DUSt3R makes many geometric 3D vision tasks easy.