 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End -Image Goal Navigation through Correspondence as an Emergent Phenomenon
Paper and Code
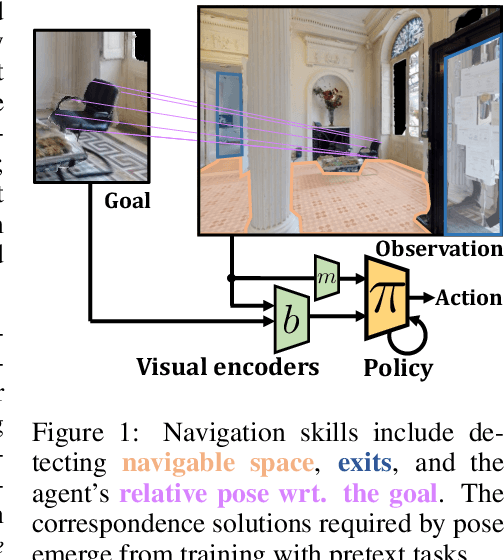


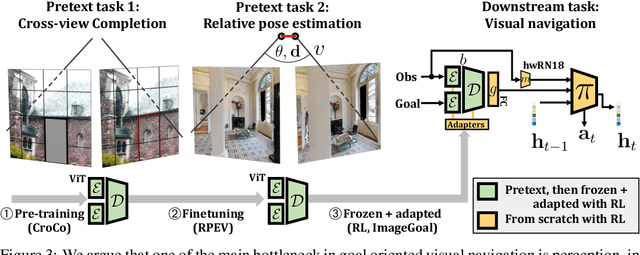
Most recent work in goal oriented visual navigation resorts to large-scale machine learning in simulated environments. The main challenge lies in learning compact representations generalizable to unseen environments and in learning high-capacity perception modules capable of reasoning on high-dimensional input. The latter is particularly difficult when the goal is not given as a category ("ObjectNav") but as an exemplar image ("ImageNav"), as the perception module needs to learn a comparison strategy requiring to solve an underlying visual correspondence problem. This has been shown to be difficult from reward alone or with standard auxiliary tasks. We address this problem through a sequence of two pretext tasks, which serve as a prior for what we argue is one of the main bottleneck in perception, extremely wide-baseline relative pose estimation and visibility prediction in complex scenes. The first pretext task, cross-view completion is a proxy for the underlying visual correspondence problem, while the second task addresses goal detection and finding directly. We propose a new dual encoder with a large-capacity binocular ViT model and show that correspondence solutions naturally emerge from the training signals. Experiments show significant improvements and SOTA performance on the two benchmarks, ImageNav and the Instance-ImageNav variant, where camera intrinsics and height differ between observation and goal.