 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Navigation in real environments using hybrid policies
Jan 24, 2024Navigation has been classically solved in robotics through the combination of SLAM and planning. More recently, beyond waypoint planning, problems involving significant components of (visual) high-level reasoning have been explored in simulated environments, mostly addressed with large-scale machine learning, in particular RL, offline-RL or imitation learning. These methods require the agent to learn various skills like local planning, mapping objects and querying the learned spatial representations. In contrast to simpler tasks like waypoint planning (PointGoal), for these more complex tasks the current state-of-the-art models have been thoroughly evaluated in simulation but, to our best knowledge, not yet in real environments. In this work we focus on sim2real transfer. We target the challenging Multi-Object Navigation (Multi-ON) task and port it to a physical environment containing real replicas of the originally virtual Multi-ON objects. We introduce a hybrid navigation method, which decomposes the problem into two different skills: (1) waypoint navigation is addressed with classical SLAM combined with a symbolic planner, whereas (2) exploration, semantic mapping and goal retrieval are dealt with deep neural networks trained with a combination of supervised learning and RL. We show the advantages of this approach compared to end-to-end methods both in simulation and a real environment and outperform the SOTA for this task.
Subjective and Objective Visual Quality Assessment of Textured 3D Meshes
Feb 08, 2021
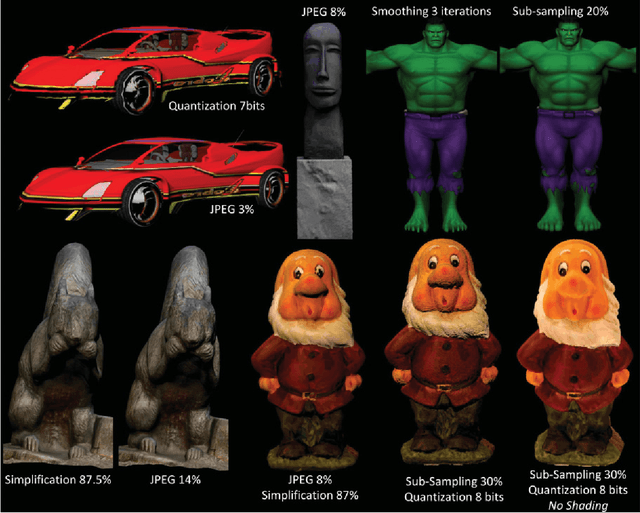

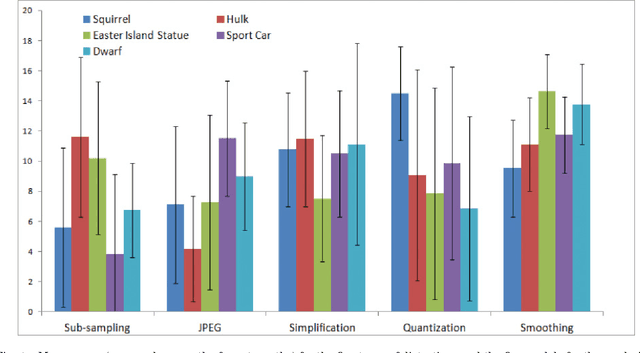
Objective visual quality assessment of 3D models is a fundamental issue in computer graphics. Quality assessment metrics may allow a wide range of processes to be guided and evaluated, such as level of detail creation, compression, filtering, and so on. Most computer graphics assets are composed of geometric surfaces on which several texture images can be mapped to 11 make the rendering more realistic. While some quality assessment metrics exist for geometric surfaces, almost no research has been conducted on the evaluation of texture-mapped 3D models. In this context, we present a new subjective study to evaluate the perceptual quality of textured meshes, based on a paired comparison protocol. We introduce both texture and geometry distortions on a set of 5 reference models to produce a database of 136 distorted models, evaluated using two rendering protocols. Based on analysis of the results, we propose two new metrics for visual quality assessment of textured mesh, as optimized linear combinations of accurate geometry and texture quality measurements. These proposed perceptual metrics outperform their counterparts in terms of correlation with human opinion. The database, along with the associated subjective scores, will be made publicly available online.
Multi-view pose estimation with mixtures-of-parts and adaptive viewpoint selection
Sep 25, 2017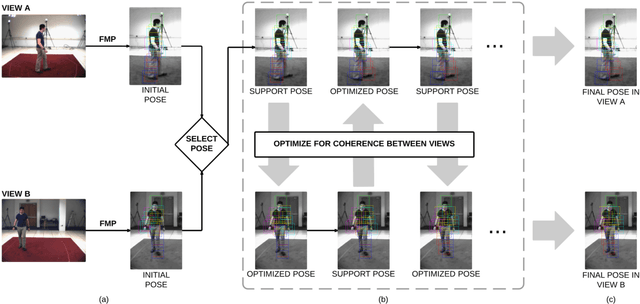
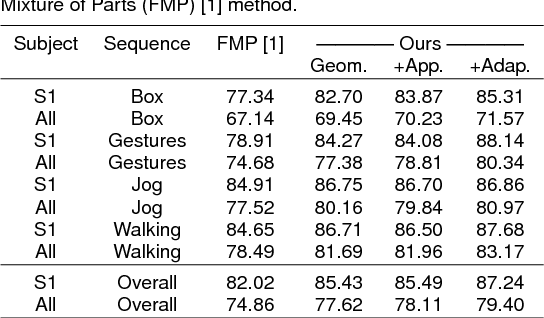

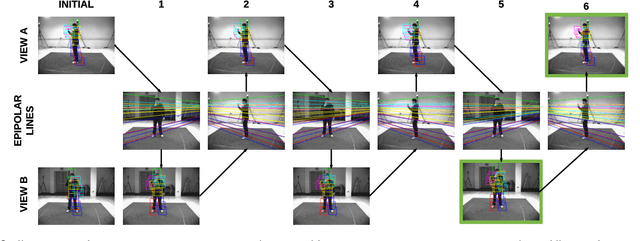
We propose a new method for human pose estimation which leverages information from multiple views to impose a strong prior on articulated pose. The novelty of the method concerns the types of coherence modelled. Consistency is maximised over the different views through different terms modelling classical geometric information (coherence of the resulting poses) as well as appearance information which is modelled as latent variables in the global energy function. Moreover, adequacy of each view is assessed and their contributions are adjusted accordingly. Experiments on the HumanEva and UMPM datasets show that the proposed method significantly decreases the estimation error compared to single-view results.
End-to-End Data Visualization by Metric Learning and Coordinate Transformation
Dec 27, 2016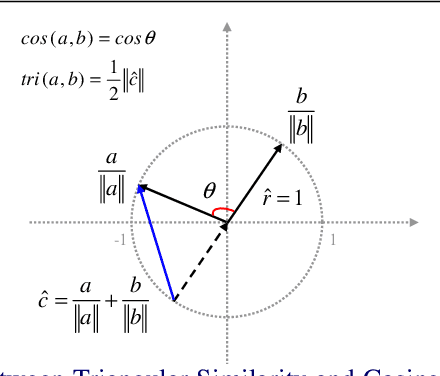



This paper presents a deep nonlinear metric learning framework for data visualization on an image dataset. We propose the Triangular Similarity and prove its equivalence to the Cosine Similarity in measuring a data pair. Based on this novel similarity, a geometrically motivated loss function - the triangular loss - is then developed for optimizing a metric learning system comprising two identical CNNs. It is shown that this deep nonlinear system can be efficiently trained by a hybrid algorithm based on the conventional backpropagation algorithm. More interestingly, benefiting from classical manifold learning theories, the proposed system offers two different views to visualize the outputs, the second of which provides better classification results than the state-of-the-art methods in the visualizable spaces.