 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERDE: Entropy-Regularized Distillation for Early-exit
Oct 06, 2025Although deep neural networks and in particular Convolutional Neural Networks have demonstrated state-of-the-art performance in image classification with relatively high efficiency, they still exhibit high computational costs, often rendering them impractical for real-time and edge applications. Therefore, a multitude of compression techniques have been developed to reduce these costs while maintaining accuracy. In addition, dynamic architectures have been introduced to modulate the level of compression at execution time, which is a desirable property in many resource-limited application scenarios. The proposed method effectively integrates two well-established optimization techniques: early exits and knowledge distillation, where a reduced student early-exit model is trained from a more complex teacher early-exit model. The primary contribution of this research lies in the approach for training the student early-exit model. In comparison to the conventional Knowledge Distillation loss, our approach incorporates a new entropy-based loss for images where the teacher's classification was incorrect. The proposed method optimizes the trade-off between accuracy and efficiency, thereby achieving significant reductions in computational complexity without compromising classification performance. The validity of this approach is substantiated by experimental results on image classification datasets CIFAR10, CIFAR100 and SVHN, which further opens new research perspectives for Knowledge Distillation in other contexts.
Improving Information Extraction on Business Documents with Specific Pre-Training Tasks
Sep 11, 2023Transformer-based Language Models are widely used in Natural Language Processing related tasks. Thanks to their pre-training, they have been successfully adapted to Information Extraction in business documents. However, most pre-training tasks proposed in the literature for business documents are too generic and not sufficient to learn more complex structures. In this paper, we use LayoutLM, a language model pre-trained on a collection of business documents, and introduce two new pre-training tasks that further improve its capacity to extract relevant information. The first is aimed at better understanding the complex layout of documents, and the second focuses on numeric values and their order of magnitude. These tasks force the model to learn better-contextualized representations of the scanned documents. We further introduce a new post-processing algorithm to decode BIESO tags in Information Extraction that performs better with complex entities. Our method significantly improves extraction performance on both public (from 93.88 to 95.50 F1 score) and private (from 84.35 to 84.84 F1 score) datasets composed of expense receipts, invoices, and purchase orders.
* Conference: Document Analysis Systems. DAS 2022
Long-Range Transformer Architectures for Document Understanding
Sep 11, 2023Since their release, Transformers have revolutionized many fields from Natural Language Understanding to Computer Vision. Document Understanding (DU) was not left behind with first Transformer based models for DU dating from late 2019. However, the computational complexity of the self-attention operation limits their capabilities to small sequences. In this paper we explore multiple strategies to apply Transformer based models to long multi-page documents. We introduce 2 new multi-modal (text + layout) long-range models for DU. They are based on efficient implementations of Transformers for long sequences. Long-range models can process whole documents at once effectively and are less impaired by the document's length. We compare them to LayoutLM, a classical Transformer adapted for DU and pre-trained on millions of documents. We further propose 2D relative attention bias to guide self-attention towards relevant tokens without harming model efficiency. We observe improvements on multi-page business documents on Information Retrieval for a small performance cost on smaller sequences. Relative 2D attention revealed to be effective on dense text for both normal and long-range models.
* Conference: ICDAR 2023 Workshops on Document Analysis and Recognition
Learning Sparse Filters in Deep Convolutional Neural Networks with a l1/l2 Pseudo-Norm
Jul 20, 2020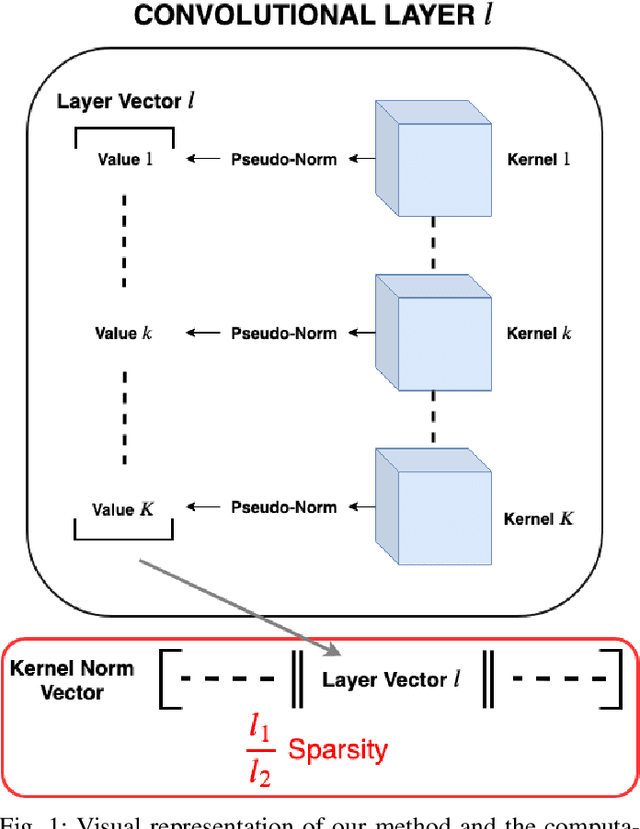


While deep neural networks (DNNs) have proven to be efficient for numerous tasks, they come at a high memory and computation cost, thus making them impractical on resource-limited devices. However, these networks are known to contain a large number of parameters. Recent research has shown that their structure can be more compact without compromising their performance. In this paper, we present a sparsity-inducing regularization term based on the ratio l1/l2 pseudo-norm defined on the filter coefficients. By defining this pseudo-norm appropriately for the different filter kernels, and removing irrelevant filters, the number of kernels in each layer can be drastically reduced leading to very compact Deep Convolutional Neural Networks (DCNN) structures. Unlike numerous existing methods, our approach does not require an iterative retraining process and, using this regularization term, directly produces a sparse model during the training process. Furthermore, our approach is also much easier and simpler to implement than existing methods. Experimental results on MNIST and CIFAR-10 show that our approach significantly reduces the number of filters of classical models such as LeNet and VGG while reaching the same or even better accuracy than the baseline models. Moreover, the trade-off between the sparsity and the accuracy is compared to other loss regularization terms based on the l1 or l2 norm as well as the SSL, NISP and GAL methods and shows that our approach is outperforming them.
Facial Landmark Correlation Analysis
Nov 24, 2019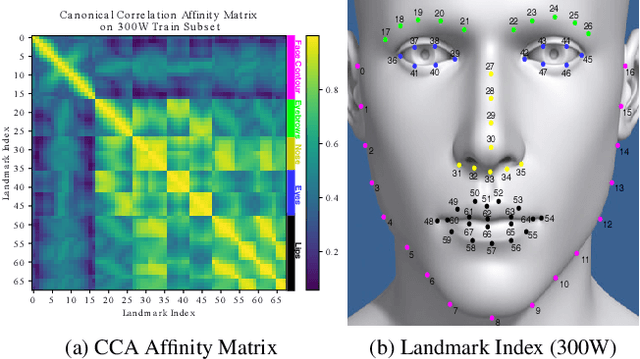



We present a facial landmark position correlation analysis as well as its applications. Although numerous facial landmark detection methods have been presented in the literature, few of them concern the intrinsic relationship among the landmarks. In order to reveal and interpret this relationship, we propose to analyze the facial landmark correlation by using Canonical Correlation Analysis (CCA). We experimentally show that dense facial landmark annotations in current benchmarks are strongly correlated, and we propose several applications based on this analysis. First, we give insights into the predictions from different facial landmark detection models (including cascaded random forests, cascaded Convolutional Neural Networks (CNNs), heatmap regression models) and interpret how CNNs progressively learn to predict facial landmarks. Second, we propose a few-shot learning method that allows to considerably reduce manual effort for dense landmark annotation. To this end, we select a portion of landmarks from the dense annotation format to form a sparse format, which is mostly correlated to the rest of them. Thanks to the strong correlation among the landmarks, the entire set of dense facial landmarks can then be inferred from the annotation in the sparse format by transfer learning. Unlike the previous methods, we mainly focus on how to find the most efficient sparse format to annotate. Overall, our correlation analysis provides new perspectives for the research on facial landmark detection.
2D Wasserstein Loss for Robust Facial Landmark Detection
Nov 24, 2019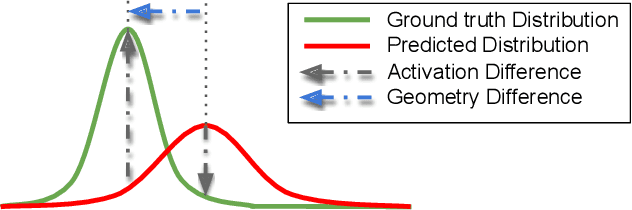
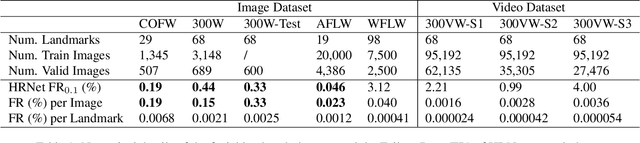

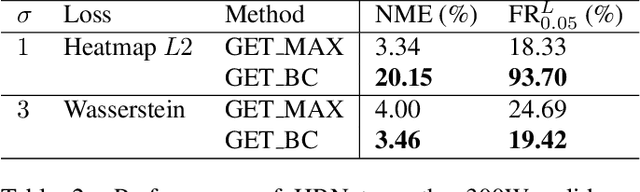
Facial landmark detection is an important preprocessing task for most applications related to face analysis. In recent years, the performance of facial landmark detection has been significantly improved by using deep Convolutional Neural Networks (CNNs), especially the Heatmap Regression Models (HRMs). Although their performance on common benchmark datasets have reached a high level, the robustness of these models still remains a challenging problem in the practical use under more noisy conditions of realistic environments. Contrary to most existing work focusing on the design of new models, we argue that improving the robustness requires rethinking many other aspects, including the use of datasets, the format of landmark annotation, the evaluation metric as well as the training and detection algorithm itself. In this paper, we propose a novel method for robust facial landmark detection using a loss function based on the 2D Wasserstein distance combined with a new landmark coordinate sampling relying on the barycenter of the individual propability distributions. The most intriguing fact of our method is that it can be plugged-and-play on most state-of-the-art HRMs with neither additional complexity nor structural modifications of the models. Further, with the large performance increase of state-of-the-art deep CNN models, we found that current evaluation metrics can no longer fully reflect the robustness of these models. Therefore, we propose several improvements on the standard evaluation protocol. Extensive experimental results on both traditional evaluation metrics and our evaluation metrics demonstrate that our approach significantly improves the robustness of state-of-the-art facial landmark detection models.
Routine Modeling with Time Series Metric Learning
Jul 08, 2019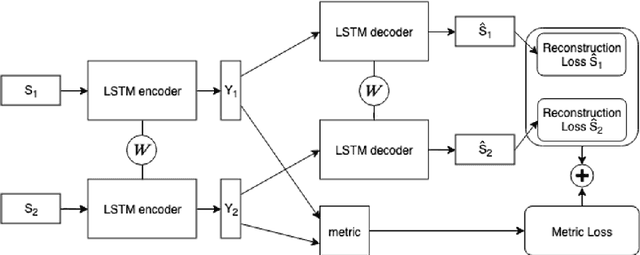
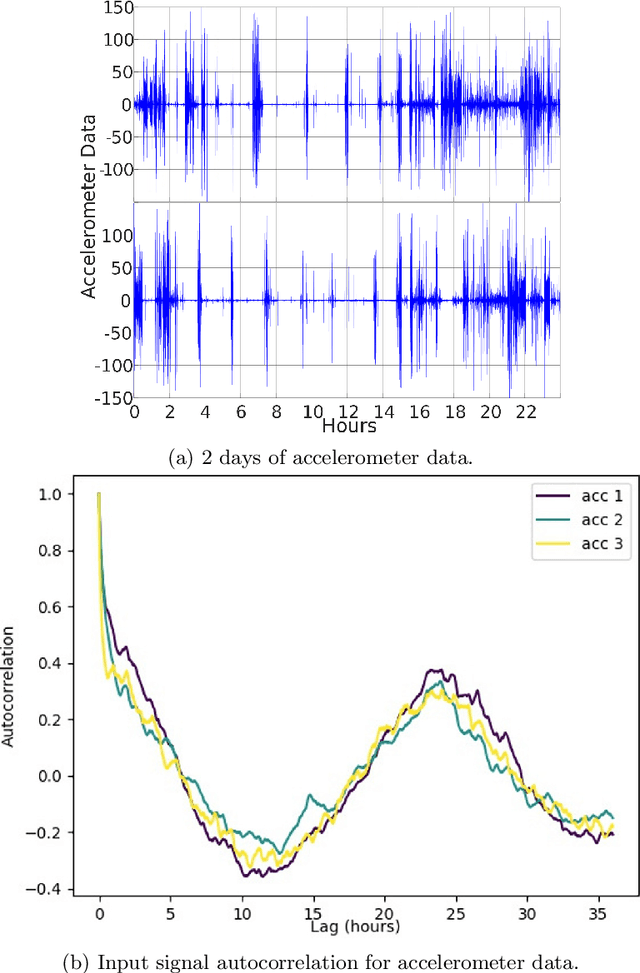
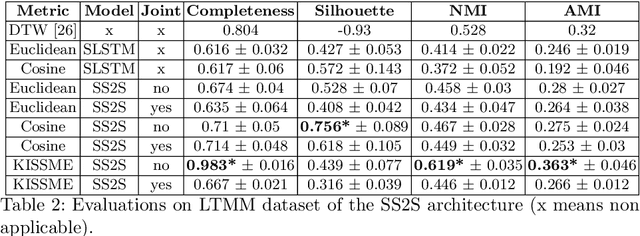
Traditionally, the automatic recognition of human activities is performed with supervised learning algorithms on limited sets of specific activities. This work proposes to recognize recurrent activity patterns, called routines, instead of precisely defined activities. The modeling of routines is defined as a metric learning problem, and an architecture, called SS2S, based on sequence-to-sequence models is proposed to learn a distance between time series. This approach only relies on inertial data and is thus non intrusive and preserves privacy. Experimental results show that a clustering algorithm provided with the learned distance is able to recover daily routines.
End-to-End Data Visualization by Metric Learning and Coordinate Transformation
Dec 27, 2016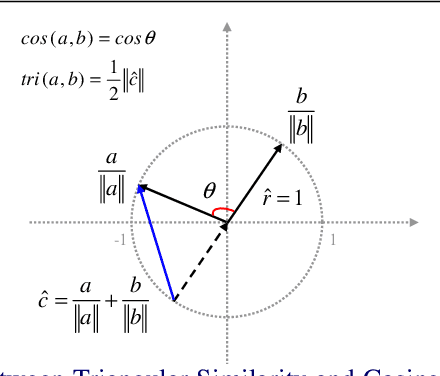



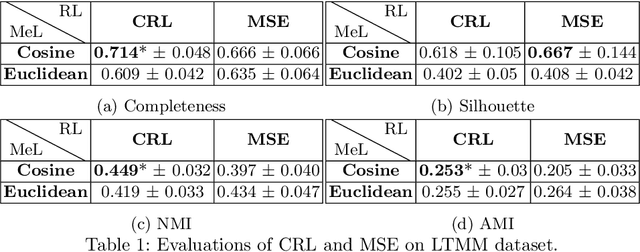
This paper presents a deep nonlinear metric learning framework for data visualization on an image dataset. We propose the Triangular Similarity and prove its equivalence to the Cosine Similarity in measuring a data pair. Based on this novel similarity, a geometrically motivated loss function - the triangular loss - is then developed for optimizing a metric learning system comprising two identical CNNs. It is shown that this deep nonlinear system can be efficiently trained by a hybrid algorithm based on the conventional backpropagation algorithm. More interestingly, benefiting from classical manifold learning theories, the proposed system offers two different views to visualize the outputs, the second of which provides better classification results than the state-of-the-art methods in the visualizable spaces.
Improving Texture Categorization with Biologically Inspired Filtering
Nov 30, 2013


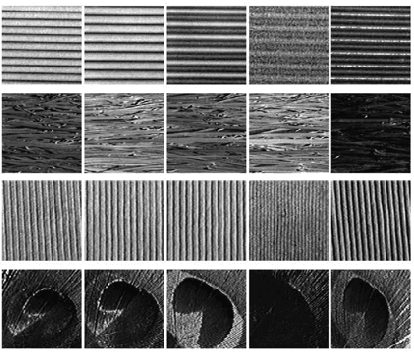
Within the domain of texture classification, a lot of effort has been spent on local descriptors, leading to many powerful algorithms. However, preprocessing techniques have received much less attention despite their important potential for improving the overall classification performance. We address this question by proposing a novel, simple, yet very powerful biologically-inspired filtering (BF) which simulates the performance of human retina. In the proposed approach, given a texture image, after applying a DoG filter to detect the "edges", we first split the filtered image into two "maps" alongside the sides of its edges. The feature extraction step is then carried out on the two "maps" instead of the input image. Our algorithm has several advantages such as simplicity, robustness to illumination and noise, and discriminative power. Experimental results on three large texture databases show that with an extremely low computational cost, the proposed method improves significantly the performance of many texture classification systems, notably in noisy environments. The source codes of the proposed algorithm can be downloaded from https://sites.google.com/site/nsonvu/code.