 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Filters in Deep Convolutional Neural Networks with a l1/l2 Pseudo-Norm
Paper and Code
Jul 20, 2020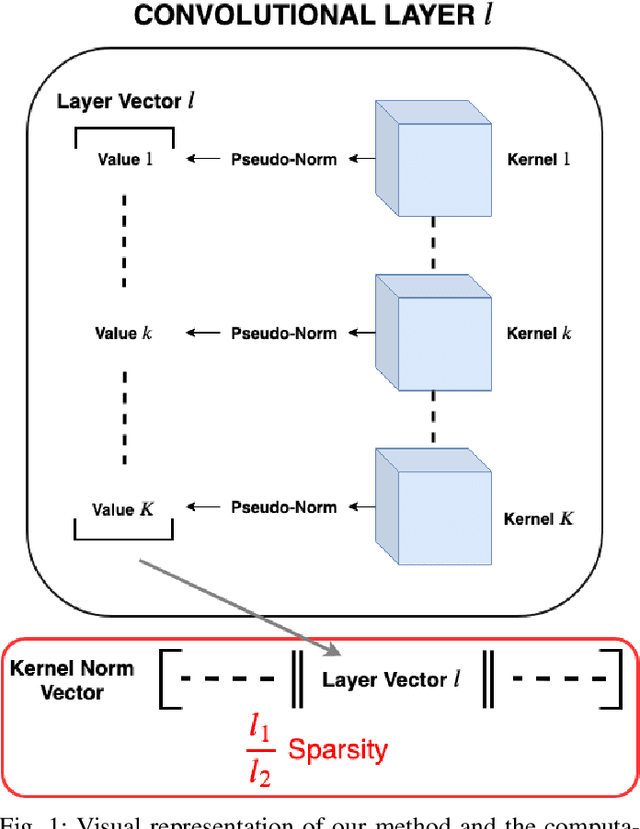


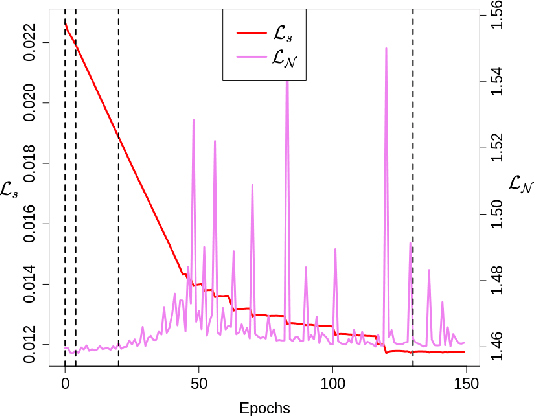
While deep neural networks (DNNs) have proven to be efficient for numerous tasks, they come at a high memory and computation cost, thus making them impractical on resource-limited devices. However, these networks are known to contain a large number of parameters. Recent research has shown that their structure can be more compact without compromising their performance. In this paper, we present a sparsity-inducing regularization term based on the ratio l1/l2 pseudo-norm defined on the filter coefficients. By defining this pseudo-norm appropriately for the different filter kernels, and removing irrelevant filters, the number of kernels in each layer can be drastically reduced leading to very compact Deep Convolutional Neural Networks (DCNN) structures. Unlike numerous existing methods, our approach does not require an iterative retraining process and, using this regularization term, directly produces a sparse model during the training process. Furthermore, our approach is also much easier and simpler to implement than existing methods. Experimental results on MNIST and CIFAR-10 show that our approach significantly reduces the number of filters of classical models such as LeNet and VGG while reaching the same or even better accuracy than the baseline models. Moreover, the trade-off between the sparsity and the accuracy is compared to other loss regularization terms based on the l1 or l2 norm as well as the SSL, NISP and GAL methods and shows that our approach is outperforming them.