 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeseg_3D_by_PC2D: Multi-View Projection for Domain Generalization and Adaptation in 3D Semantic Segmentation
May 21, 20253D semantic segmentation plays a pivotal role in autonomous driving and road infrastructure analysis, yet state-of-the-art 3D models are prone to severe domain shift when deployed across different datasets. We propose a novel multi-view projection framework that excels in both domain generalization (DG) and unsupervised domain adaptation (UDA). Our approach first aligns Lidar scans into coherent 3D scenes and renders them from multiple virtual camera poses to create a large-scale synthetic 2D dataset (PC2D). We then use it to train a 2D segmentation model in-domain. During inference, the model processes hundreds of views per scene; the resulting logits are back-projected to 3D with an occlusion-aware voting scheme to generate final point-wise labels. Our framework is modular and enables extensive exploration of key design parameters, such as view generation optimization (VGO), visualization modality optimization (MODO), and 2D model choice. We evaluate on the nuScenes and SemanticKITTI datasets under both the DG and UDA settings. We achieve state-of-the-art results in UDA and close to state-of-the-art in DG, with particularly large gains on large, static classes. Our code and dataset generation tools will be publicly available at https://github.com/andrewcaunes/ia4markings
3D Can Be Explored In 2D: Pseudo-Label Generation for LiDAR Point Clouds Using Sensor-Intensity-Based 2D Semantic Segmentation
May 06, 2025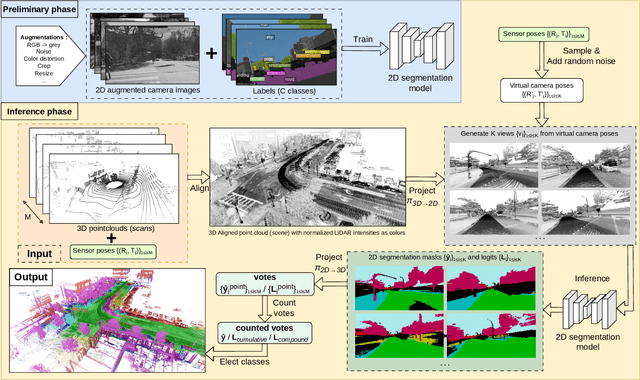



Semantic segmentation of 3D LiDAR point clouds, essential for autonomous driving and infrastructure management, is best achieved by supervised learning, which demands extensive annotated datasets and faces the problem of domain shifts. We introduce a new 3D semantic segmentation pipeline that leverages aligned scenes and state-of-the-art 2D segmentation methods, avoiding the need for direct 3D annotation or reliance on additional modalities such as camera images at inference time. Our approach generates 2D views from LiDAR scans colored by sensor intensity and applies 2D semantic segmentation to these views using a camera-domain pretrained model. The segmented 2D outputs are then back-projected onto the 3D points, with a simple voting-based estimator that merges the labels associated to each 3D point. Our main contribution is a global pipeline for 3D semantic segmentation requiring no prior 3D annotation and not other modality for inference, which can be used for pseudo-label generation. We conduct a thorough ablation study and demonstrate the potential of the generated pseudo-labels for the Unsupervised Domain Adaptation task.
Toward industrial use of continual learning : new metrics proposal for class incremental learning
Apr 10, 2024



In this paper, we investigate continual learning performance metrics used in class incremental learning strategies for continual learning (CL) using some high performing methods. We investigate especially mean task accuracy. First, we show that it lacks of expressiveness through some simple experiments to capture performance. We show that monitoring average tasks performance is over optimistic and can lead to misleading conclusions for future real life industrial uses. Then, we propose first a simple metric, Minimal Incremental Class Accuracy (MICA) which gives a fair and more useful evaluation of different continual learning methods. Moreover, in order to provide a simple way to easily compare different methods performance in continual learning, we derive another single scalar metric that take into account the learning performance variation as well as our newly introduced metric.
R-AGNO-RPN: A LIDAR-Camera Region Deep Network for Resolution-Agnostic Detection
Dec 10, 2020



Current neural networks-based object detection approaches processing LiDAR point clouds are generally trained from one kind of LiDAR sensors. However, their performances decrease when they are tested with data coming from a different LiDAR sensor than the one used for training, i.e., with a different point cloud resolution. In this paper, R-AGNO-RPN, a region proposal network built on fusion of 3D point clouds and RGB images is proposed for 3D object detection regardless of point cloud resolution. As our approach is designed to be also applied on low point cloud resolutions, the proposed method focuses on object localization instead of estimating refined boxes on reduced data. The resilience to low-resolution point cloud is obtained through image features accurately mapped to Bird's Eye View and a specific data augmentation procedure that improves the contribution of the RGB images. To show the proposed network's ability to deal with different point clouds resolutions, experiments are conducted on both data coming from the KITTI 3D Object Detection and the nuScenes datasets. In addition, to assess its performances, our method is compared to PointPillars, a well-known 3D detection network. Experimental results show that even on point cloud data reduced by $80\%$ of its original points, our method is still able to deliver relevant proposals localization.
Learning Sparse Filters in Deep Convolutional Neural Networks with a l1/l2 Pseudo-Norm
Jul 20, 2020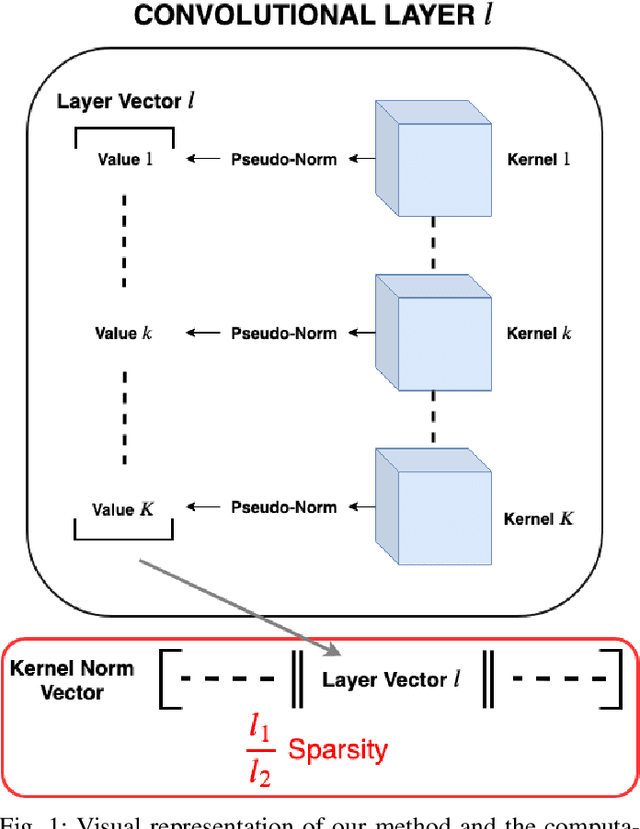


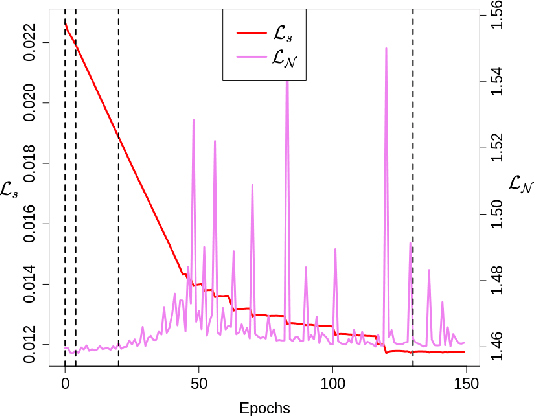
While deep neural networks (DNNs) have proven to be efficient for numerous tasks, they come at a high memory and computation cost, thus making them impractical on resource-limited devices. However, these networks are known to contain a large number of parameters. Recent research has shown that their structure can be more compact without compromising their performance. In this paper, we present a sparsity-inducing regularization term based on the ratio l1/l2 pseudo-norm defined on the filter coefficients. By defining this pseudo-norm appropriately for the different filter kernels, and removing irrelevant filters, the number of kernels in each layer can be drastically reduced leading to very compact Deep Convolutional Neural Networks (DCNN) structures. Unlike numerous existing methods, our approach does not require an iterative retraining process and, using this regularization term, directly produces a sparse model during the training process. Furthermore, our approach is also much easier and simpler to implement than existing methods. Experimental results on MNIST and CIFAR-10 show that our approach significantly reduces the number of filters of classical models such as LeNet and VGG while reaching the same or even better accuracy than the baseline models. Moreover, the trade-off between the sparsity and the accuracy is compared to other loss regularization terms based on the l1 or l2 norm as well as the SSL, NISP and GAL methods and shows that our approach is outperforming them.
Facial Landmark Correlation Analysis
Nov 24, 2019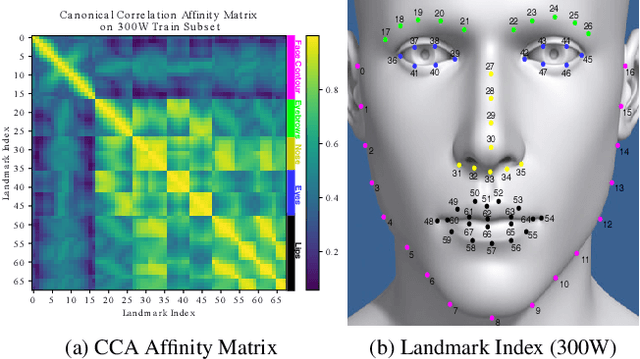



We present a facial landmark position correlation analysis as well as its applications. Although numerous facial landmark detection methods have been presented in the literature, few of them concern the intrinsic relationship among the landmarks. In order to reveal and interpret this relationship, we propose to analyze the facial landmark correlation by using Canonical Correlation Analysis (CCA). We experimentally show that dense facial landmark annotations in current benchmarks are strongly correlated, and we propose several applications based on this analysis. First, we give insights into the predictions from different facial landmark detection models (including cascaded random forests, cascaded Convolutional Neural Networks (CNNs), heatmap regression models) and interpret how CNNs progressively learn to predict facial landmarks. Second, we propose a few-shot learning method that allows to considerably reduce manual effort for dense landmark annotation. To this end, we select a portion of landmarks from the dense annotation format to form a sparse format, which is mostly correlated to the rest of them. Thanks to the strong correlation among the landmarks, the entire set of dense facial landmarks can then be inferred from the annotation in the sparse format by transfer learning. Unlike the previous methods, we mainly focus on how to find the most efficient sparse format to annotate. Overall, our correlation analysis provides new perspectives for the research on facial landmark detection.
2D Wasserstein Loss for Robust Facial Landmark Detection
Nov 24, 2019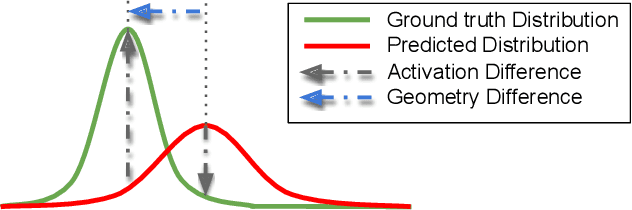
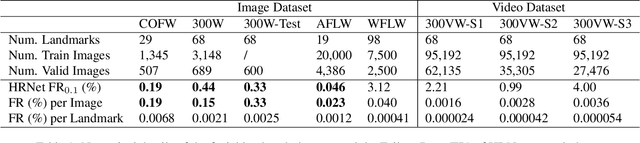

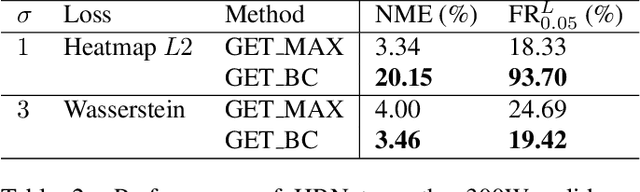
Facial landmark detection is an important preprocessing task for most applications related to face analysis. In recent years, the performance of facial landmark detection has been significantly improved by using deep Convolutional Neural Networks (CNNs), especially the Heatmap Regression Models (HRMs). Although their performance on common benchmark datasets have reached a high level, the robustness of these models still remains a challenging problem in the practical use under more noisy conditions of realistic environments. Contrary to most existing work focusing on the design of new models, we argue that improving the robustness requires rethinking many other aspects, including the use of datasets, the format of landmark annotation, the evaluation metric as well as the training and detection algorithm itself. In this paper, we propose a novel method for robust facial landmark detection using a loss function based on the 2D Wasserstein distance combined with a new landmark coordinate sampling relying on the barycenter of the individual propability distributions. The most intriguing fact of our method is that it can be plugged-and-play on most state-of-the-art HRMs with neither additional complexity nor structural modifications of the models. Further, with the large performance increase of state-of-the-art deep CNN models, we found that current evaluation metrics can no longer fully reflect the robustness of these models. Therefore, we propose several improvements on the standard evaluation protocol. Extensive experimental results on both traditional evaluation metrics and our evaluation metrics demonstrate that our approach significantly improves the robustness of state-of-the-art facial landmark detection models.
SMC Faster R-CNN: Toward a scene-specialized multi-object detector
Jun 30, 2017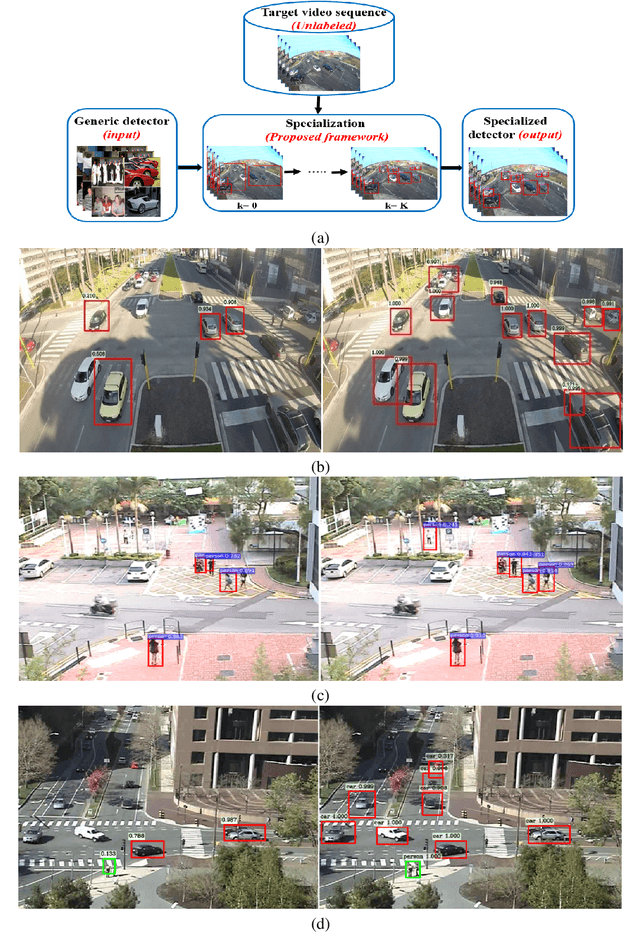

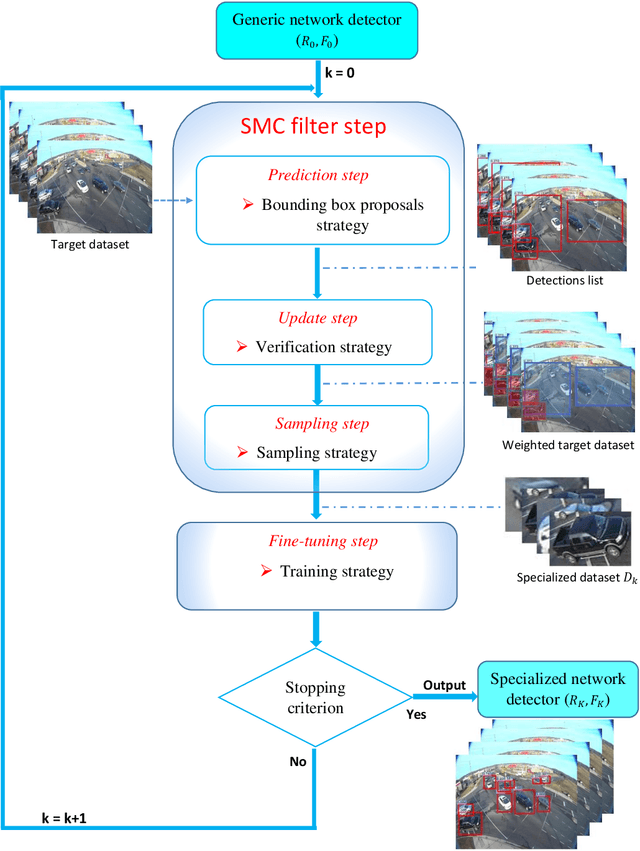
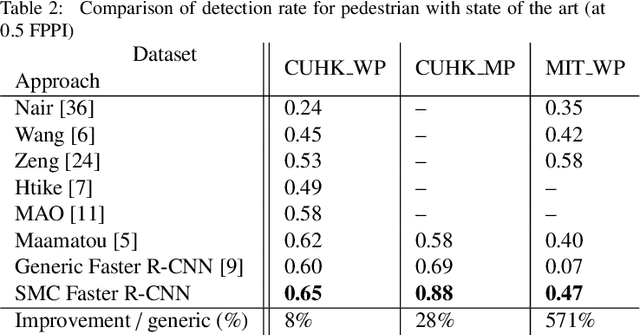
Generally, the performance of a generic detector decreases significantly when it is tested on a specific scene due to the large variation between the source training dataset and the samples from the target scene. To solve this problem, we propose a new formalism of transfer learning based on the theory of a Sequential Monte Carlo (SMC) filter to automatically specialize a scene-specific Faster R-CNN detector. The suggested framework uses different strategies based on the SMC filter steps to approximate iteratively the target distribution as a set of samples in order to specialize the Faster R-CNN detector towards a target scene. Moreover, we put forward a likelihood function that combines spatio-temporal information extracted from the target video sequence and the confidence-score given by the output layer of the Faster R-CNN, to favor the selection of target samples associated with the right label. The effectiveness of the suggested framework is demonstrated through experiments on several public traffic datasets. Compared with the state-of-the-art specialization frameworks, the proposed framework presents encouraging results for both single and multi-traffic object detections.
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
Mar 22, 2017



In this paper, we present a novel approach, called Deep MANTA (Deep Many-Tasks), for many-task vehicle analysis from a given image. A robust convolutional network is introduced for simultaneous vehicle detection, part localization, visibility characterization and 3D dimension estimation. Its architecture is based on a new coarse-to-fine object proposal that boosts the vehicle detection. Moreover, the Deep MANTA network is able to localize vehicle parts even if these parts are not visible. In the inference, the network's outputs are used by a real time robust pose estimation algorithm for fine orientation estimation and 3D vehicle localization. We show in experiments that our method outperforms monocular state-of-the-art approaches on vehicle detection, orientation and 3D location tasks on the very challenging KITTI benchmark.