 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Filters in Deep Convolutional Neural Networks with a l1/l2 Pseudo-Norm
Jul 20, 2020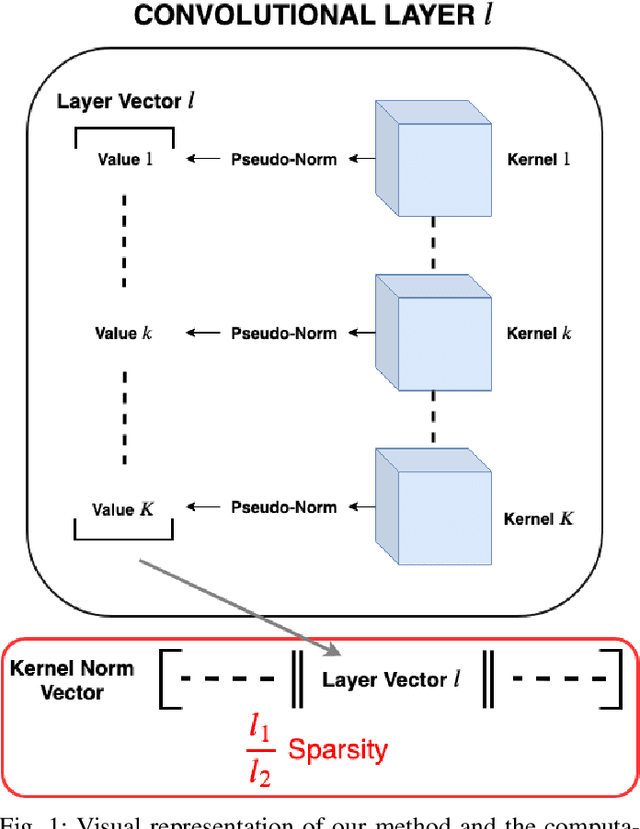


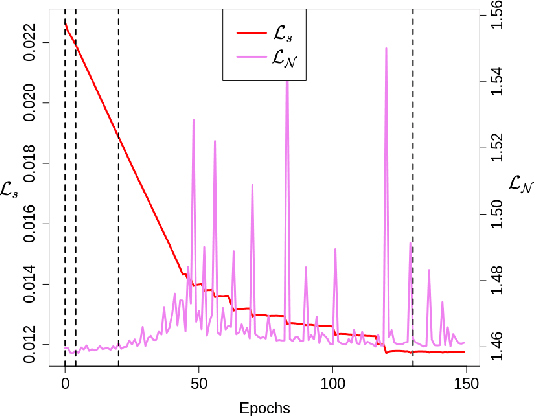
While deep neural networks (DNNs) have proven to be efficient for numerous tasks, they come at a high memory and computation cost, thus making them impractical on resource-limited devices. However, these networks are known to contain a large number of parameters. Recent research has shown that their structure can be more compact without compromising their performance. In this paper, we present a sparsity-inducing regularization term based on the ratio l1/l2 pseudo-norm defined on the filter coefficients. By defining this pseudo-norm appropriately for the different filter kernels, and removing irrelevant filters, the number of kernels in each layer can be drastically reduced leading to very compact Deep Convolutional Neural Networks (DCNN) structures. Unlike numerous existing methods, our approach does not require an iterative retraining process and, using this regularization term, directly produces a sparse model during the training process. Furthermore, our approach is also much easier and simpler to implement than existing methods. Experimental results on MNIST and CIFAR-10 show that our approach significantly reduces the number of filters of classical models such as LeNet and VGG while reaching the same or even better accuracy than the baseline models. Moreover, the trade-off between the sparsity and the accuracy is compared to other loss regularization terms based on the l1 or l2 norm as well as the SSL, NISP and GAL methods and shows that our approach is outperforming them.
Facial Landmark Correlation Analysis
Nov 24, 2019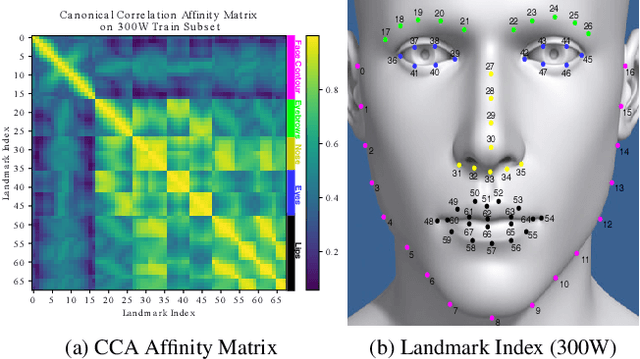



We present a facial landmark position correlation analysis as well as its applications. Although numerous facial landmark detection methods have been presented in the literature, few of them concern the intrinsic relationship among the landmarks. In order to reveal and interpret this relationship, we propose to analyze the facial landmark correlation by using Canonical Correlation Analysis (CCA). We experimentally show that dense facial landmark annotations in current benchmarks are strongly correlated, and we propose several applications based on this analysis. First, we give insights into the predictions from different facial landmark detection models (including cascaded random forests, cascaded Convolutional Neural Networks (CNNs), heatmap regression models) and interpret how CNNs progressively learn to predict facial landmarks. Second, we propose a few-shot learning method that allows to considerably reduce manual effort for dense landmark annotation. To this end, we select a portion of landmarks from the dense annotation format to form a sparse format, which is mostly correlated to the rest of them. Thanks to the strong correlation among the landmarks, the entire set of dense facial landmarks can then be inferred from the annotation in the sparse format by transfer learning. Unlike the previous methods, we mainly focus on how to find the most efficient sparse format to annotate. Overall, our correlation analysis provides new perspectives for the research on facial landmark detection.
2D Wasserstein Loss for Robust Facial Landmark Detection
Nov 24, 2019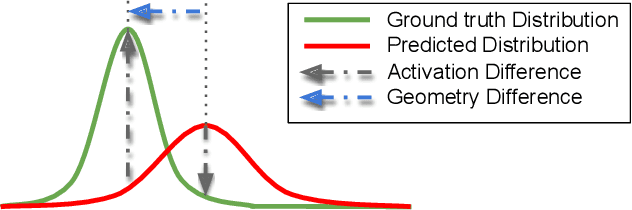
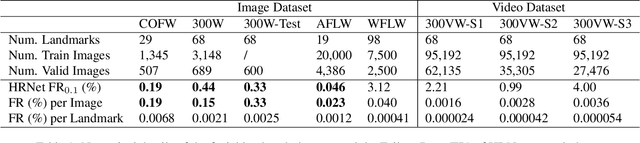

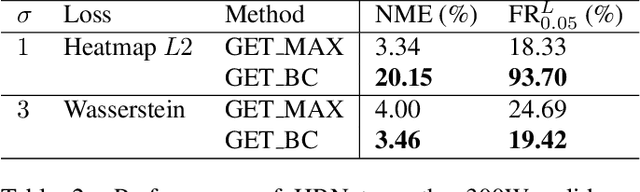
Facial landmark detection is an important preprocessing task for most applications related to face analysis. In recent years, the performance of facial landmark detection has been significantly improved by using deep Convolutional Neural Networks (CNNs), especially the Heatmap Regression Models (HRMs). Although their performance on common benchmark datasets have reached a high level, the robustness of these models still remains a challenging problem in the practical use under more noisy conditions of realistic environments. Contrary to most existing work focusing on the design of new models, we argue that improving the robustness requires rethinking many other aspects, including the use of datasets, the format of landmark annotation, the evaluation metric as well as the training and detection algorithm itself. In this paper, we propose a novel method for robust facial landmark detection using a loss function based on the 2D Wasserstein distance combined with a new landmark coordinate sampling relying on the barycenter of the individual propability distributions. The most intriguing fact of our method is that it can be plugged-and-play on most state-of-the-art HRMs with neither additional complexity nor structural modifications of the models. Further, with the large performance increase of state-of-the-art deep CNN models, we found that current evaluation metrics can no longer fully reflect the robustness of these models. Therefore, we propose several improvements on the standard evaluation protocol. Extensive experimental results on both traditional evaluation metrics and our evaluation metrics demonstrate that our approach significantly improves the robustness of state-of-the-art facial landmark detection models.