 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Whole in the Parts in Self-Supervised Representation Learning
Jan 06, 2025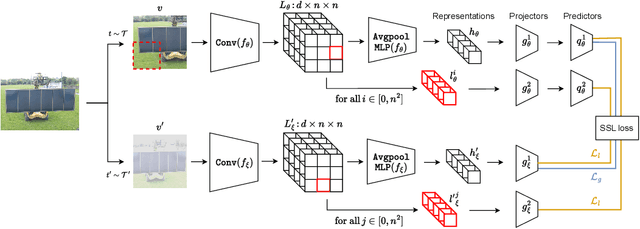
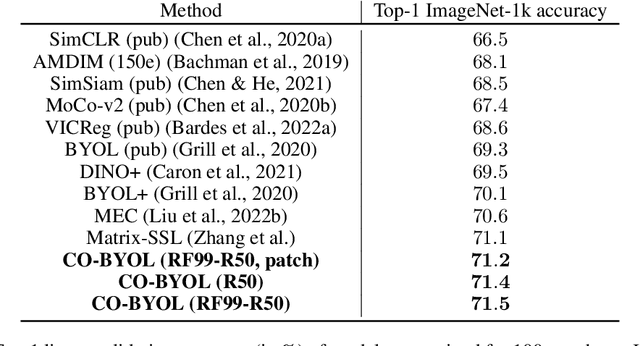
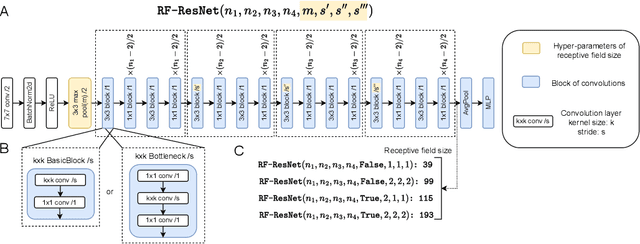

Recent successes in self-supervised learning (SSL) model spatial co-occurrences of visual features either by masking portions of an image or by aggressively cropping it. Here, we propose a new way to model spatial co-occurrences by aligning local representations (before pooling) with a global image representation. We present CO-SSL, a family of instance discrimination methods and show that it outperforms previous methods on several datasets, including ImageNet-1K where it achieves 71.5% of Top-1 accuracy with 100 pre-training epochs. CO-SSL is also more robust to noise corruption, internal corruption, small adversarial attacks, and large training crop sizes. Our analysis further indicates that CO-SSL learns highly redundant local representations, which offers an explanation for its robustness. Overall, our work suggests that aligning local and global representations may be a powerful principle of unsupervised category learning.
Self-supervised visual learning from interactions with objects
Jul 09, 2024



Self-supervised learning (SSL) has revolutionized visual representation learning, but has not achieved the robustness of human vision. A reason for this could be that SSL does not leverage all the data available to humans during learning. When learning about an object, humans often purposefully turn or move around objects and research suggests that these interactions can substantially enhance their learning. Here we explore whether such object-related actions can boost SSL. For this, we extract the actions performed to change from one ego-centric view of an object to another in four video datasets. We then introduce a new loss function to learn visual and action embeddings by aligning the performed action with the representations of two images extracted from the same clip. This permits the performed actions to structure the latent visual representation. Our experiments show that our method consistently outperforms previous methods on downstream category recognition. In our analysis, we find that the observed improvement is associated with a better viewpoint-wise alignment of different objects from the same category. Overall, our work demonstrates that embodied interactions with objects can improve SSL of object categories.
Blur aware metric depth estimation with multi-focus plenoptic cameras
Aug 08, 2023While a traditional camera only captures one point of view of a scene, a plenoptic or light-field camera, is able to capture spatial and angular information in a single snapshot, enabling depth estimation from a single acquisition. In this paper, we present a new metric depth estimation algorithm using only raw images from a multi-focus plenoptic camera. The proposed approach is especially suited for the multi-focus configuration where several micro-lenses with different focal lengths are used. The main goal of our blur aware depth estimation (BLADE) approach is to improve disparity estimation for defocus stereo images by integrating both correspondence and defocus cues. We thus leverage blur information where it was previously considered a drawback. We explicitly derive an inverse projection model including the defocus blur providing depth estimates up to a scale factor. A method to calibrate the inverse model is then proposed. We thus take into account depth scaling to achieve precise and accurate metric depth estimates. Our results show that introducing defocus cues improves the depth estimation. We demonstrate the effectiveness of our framework and depth scaling calibration on relative depth estimation setups and on real-world 3D complex scenes with ground truth acquired with a 3D lidar scanner.
Time to augment contrastive learning
Jul 27, 2022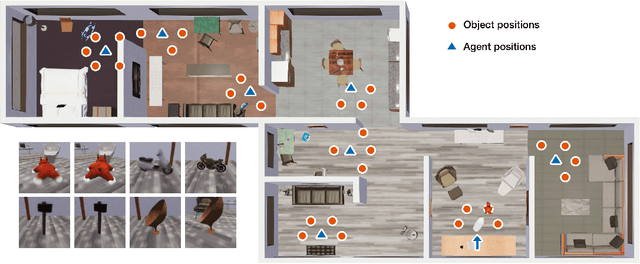
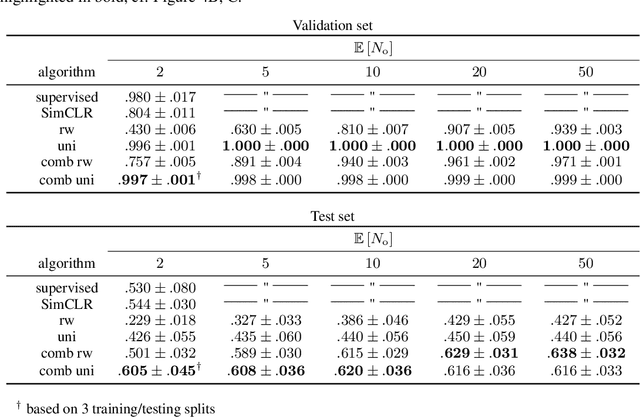

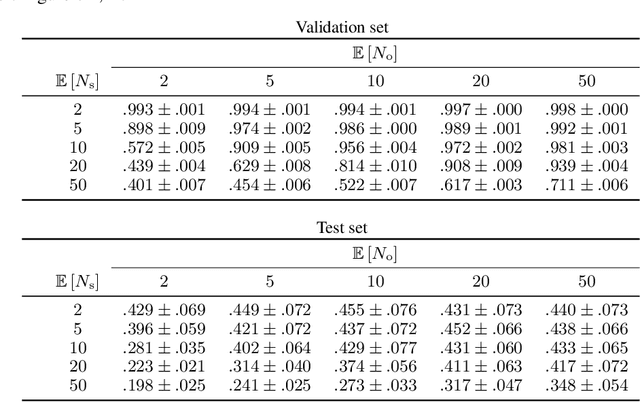
Biological vision systems are unparalleled in their ability to learn visual representations without supervision. In machine learning, contrastive learning (CL) has led to major advances in forming object representations in an unsupervised fashion. These systems learn representations invariant to augmentation operations over images, like cropping or flipping. In contrast, biological vision systems exploit the temporal structure of the visual experience. This gives access to augmentations not commonly used in CL, like watching the same object from multiple viewpoints or against different backgrounds. Here, we systematically investigate and compare the potential benefits of such time-based augmentations for learning object categories. Our results show that time-based augmentations achieve large performance gains over state-of-the-art image augmentations. Specifically, our analyses reveal that: 1) 3-D object rotations drastically improve the learning of object categories; 2) viewing objects against changing backgrounds is vital for learning to discard background-related information. Overall, we conclude that time-based augmentations can greatly improve contrastive learning, narrowing the gap between artificial and biological vision systems.
Embodied vision for learning object representations
May 12, 2022



Recent time-contrastive learning approaches manage to learn invariant object representations without supervision. This is achieved by mapping successive views of an object onto close-by internal representations. When considering this learning approach as a model of the development of human object recognition, it is important to consider what visual input a toddler would typically observe while interacting with objects. First, human vision is highly foveated, with high resolution only available in the central region of the field of view. Second, objects may be seen against a blurry background due to infants' limited depth of field. Third, during object manipulation a toddler mostly observes close objects filling a large part of the field of view due to their rather short arms. Here, we study how these effects impact the quality of visual representations learnt through time-contrastive learning. To this end, we let a visually embodied agent "play" with objects in different locations of a near photo-realistic flat. During each play session the agent views an object in multiple orientations before turning its body to view another object. The resulting sequence of views feeds a time-contrastive learning algorithm. Our results show that visual statistics mimicking those of a toddler improve object recognition accuracy in both familiar and novel environments. We argue that this effect is caused by the reduction of features extracted in the background, a neural network bias for large features in the image and a greater similarity between novel and familiar background regions. We conclude that the embodied nature of visual learning may be crucial for understanding the development of human object perception.
Leveraging blur information for plenoptic camera calibration
Nov 09, 2021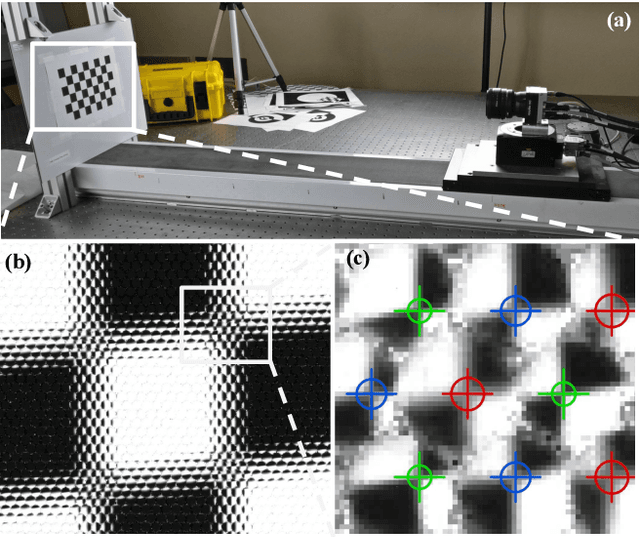
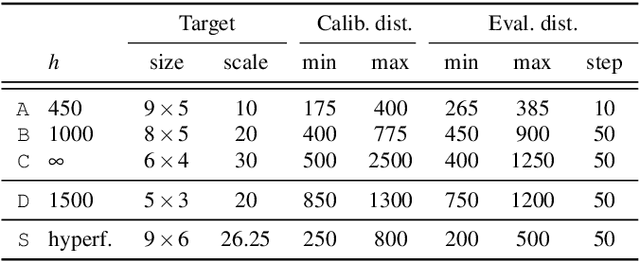
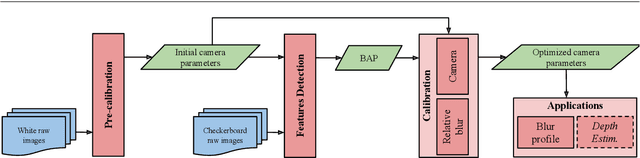
This paper presents a novel calibration algorithm for plenoptic cameras, especially the multi-focus configuration, where several types of micro-lenses are used, using raw images only. Current calibration methods rely on simplified projection models, use features from reconstructed images, or require separated calibrations for each type of micro-lens. In the multi-focus configuration, the same part of a scene will demonstrate different amounts of blur according to the micro-lens focal length. Usually, only micro-images with the smallest amount of blur are used. In order to exploit all available data, we propose to explicitly model the defocus blur in a new camera model with the help of our newly introduced Blur Aware Plenoptic (BAP) feature. First, it is used in a pre-calibration step that retrieves initial camera parameters, and second, to express a new cost function to be minimized in our single optimization process. Third, it is exploited to calibrate the relative blur between micro-images. It links the geometric blur, i.e., the blur circle, to the physical blur, i.e., the point spread function. Finally, we use the resulting blur profile to characterize the camera's depth of field. Quantitative evaluations in controlled environment on real-world data demonstrate the effectiveness of our calibrations.
Blur Aware Calibration of Multi-Focus Plenoptic Camera
Apr 16, 2020
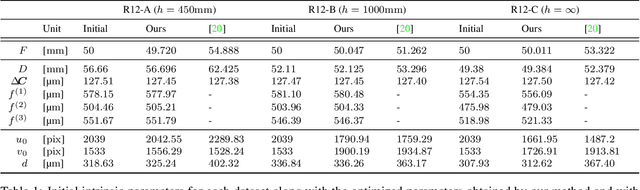
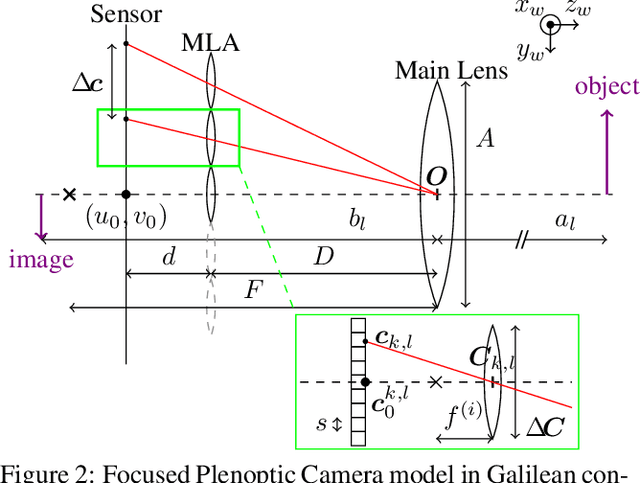
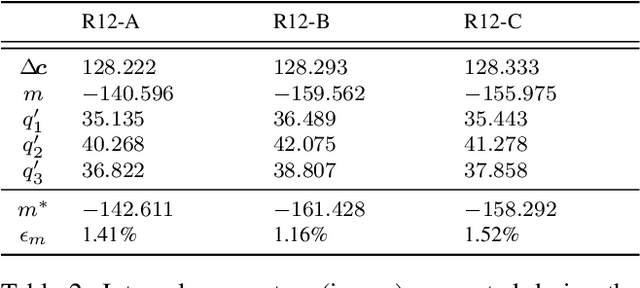
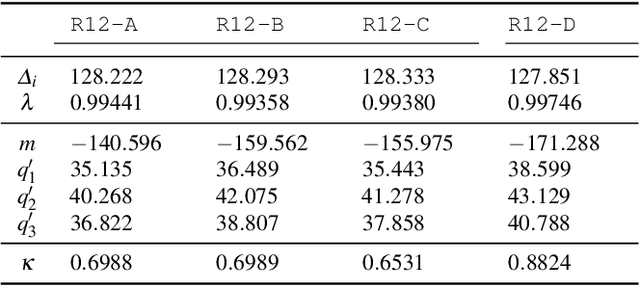
This paper presents a novel calibration algorithm for Multi-Focus Plenoptic Cameras (MFPCs) using raw images only. The design of such cameras is usually complex and relies on precise placement of optic elements. Several calibration procedures have been proposed to retrieve the camera parameters but relying on simplified models, reconstructed images to extract features, or multiple calibrations when several types of micro-lens are used. Considering blur information, we propose a new Blur Aware Plenoptic (BAP) feature. It is first exploited in a pre-calibration step that retrieves initial camera parameters, and secondly to express a new cost function for our single optimization process. The effectiveness of our calibration method is validated by quantitative and qualitative experiments.
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
Mar 22, 2017



In this paper, we present a novel approach, called Deep MANTA (Deep Many-Tasks), for many-task vehicle analysis from a given image. A robust convolutional network is introduced for simultaneous vehicle detection, part localization, visibility characterization and 3D dimension estimation. Its architecture is based on a new coarse-to-fine object proposal that boosts the vehicle detection. Moreover, the Deep MANTA network is able to localize vehicle parts even if these parts are not visible. In the inference, the network's outputs are used by a real time robust pose estimation algorithm for fine orientation estimation and 3D vehicle localization. We show in experiments that our method outperforms monocular state-of-the-art approaches on vehicle detection, orientation and 3D location tasks on the very challenging KITTI benchmark.