 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Can Be Explored In 2D: Pseudo-Label Generation for LiDAR Point Clouds Using Sensor-Intensity-Based 2D Semantic Segmentation
May 06, 2025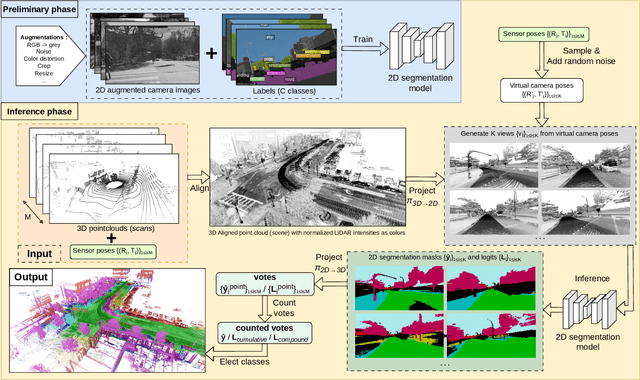



Semantic segmentation of 3D LiDAR point clouds, essential for autonomous driving and infrastructure management, is best achieved by supervised learning, which demands extensive annotated datasets and faces the problem of domain shifts. We introduce a new 3D semantic segmentation pipeline that leverages aligned scenes and state-of-the-art 2D segmentation methods, avoiding the need for direct 3D annotation or reliance on additional modalities such as camera images at inference time. Our approach generates 2D views from LiDAR scans colored by sensor intensity and applies 2D semantic segmentation to these views using a camera-domain pretrained model. The segmented 2D outputs are then back-projected onto the 3D points, with a simple voting-based estimator that merges the labels associated to each 3D point. Our main contribution is a global pipeline for 3D semantic segmentation requiring no prior 3D annotation and not other modality for inference, which can be used for pseudo-label generation. We conduct a thorough ablation study and demonstrate the potential of the generated pseudo-labels for the Unsupervised Domain Adaptation task.
Active Collaborative Visual SLAM exploiting ORB Features
Jul 07, 2024In autonomous robotics, a significant challenge involves devising robust solutions for Active Collaborative SLAM (AC-SLAM). This process requires multiple robots to cooperatively explore and map an unknown environment by intelligently coordinating their movements and sensor data acquisition. In this article, we present an efficient visual AC-SLAM method using aerial and ground robots for environment exploration and mapping. We propose an efficient frontiers filtering method that takes into account the common IoU map frontiers and reduces the frontiers for each robot. Additionally, we also present an approach to guide robots to previously visited goal positions to promote loop closure to reduce SLAM uncertainty. The proposed method is implemented in ROS and evaluated through simulations on publicly available datasets and similar methods, achieving an accumulative average of 59% of increase in area coverage.
Label-Efficient 3D Object Detection For Road-Side Units
Apr 09, 2024



Occlusion presents a significant challenge for safety-critical applications such as autonomous driving. Collaborative perception has recently attracted a large research interest thanks to the ability to enhance the perception of autonomous vehicles via deep information fusion with intelligent roadside units (RSU), thus minimizing the impact of occlusion. While significant advancement has been made, the data-hungry nature of these methods creates a major hurdle for their real-world deployment, particularly due to the need for annotated RSU data. Manually annotating the vast amount of RSU data required for training is prohibitively expensive, given the sheer number of intersections and the effort involved in annotating point clouds. We address this challenge by devising a label-efficient object detection method for RSU based on unsupervised object discovery. Our paper introduces two new modules: one for object discovery based on a spatial-temporal aggregation of point clouds, and another for refinement. Furthermore, we demonstrate that fine-tuning on a small portion of annotated data allows our object discovery models to narrow the performance gap with, or even surpass, fully supervised models. Extensive experiments are carried out in simulated and real-world datasets to evaluate our method.
Entropy Based Multi-robot Active SLAM
Oct 09, 2023
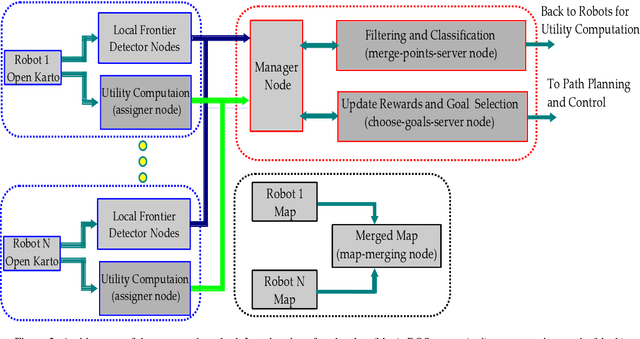
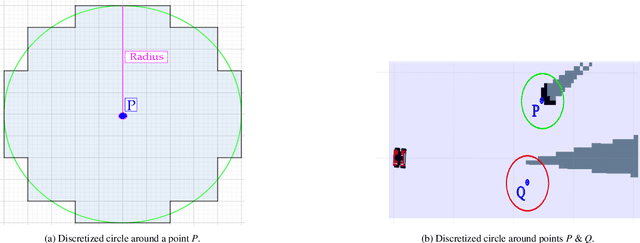
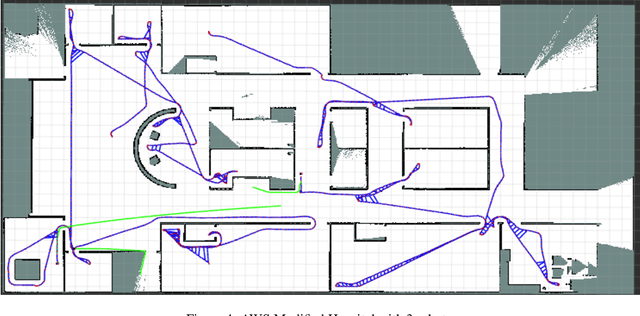
In this article, we present an efficient multi-robot active SLAM framework that involves a frontier-sharing method for maximum exploration of an unknown environment. It encourages the robots to spread into the environment while weighting the goal frontiers with the pose graph SLAM uncertainly and path entropy. Our approach works on a limited number of frontier points and weights the goal frontiers with a utility function that encapsulates both the SLAM and map uncertainties, thus providing an efficient and not computationally expensive solution. Our approach has been tested on publicly available simulation environments and on real robots. An accumulative 31% more coverage than similar state-of-the-art approaches has been obtained, proving the capability of our approach for efficient environment exploration.
Active SLAM Utility Function Exploiting Path Entropy
Sep 28, 2023
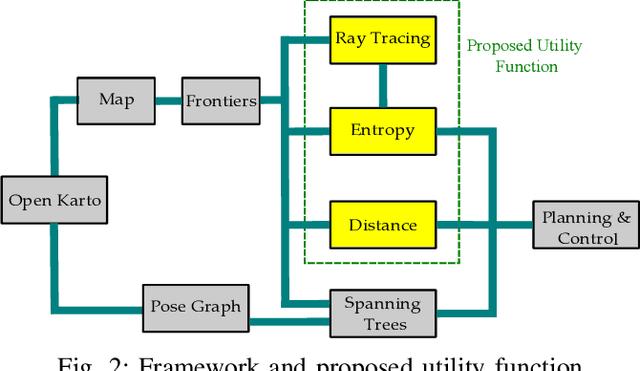

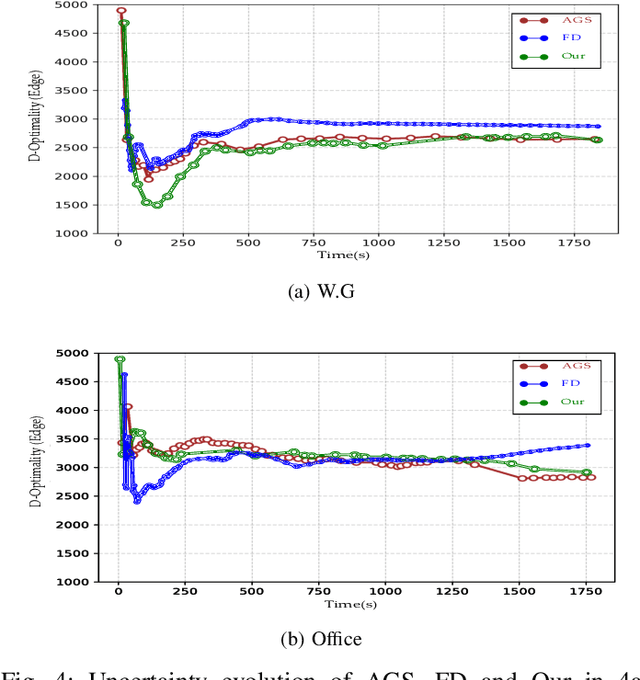
In this article we present a utility function for Active SLAM (A-SLAM) which utilizes map entropy along with D-Optimality criterion metrices for weighting goal frontier candidates. We propose a utility function for frontier goal selection that exploits the occupancy grid map by utilizing the path entropy and favors unknown map locations for maximum area coverage while maintaining a low localization and mapping uncertainties. We quantify the efficiency of our method using various graph connectivity matrices and map efficiency indexes for an environment exploration task. Using simulation and experimental results against similar approaches we achieve an average of 32\% more coverage using publicly available data sets.
Practical Collaborative Perception: A Framework for Asynchronous and Multi-Agent 3D Object Detection
Jul 09, 2023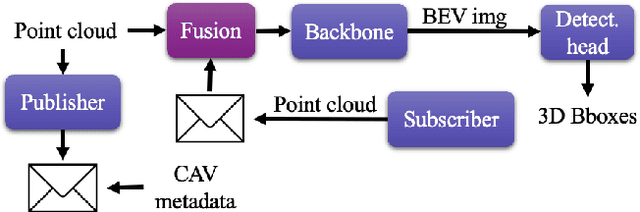
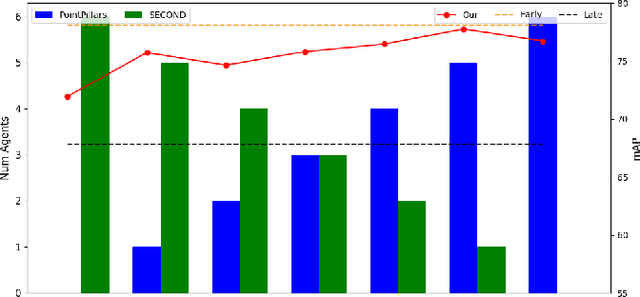
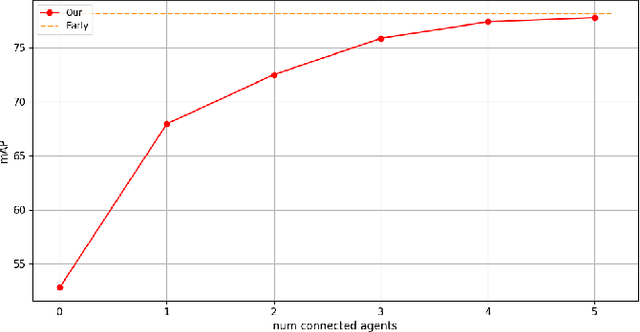
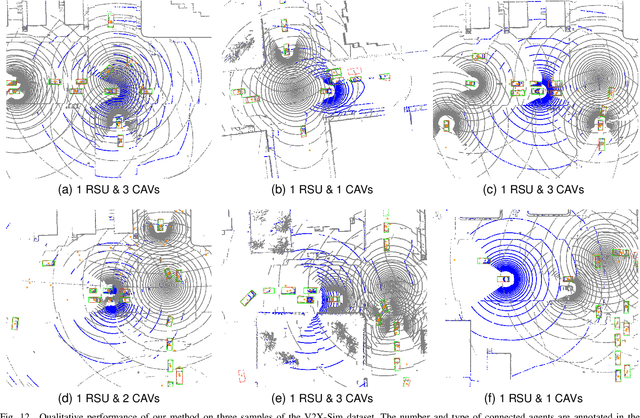
Occlusion is a major challenge for LiDAR-based object detection methods. This challenge becomes safety-critical in urban traffic where the ego vehicle must have reliable object detection to avoid collision while its field of view is severely reduced due to the obstruction posed by a large number of road users. Collaborative perception via Vehicle-to-Everything (V2X) communication, which leverages the diverse perspective thanks to the presence at multiple locations of connected agents to form a complete scene representation, is an appealing solution. State-of-the-art V2X methods resolve the performance-bandwidth tradeoff using a mid-collaboration approach where the Bird-Eye View images of point clouds are exchanged so that the bandwidth consumption is lower than communicating point clouds as in early collaboration, and the detection performance is higher than late collaboration, which fuses agents' output, thanks to a deeper interaction among connected agents. While achieving strong performance, the real-world deployment of most mid-collaboration approaches is hindered by their overly complicated architectures, involving learnable collaboration graphs and autoencoder-based compressor/ decompressor, and unrealistic assumptions about inter-agent synchronization. In this work, we devise a simple yet effective collaboration method that achieves a better bandwidth-performance tradeoff than prior state-of-the-art methods while minimizing changes made to the single-vehicle detection models and relaxing unrealistic assumptions on inter-agent synchronization. Experiments on the V2X-Sim dataset show that our collaboration method achieves 98\% of the performance of an early-collaboration method, while only consuming the equivalent bandwidth of a late-collaboration method.
Aligning Bird-Eye View Representation of Point Cloud Sequences using Scene Flow
May 04, 2023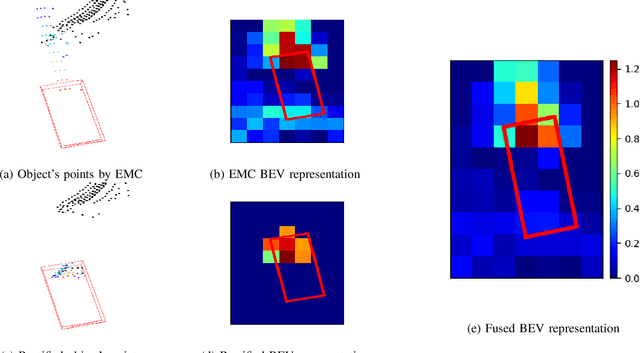
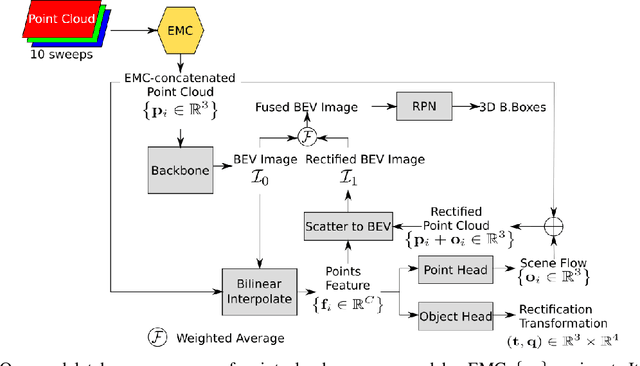
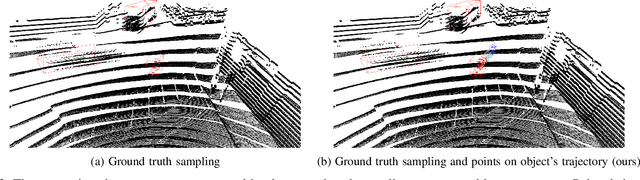
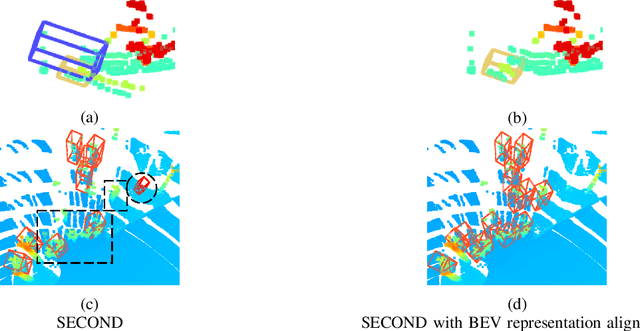
Low-resolution point clouds are challenging for object detection methods due to their sparsity. Densifying the present point cloud by concatenating it with its predecessors is a popular solution to this challenge. Such concatenation is possible thanks to the removal of ego vehicle motion using its odometry. This method is called Ego Motion Compensation (EMC). Thanks to the added points, EMC significantly improves the performance of single-frame detectors. However, it suffers from the shadow effect that manifests in dynamic objects' points scattering along their trajectories. This effect results in a misalignment between feature maps and objects' locations, thus limiting performance improvement to stationary and slow-moving objects only. Scene flow allows aligning point clouds in 3D space, thus naturally resolving the misalignment in feature spaces. By observing that scene flow computation shares several components with 3D object detection pipelines, we develop a plug-in module that enables single-frame detectors to compute scene flow to rectify their Bird-Eye View representation. Experiments on the NuScenes dataset show that our module leads to a significant increase (up to 16%) in the Average Precision of large vehicles, which interestingly demonstrates the most severe shadow effect. The code is published at https://github.com/quan-dao/pc-corrector.
Attention-based Proposals Refinement for 3D Object Detection
Jan 26, 2022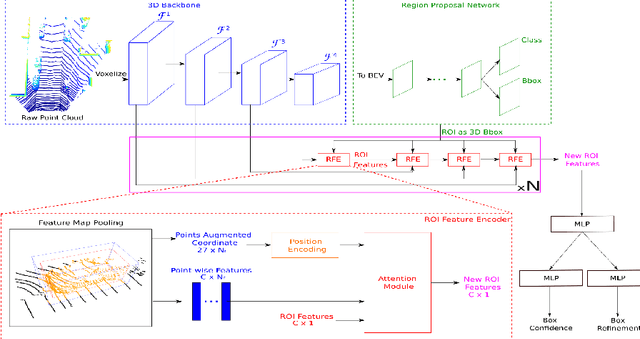
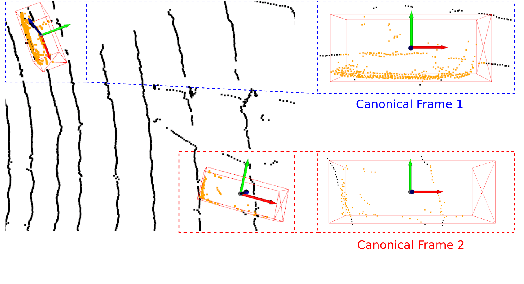

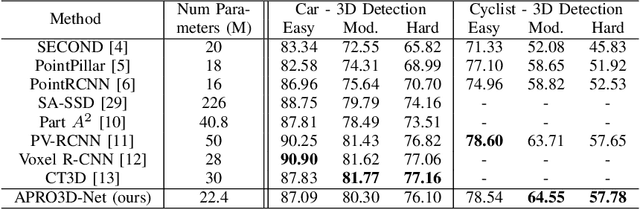
Recent advances in 3D object detection is made by developing the refinement stage for voxel-based Region Proposal Networks (RPN) to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Regions of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to form ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper proposes a data-driven approach to ROI feature computing named APRO3D-Net which consists of a voxel-based RPN and a refinement stage made of Vector Attention. Unlike the original multi-head attention, Vector Attention assigns different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code is released in https://github.com/quan-dao/APRO3D-Net.
A two-stage data association approach for 3D Multi-object Tracking
Jan 21, 2021
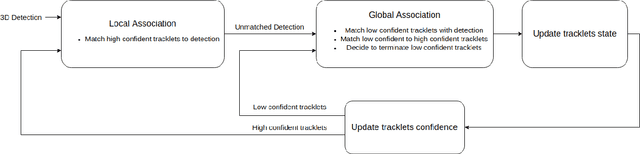
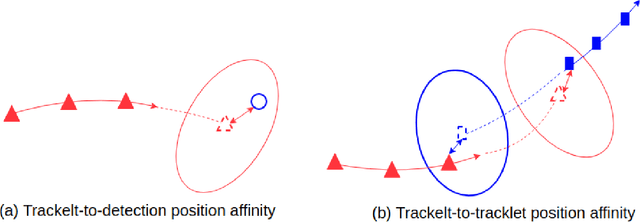

Multi-object tracking (MOT) is an integral part of any autonomous driving pipelines because itproduces trajectories which has been taken by other moving objects in the scene and helps predicttheir future motion. Thanks to the recent advances in 3D object detection enabled by deep learning,track-by-detection has become the dominant paradigm in 3D MOT. In this paradigm, a MOT systemis essentially made of an object detector and a data association algorithm which establishes track-to-detection correspondence. While 3D object detection has been actively researched, associationalgorithms for 3D MOT seem to settle at a bipartie matching formulated as a linear assignmentproblem (LAP) and solved by the Hungarian algorithm. In this paper, we adapt a two-stage dataassociation method which was successful in image-based tracking to the 3D setting, thus providingan alternative for data association for 3D MOT. Our method outperforms the baseline using one-stagebipartie matching for data association by achieving 0.587 AMOTA in NuScenes validation set.
R-AGNO-RPN: A LIDAR-Camera Region Deep Network for Resolution-Agnostic Detection
Dec 10, 2020



Current neural networks-based object detection approaches processing LiDAR point clouds are generally trained from one kind of LiDAR sensors. However, their performances decrease when they are tested with data coming from a different LiDAR sensor than the one used for training, i.e., with a different point cloud resolution. In this paper, R-AGNO-RPN, a region proposal network built on fusion of 3D point clouds and RGB images is proposed for 3D object detection regardless of point cloud resolution. As our approach is designed to be also applied on low point cloud resolutions, the proposed method focuses on object localization instead of estimating refined boxes on reduced data. The resilience to low-resolution point cloud is obtained through image features accurately mapped to Bird's Eye View and a specific data augmentation procedure that improves the contribution of the RGB images. To show the proposed network's ability to deal with different point clouds resolutions, experiments are conducted on both data coming from the KITTI 3D Object Detection and the nuScenes datasets. In addition, to assess its performances, our method is compared to PointPillars, a well-known 3D detection network. Experimental results show that even on point cloud data reduced by $80\%$ of its original points, our method is still able to deliver relevant proposals localization.