 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Collaborative Perception: A Framework for Asynchronous and Multi-Agent 3D Object Detection
Jul 09, 2023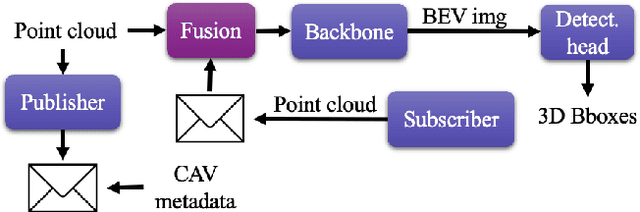
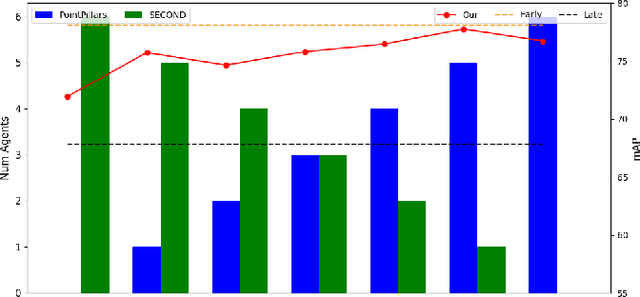
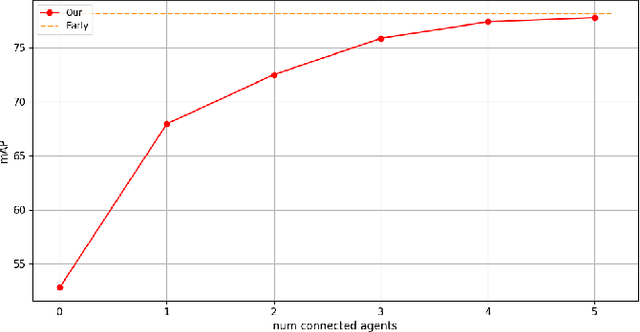
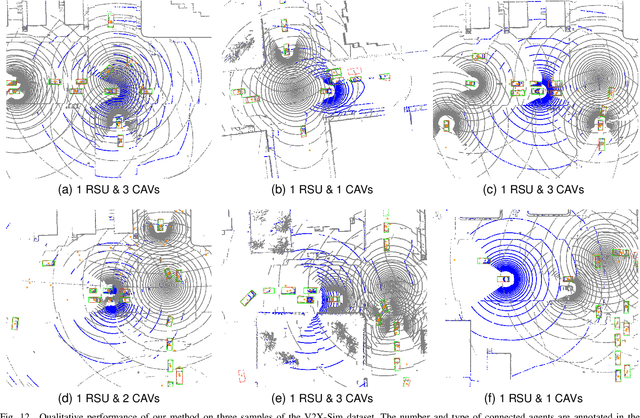
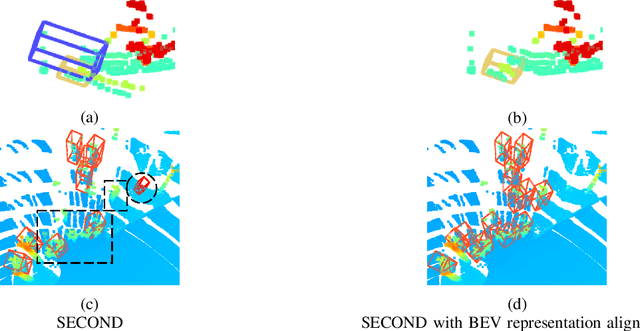
Occlusion is a major challenge for LiDAR-based object detection methods. This challenge becomes safety-critical in urban traffic where the ego vehicle must have reliable object detection to avoid collision while its field of view is severely reduced due to the obstruction posed by a large number of road users. Collaborative perception via Vehicle-to-Everything (V2X) communication, which leverages the diverse perspective thanks to the presence at multiple locations of connected agents to form a complete scene representation, is an appealing solution. State-of-the-art V2X methods resolve the performance-bandwidth tradeoff using a mid-collaboration approach where the Bird-Eye View images of point clouds are exchanged so that the bandwidth consumption is lower than communicating point clouds as in early collaboration, and the detection performance is higher than late collaboration, which fuses agents' output, thanks to a deeper interaction among connected agents. While achieving strong performance, the real-world deployment of most mid-collaboration approaches is hindered by their overly complicated architectures, involving learnable collaboration graphs and autoencoder-based compressor/ decompressor, and unrealistic assumptions about inter-agent synchronization. In this work, we devise a simple yet effective collaboration method that achieves a better bandwidth-performance tradeoff than prior state-of-the-art methods while minimizing changes made to the single-vehicle detection models and relaxing unrealistic assumptions on inter-agent synchronization. Experiments on the V2X-Sim dataset show that our collaboration method achieves 98\% of the performance of an early-collaboration method, while only consuming the equivalent bandwidth of a late-collaboration method.
Aligning Bird-Eye View Representation of Point Cloud Sequences using Scene Flow
May 04, 2023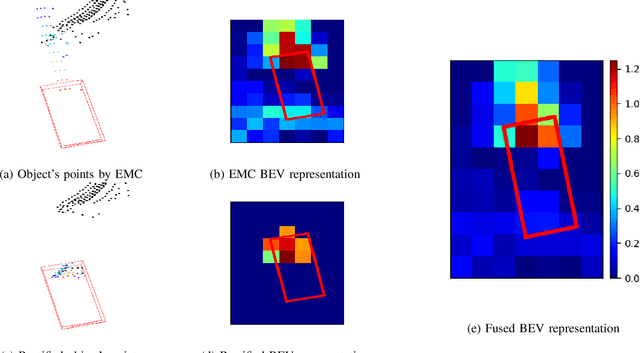
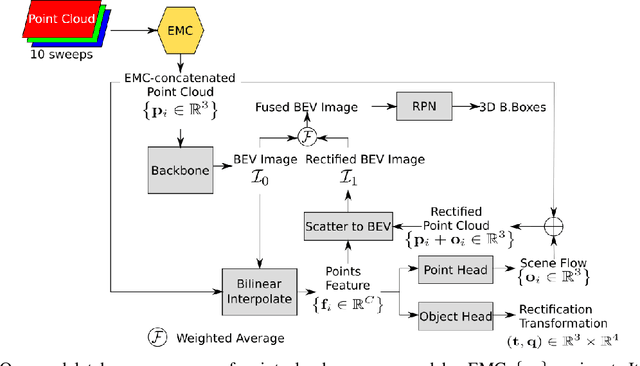
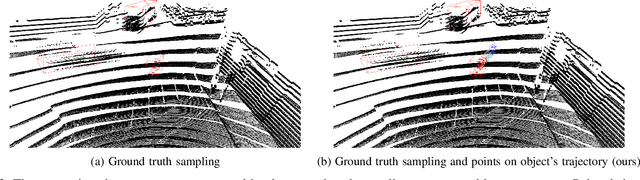
Low-resolution point clouds are challenging for object detection methods due to their sparsity. Densifying the present point cloud by concatenating it with its predecessors is a popular solution to this challenge. Such concatenation is possible thanks to the removal of ego vehicle motion using its odometry. This method is called Ego Motion Compensation (EMC). Thanks to the added points, EMC significantly improves the performance of single-frame detectors. However, it suffers from the shadow effect that manifests in dynamic objects' points scattering along their trajectories. This effect results in a misalignment between feature maps and objects' locations, thus limiting performance improvement to stationary and slow-moving objects only. Scene flow allows aligning point clouds in 3D space, thus naturally resolving the misalignment in feature spaces. By observing that scene flow computation shares several components with 3D object detection pipelines, we develop a plug-in module that enables single-frame detectors to compute scene flow to rectify their Bird-Eye View representation. Experiments on the NuScenes dataset show that our module leads to a significant increase (up to 16%) in the Average Precision of large vehicles, which interestingly demonstrates the most severe shadow effect. The code is published at https://github.com/quan-dao/pc-corrector.
Attention-based Proposals Refinement for 3D Object Detection
Jan 26, 2022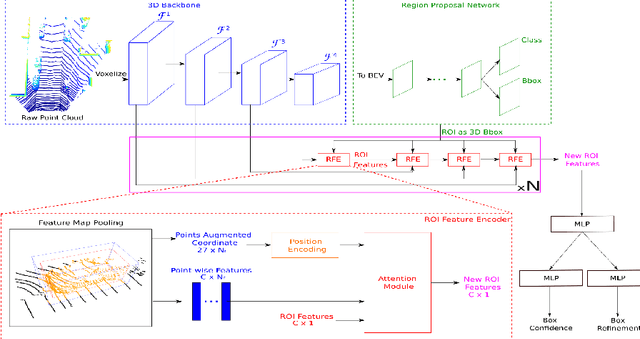

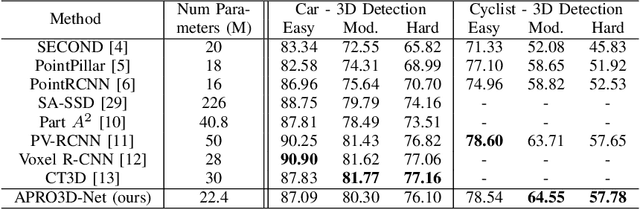
Recent advances in 3D object detection is made by developing the refinement stage for voxel-based Region Proposal Networks (RPN) to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Regions of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to form ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper proposes a data-driven approach to ROI feature computing named APRO3D-Net which consists of a voxel-based RPN and a refinement stage made of Vector Attention. Unlike the original multi-head attention, Vector Attention assigns different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code is released in https://github.com/quan-dao/APRO3D-Net.