 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Methods for Sign Language Recognition: A Modality-Based Review
Sep 22, 2020



Sign language visual recognition from continuous multi-modal streams is still one of the most challenging fields. Recent advances in human actions recognition are exploiting the ascension of GPU-based learning from massive data, and are getting closer to human-like performances. They are then prone to creating interactive services for the deaf and hearing-impaired communities. A population that is expected to grow considerably in the years to come. This paper aims at reviewing the human actions recognition literature with the sign-language visual understanding as a scope. The methods analyzed will be mainly organized according to the different types of unimodal inputs exploited, their relative multi-modal combinations and pipeline steps. In each section, we will detail and compare the related datasets, approaches then distinguish the still open contribution paths suitable for the creation of sign language related services. Special attention will be paid to the approaches and commercial solutions handling facial expressions and continuous signing.
Multimodal Biometric Authentication Using Choquet Integral and Genetic Algorithm
Mar 27, 2018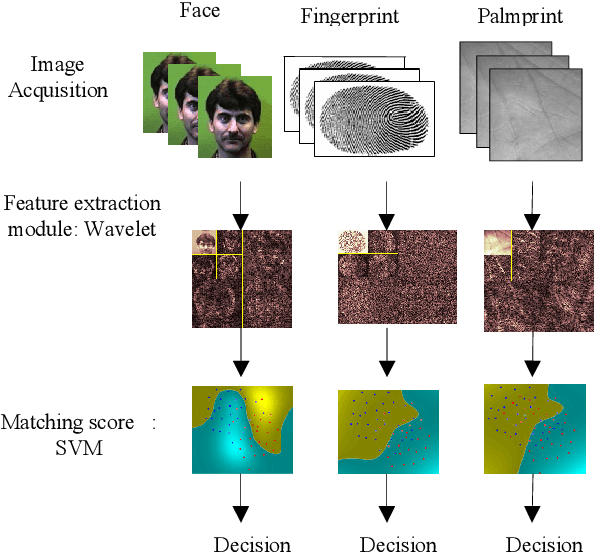
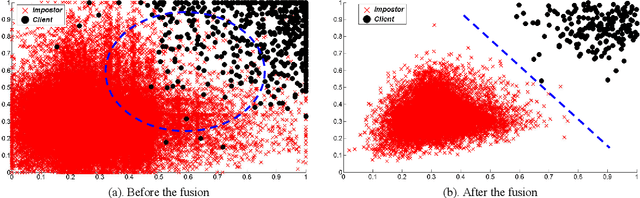
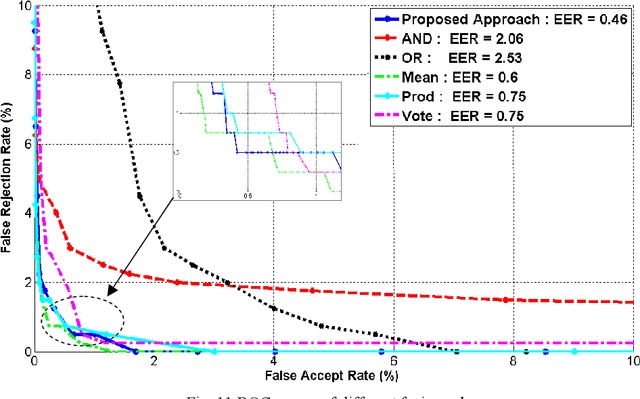
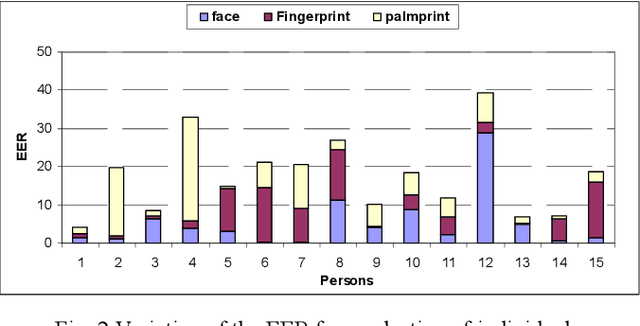
The Choquet integral is a tool for the information fusion that is very effective in the case where fuzzy measures associated with it are well chosen. In this paper,we propose a new approach for calculating fuzzy measures associated with the Choquet integral in a context of data fusion in multimodal biometrics. The proposed approach is based on genetic algorithms. It has been validated in two databases: the first base is relative to synthetic scores and the second one is biometrically relating to the face, fingerprintand palmprint. The results achieved attest the robustness of the proposed approach.
SMC Faster R-CNN: Toward a scene-specialized multi-object detector
Jun 30, 2017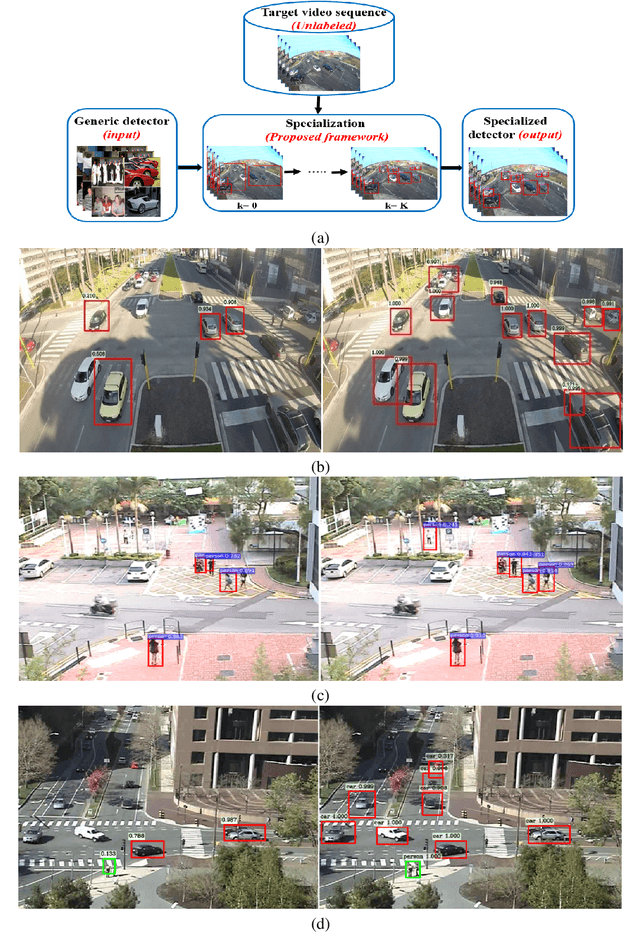

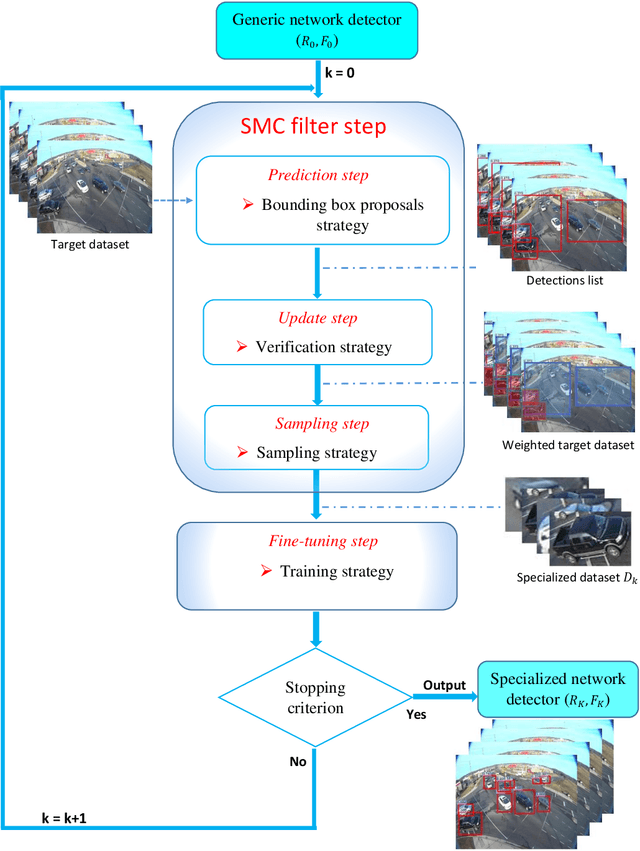
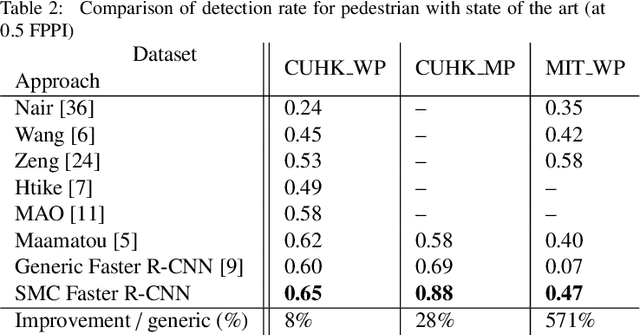
Generally, the performance of a generic detector decreases significantly when it is tested on a specific scene due to the large variation between the source training dataset and the samples from the target scene. To solve this problem, we propose a new formalism of transfer learning based on the theory of a Sequential Monte Carlo (SMC) filter to automatically specialize a scene-specific Faster R-CNN detector. The suggested framework uses different strategies based on the SMC filter steps to approximate iteratively the target distribution as a set of samples in order to specialize the Faster R-CNN detector towards a target scene. Moreover, we put forward a likelihood function that combines spatio-temporal information extracted from the target video sequence and the confidence-score given by the output layer of the Faster R-CNN, to favor the selection of target samples associated with the right label. The effectiveness of the suggested framework is demonstrated through experiments on several public traffic datasets. Compared with the state-of-the-art specialization frameworks, the proposed framework presents encouraging results for both single and multi-traffic object detections.
Dynamic Hierarchical Bayesian Network for Arabic Handwritten Word Recognition
May 20, 2014
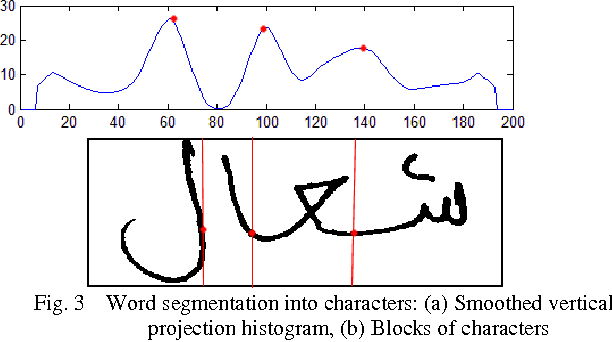

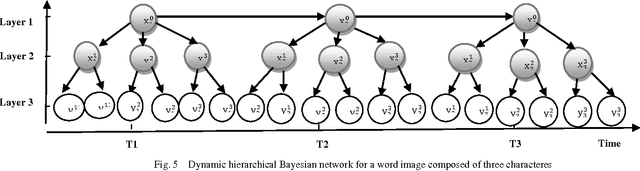
This paper presents a new probabilistic graphical model used to model and recognize words representing the names of Tunisian cities. In fact, this work is based on a dynamic hierarchical Bayesian network. The aim is to find the best model of Arabic handwriting to reduce the complexity of the recognition process by permitting the partial recognition. Actually, we propose a segmentation of the word based on smoothing the vertical histogram projection using different width values to reduce the error of segmentation. Then, we extract the characteristics of each cell using the Zernike and HU moments, which are invariant to rotation, translation and scaling. Our approach is tested using the IFN / ENIT database, and the experiment results are very promising.
Characterization of Dynamic Bayesian Network
Apr 07, 2012

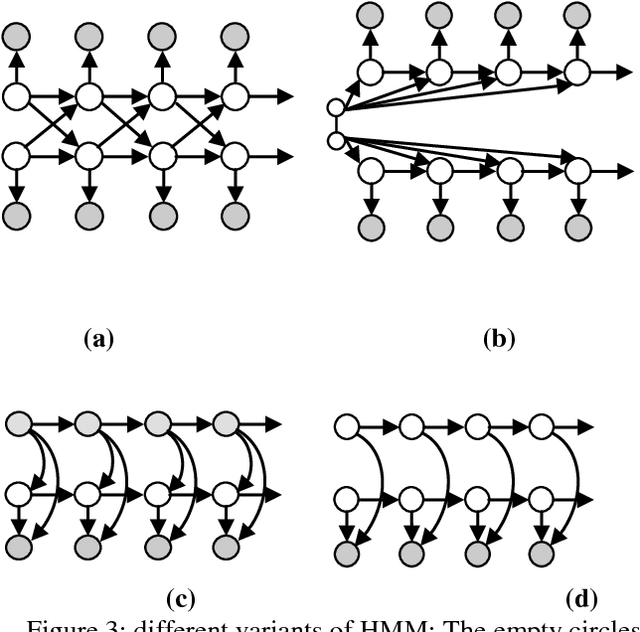

In this report, we will be interested at Dynamic Bayesian Network (DBNs) as a model that tries to incorporate temporal dimension with uncertainty. We start with basics of DBN where we especially focus in Inference and Learning concepts and algorithms. Then we will present different levels and methods of creating DBNs as well as approaches of incorporating temporal dimension in static Bayesian network.