 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-RoMa: From Pairwise Matching into Multi-View Track Reconstruction
Mar 29, 2026Establishing consistent correspondences across images is essential for 3D vision tasks such as structure-from-motion (SfM), yet most existing matchers operate in a pairwise manner, often producing fragmented and geometrically inconsistent tracks when their predictions are chained across views. We propose MV-RoMa, a multi-view dense matching model that jointly estimates dense correspondences from a source image to multiple co-visible targets. Specifically, we design an efficient model architecture which avoids high computational cost of full cross-attention for multi-view feature interaction: (i) multi-view encoder that leverages pair-wise matching results as a geometric prior, and (ii) multi-view matching refiner that refines correspondences using pixel-wise attention. Additionally, we propose a post-processing strategy that integrates our model's consistent multi-view correspondences as high-quality tracks for SfM. Across diverse and challenging benchmarks, MV-RoMa produces more reliable correspondences and substantially denser, more accurate 3D reconstructions than existing sparse and dense matching methods. Project page: https://icetea-cv.github.io/mv-roma/.
EntropyCache: Decoded Token Entropy Guided KV Caching for Diffusion Language Models
Mar 19, 2026Diffusion-based large language models (dLLMs) rely on bidirectional attention, which prevents lossless KV caching and requires a full forward pass at every denoising step. Existing approximate KV caching methods reduce this cost by selectively updating cached states, but their decision overhead scales with context length or model depth. We propose EntropyCache, a training-free KV caching method that uses the maximum entropy of newly decoded token distributions as a constant-cost signal for deciding when to recompute. Our design is grounded in two empirical observations: (1) decoded token entropy correlates with KV cache drift, providing a cheap proxy for cache staleness, and (2) feature volatility of decoded tokens persists for multiple steps after unmasking, motivating recomputation of the $k$ most recently decoded tokens. The skip-or-recompute decision requires only $O(V)$ computation per step, independent of context length and model scale. Experiments on LLaDA-8B-Instruct and Dream-7B-Instruct show that EntropyCache achieves $15.2\times$-$26.4\times$ speedup on standard benchmarks and $22.4\times$-$24.1\times$ on chain-of-thought benchmarks, with competitive accuracy and decision overhead accounting for only $0.5\%$ of inference time. Code is available at https://github.com/mscheong01/EntropyCache.
NSNQuant: A Double Normalization Approach for Calibration-Free Low-Bit Vector Quantization of KV Cache
May 23, 2025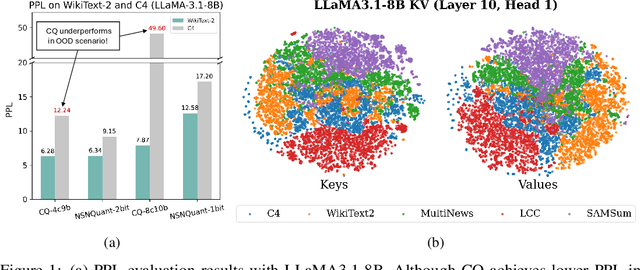



Large Language Model (LLM) inference is typically memory-intensive, especially when processing large batch sizes and long sequences, due to the large size of key-value (KV) cache. Vector Quantization (VQ) is recently adopted to alleviate this issue, but we find that the existing approach is susceptible to distribution shift due to its reliance on calibration datasets. To address this limitation, we introduce NSNQuant, a calibration-free Vector Quantization (VQ) technique designed for low-bit compression of the KV cache. By applying a three-step transformation-1) a token-wise normalization (Normalize), 2) a channel-wise centering (Shift), and 3) a second token-wise normalization (Normalize)-with Hadamard transform, NSNQuant effectively aligns the token distribution with the standard normal distribution. This alignment enables robust, calibration-free vector quantization using a single reusable codebook. Extensive experiments show that NSNQuant consistently outperforms prior methods in both 1-bit and 2-bit settings, offering strong generalization and up to 3$\times$ throughput gain over full-precision baselines.
Gaussian Weight Sampling for Scalable, Efficient and Stable Pseudo-Quantization Training
May 16, 2025



Ever-growing scale of large language models (LLMs) is pushing for improved efficiency, favoring fully quantized training (FQT) over BF16. While FQT accelerates training, it faces consistency challenges and requires searching over an exponential number of cases, each needing over 200B tokens to ensure stability. Pseudo-quantization training (PQT) addresses the issues of FQT, although it is not well-studied. We explore the practical implications of PQT in detail and propose a noise distribution $R$ that is floating-point (FP)-friendly, with ideal properties including stochastic precision annealing. As a result, the proposed method serves as an effective theoretical foundation for low-precision FP parameters through PQT, utilizing efficient fake quantization via an addition and subsequent FP casting. We demonstrate that Gaussian weight sampling is (1) scalable: supports low-precision FP parameters down to FP6 and high-precision noise up to 9-bit with BF16 operator. The proposed method is (2) efficient: incurring computational overhead as low as 1.40\% on the A100 GPU in terms of Llama2 training tokens per second, and requiring 2 bytes per parameter in GPU memory. We demonstrate that PQT with Gaussian weight sampling is (3) stable: closely following or even surpassing performance of the BF16 baseline while pre-training GPT2 and Llama2 models with up to 1B parameters and 300B tokens.
Grouped Sequency-arranged Rotation: Optimizing Rotation Transformation for Quantization for Free
May 02, 2025



Large Language Models (LLMs) face deployment challenges due to high computational costs, and while Post-Training Quantization (PTQ) offers a solution, existing rotation-based methods struggle at very low bit-widths like 2-bit. We introduce a novel, training-free approach to construct an improved rotation matrix, addressing the limitations of current methods. The key contributions include leveraging the Walsh-Hadamard transform with sequency ordering, which clusters similar frequency components to reduce quantization error compared to standard Hadamard matrices, significantly improving performance. Furthermore, we propose a Grouped Sequency-arranged Rotation (GSR) using block-diagonal matrices with smaller Walsh blocks, effectively isolating outlier impacts and achieving performance comparable to optimization-based methods without requiring any training. Our method demonstrates robust performance on reasoning tasks and Perplexity (PPL) score on WikiText-2. Our method also enhances results even when applied over existing learned rotation techniques.
Dense-SfM: Structure from Motion with Dense Consistent Matching
Jan 24, 2025



We present Dense-SfM, a novel Structure from Motion (SfM) framework designed for dense and accurate 3D reconstruction from multi-view images. Sparse keypoint matching, which traditional SfM methods often rely on, limits both accuracy and point density, especially in texture-less areas. Dense-SfM addresses this limitation by integrating dense matching with a Gaussian Splatting (GS) based track extension which gives more consistent, longer feature tracks. To further improve reconstruction accuracy, Dense-SfM is equipped with a multi-view kernelized matching module leveraging transformer and Gaussian Process architectures, for robust track refinement across multi-views. Evaluations on the ETH3D and Texture-Poor SfM datasets show that Dense-SfM offers significant improvements in accuracy and density over state-of-the-art methods.
Phys3DGS: Physically-based 3D Gaussian Splatting for Inverse Rendering
Sep 16, 2024

We propose two novel ideas (adoption of deferred rendering and mesh-based representation) to improve the quality of 3D Gaussian splatting (3DGS) based inverse rendering. We first report a problem incurred by hidden Gaussians, where Gaussians beneath the surface adversely affect the pixel color in the volume rendering adopted by the existing methods. In order to resolve the problem, we propose applying deferred rendering and report new problems incurred in a naive application of deferred rendering to the existing 3DGS-based inverse rendering. In an effort to improve the quality of 3DGS-based inverse rendering under deferred rendering, we propose a novel two-step training approach which (1) exploits mesh extraction and utilizes a hybrid mesh-3DGS representation and (2) applies novel regularization methods to better exploit the mesh. Our experiments show that, under relighting, the proposed method offers significantly better rendering quality than the existing 3DGS-based inverse rendering methods. Compared with the SOTA voxel grid-based inverse rendering method, it gives better rendering quality while offering real-time rendering.
Baking Relightable NeRF for Real-time Direct/Indirect Illumination Rendering
Sep 16, 2024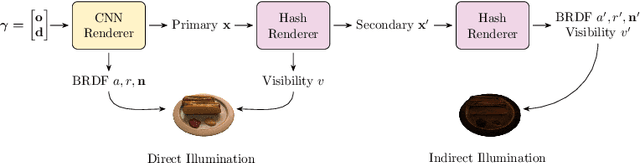
Relighting, which synthesizes a novel view under a given lighting condition (unseen in training time), is a must feature for immersive photo-realistic experience. However, real-time relighting is challenging due to high computation cost of the rendering equation which requires shape and material decomposition and visibility test to model shadow. Additionally, for indirect illumination, additional computation of rendering equation on each secondary surface point (where reflection occurs) is required rendering real-time relighting challenging. We propose a novel method that executes a CNN renderer to compute primary surface points and rendering parameters, required for direct illumination. We also present a lightweight hash grid-based renderer, for indirect illumination, which is recursively executed to perform the secondary ray tracing process. Both renderers are trained in a distillation from a pre-trained teacher model and provide real-time physically-based rendering under unseen lighting condition at a negligible loss of rendering quality.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024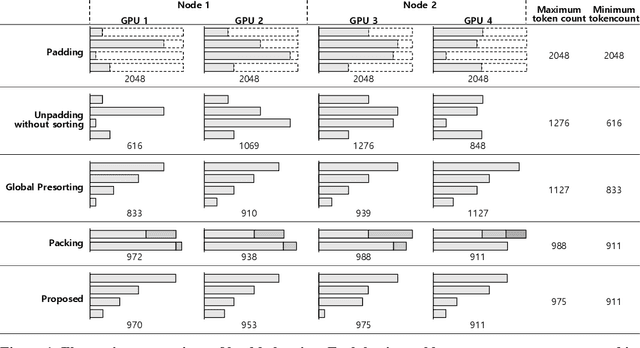
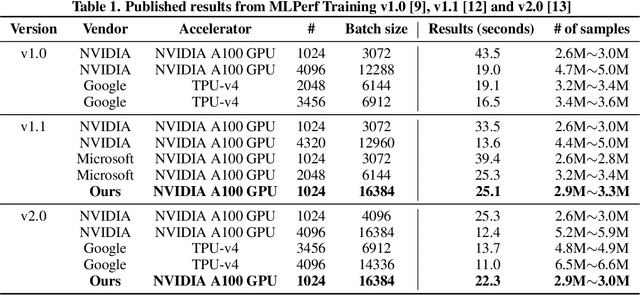
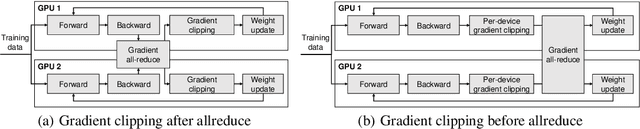
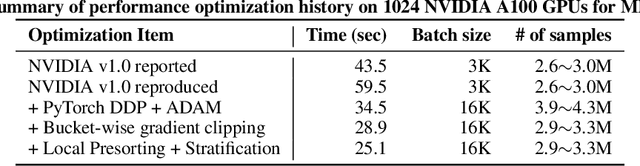
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.
Geometry Transfer for Stylizing Radiance Fields
Feb 02, 2024Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.