 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaMix: Meta-state Precision Searcher for Mixed-precision Activation Quantization
Nov 12, 2023


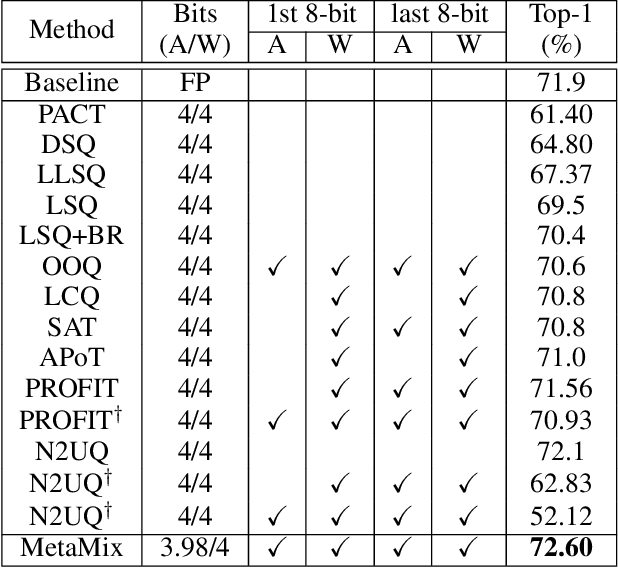
Mixed-precision quantization of efficient networks often suffer from activation instability encountered in the exploration of bit selections. To address this problem, we propose a novel method called MetaMix which consists of bit selection and weight training phases. The bit selection phase iterates two steps, (1) the mixed-precision-aware weight update, and (2) the bit-search training with the fixed mixed-precision-aware weights, both of which combined reduce activation instability in mixed-precision quantization and contribute to fast and high-quality bit selection. The weight training phase exploits the weights and step sizes trained in the bit selection phase and fine-tunes them thereby offering fast training. Our experiments with efficient and hard-to-quantize networks, i.e., MobileNet v2 and v3, and ResNet-18 on ImageNet show that our proposed method pushes the boundary of mixed-precision quantization, in terms of accuracy vs. operations, by outperforming both mixed- and single-precision SOTA methods.
JaxPruner: A concise library for sparsity research
May 02, 2023


This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation
Apr 10, 2023Video Panoptic Segmentation (VPS) aims to achieve comprehensive pixel-level scene understanding by segmenting all pixels and associating objects in a video. Current solutions can be categorized into online and near-online approaches. Evolving over the time, each category has its own specialized designs, making it nontrivial to adapt models between different categories. To alleviate the discrepancy, in this work, we propose a unified approach for online and near-online VPS. The meta architecture of the proposed Video-kMaX consists of two components: within clip segmenter (for clip-level segmentation) and cross-clip associater (for association beyond clips). We propose clip-kMaX (clip k-means mask transformer) and HiLA-MB (Hierarchical Location-Aware Memory Buffer) to instantiate the segmenter and associater, respectively. Our general formulation includes the online scenario as a special case by adopting clip length of one. Without bells and whistles, Video-kMaX sets a new state-of-the-art on KITTI-STEP and VIPSeg for video panoptic segmentation, and VSPW for video semantic segmentation. Code will be made publicly available.
TubeFormer-DeepLab: Video Mask Transformer
May 30, 2022



We present TubeFormer-DeepLab, the first attempt to tackle multiple core video segmentation tasks in a unified manner. Different video segmentation tasks (e.g., video semantic/instance/panoptic segmentation) are usually considered as distinct problems. State-of-the-art models adopted in the separate communities have diverged, and radically different approaches dominate in each task. By contrast, we make a crucial observation that video segmentation tasks could be generally formulated as the problem of assigning different predicted labels to video tubes (where a tube is obtained by linking segmentation masks along the time axis) and the labels may encode different values depending on the target task. The observation motivates us to develop TubeFormer-DeepLab, a simple and effective video mask transformer model that is widely applicable to multiple video segmentation tasks. TubeFormer-DeepLab directly predicts video tubes with task-specific labels (either pure semantic categories, or both semantic categories and instance identities), which not only significantly simplifies video segmentation models, but also advances state-of-the-art results on multiple video segmentation benchmarks
NNStreamer: Stream Processing Paradigm for Neural Networks, Toward Efficient Development and Execution of On-Device AI Applications
Jan 12, 2019

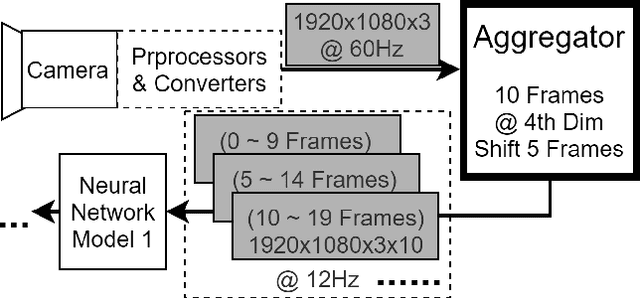
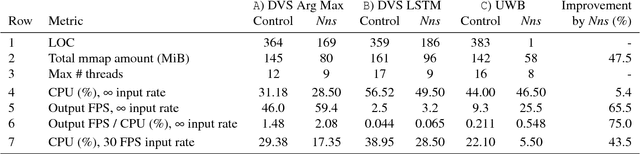
We propose nnstreamer, a software system that handles neural networks as filters of stream pipelines, applying the stream processing paradigm to neural network applications. A new trend with the wide-spread of deep neural network applications is on-device AI; i.e., processing neural networks directly on mobile devices or edge/IoT devices instead of cloud servers. Emerging privacy issues, data transmission costs, and operational costs signifies the need for on-device AI especially when a huge number of devices with real-time data processing are deployed. Nnstreamer efficiently handles neural networks with complex data stream pipelines on devices, improving the overall performance significantly with minimal efforts. Besides, nnstreamer simplifies the neural network pipeline implementations and allows reusing off-shelf multimedia stream filters directly; thus it reduces the developmental costs significantly. Nnstreamer is already being deployed with a product releasing soon and is open source software applicable to a wide range of hardware architectures and software platforms.