 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPoseFormer v2: Accurate Egocentric Human Motion Estimation for AR/VR
Mar 04, 2026Egocentric human motion estimation is essential for AR/VR experiences, yet remains challenging due to limited body coverage from the egocentric viewpoint, frequent occlusions, and scarce labeled data. We present EgoPoseFormer v2, a method that addresses these challenges through two key contributions: (1) a transformer-based model for temporally consistent and spatially grounded body pose estimation, and (2) an auto-labeling system that enables the use of large unlabeled datasets for training. Our model is fully differentiable, introduces identity-conditioned queries, multi-view spatial refinement, causal temporal attention, and supports both keypoints and parametric body representations under a constant compute budget. The auto-labeling system scales learning to tens of millions of unlabeled frames via uncertainty-aware semi-supervised training. The system follows a teacher-student schema to generate pseudo-labels and guide training with uncertainty distillation, enabling the model to generalize to different environments. On the EgoBody3M benchmark, with a 0.8 ms latency on GPU, our model outperforms two state-of-the-art methods by 12.2% and 19.4% in accuracy, and reduces temporal jitter by 22.2% and 51.7%. Furthermore, our auto-labeling system further improves the wrist MPJPE by 13.1%.
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022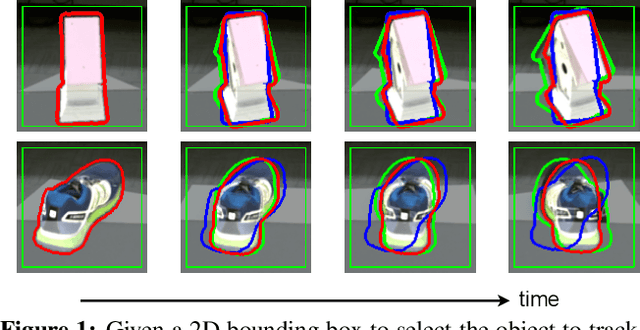
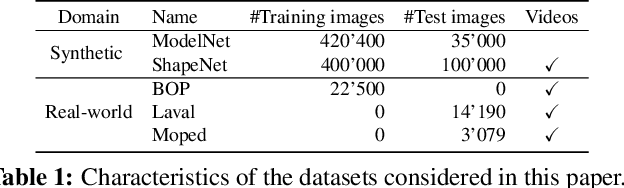
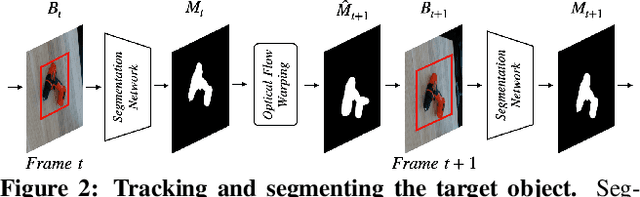
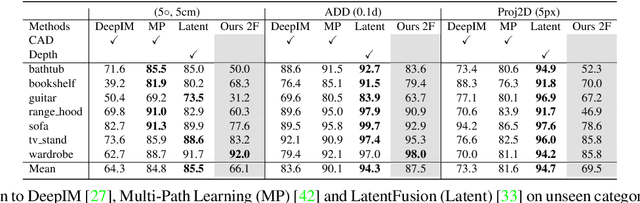
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza
SparseFormer: Attention-based Depth Completion Network
Jun 09, 2022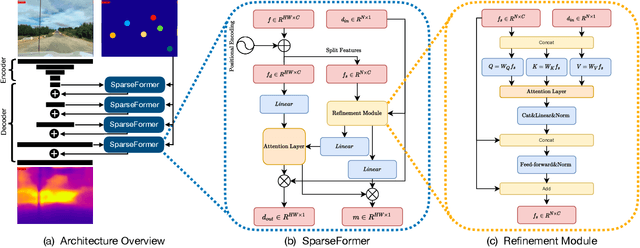
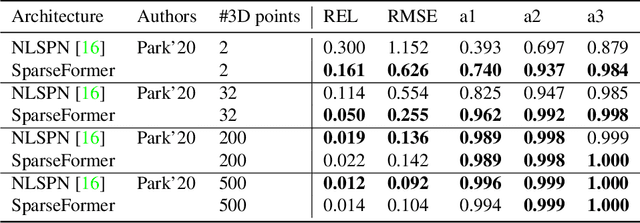

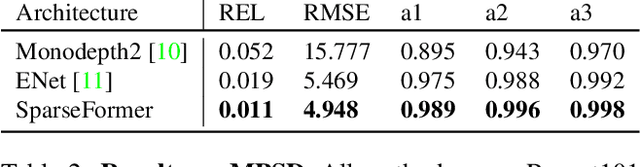
Most pipelines for Augmented and Virtual Reality estimate the ego-motion of the camera by creating a map of sparse 3D landmarks. In this paper, we tackle the problem of depth completion, that is, densifying this sparse 3D map using RGB images as guidance. This remains a challenging problem due to the low density, non-uniform and outlier-prone 3D landmarks produced by SfM and SLAM pipelines. We introduce a transformer block, SparseFormer, that fuses 3D landmarks with deep visual features to produce dense depth. The SparseFormer has a global receptive field, making the module especially effective for depth completion with low-density and non-uniform landmarks. To address the issue of depth outliers among the 3D landmarks, we introduce a trainable refinement module that filters outliers through attention between the sparse landmarks.
Predicting Sharp and Accurate Occlusion Boundaries in Monocular Depth Estimation Using Displacement Fields
Feb 28, 2020
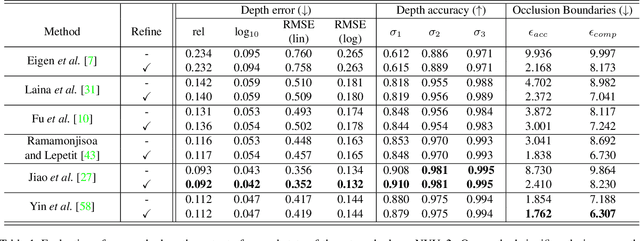

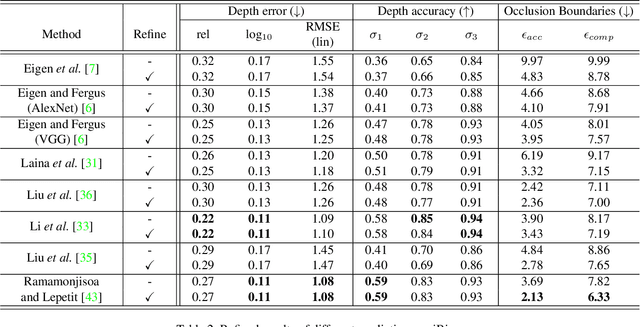
Current methods for depth map prediction from monocular images tend to predict smooth, poorly localized contours for the occlusion boundaries in the input image. This is unfortunate as occlusion boundaries are important cues to recognize objects, and as we show, may lead to a way to discover new objects from scene reconstruction. To improve predicted depth maps, recent methods rely on various forms of filtering or predict an additive residual depth map to refine a first estimate. We instead learn to predict, given a depth map predicted by some reconstruction method, a 2D displacement field able to re-sample pixels around the occlusion boundaries into sharper reconstructions. Our method can be applied to the output of any depth estimation method, in an end-to-end trainable fashion. For evaluation, we manually annotated the occlusion boundaries in all the images in the test split of popular NYUv2-Depth dataset. We show that our approach improves the localization of occlusion boundaries for all state-of-the-art monocular depth estimation methods that we could evaluate, without degrading the depth accuracy for the rest of the images.