 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseFormer: Attention-based Depth Completion Network
Paper and Code
Jun 09, 2022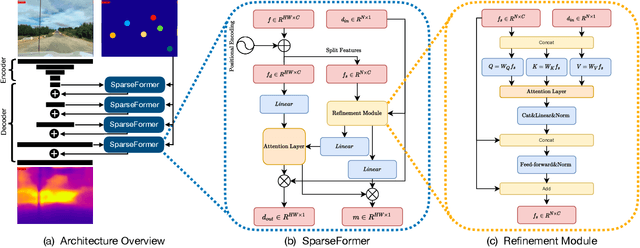
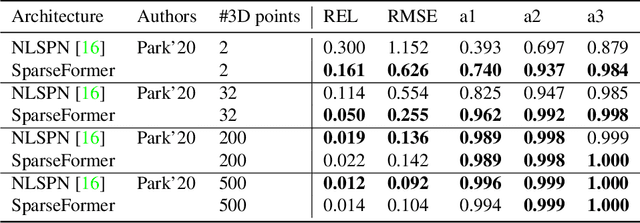

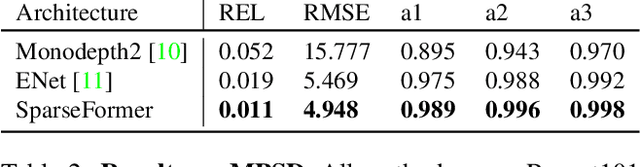
Most pipelines for Augmented and Virtual Reality estimate the ego-motion of the camera by creating a map of sparse 3D landmarks. In this paper, we tackle the problem of depth completion, that is, densifying this sparse 3D map using RGB images as guidance. This remains a challenging problem due to the low density, non-uniform and outlier-prone 3D landmarks produced by SfM and SLAM pipelines. We introduce a transformer block, SparseFormer, that fuses 3D landmarks with deep visual features to produce dense depth. The SparseFormer has a global receptive field, making the module especially effective for depth completion with low-density and non-uniform landmarks. To address the issue of depth outliers among the 3D landmarks, we introduce a trainable refinement module that filters outliers through attention between the sparse landmarks.